

Valitsuse iganädalane pressikonverents on moment, kus peaminister ning valitud ministrid annavad ülevaate oma tegevusest. Kuigi kommunikatsioonikanaleid avalikkusega on teisigi, eriti sotsiaalmeediaajastul, on see siiski üks peamine moment, kus valitsus kõnetab avalikkust. Valitsuse pressikonverentside sisu võiks olla hea läbilõige valitsuse tegevusest, valitsusele olulistest teemadest ja nende muutumisest läbi aja.
Stenbocki maja koduleheküljel on olemas valitsuste pressikonverentside stenogrammid alates praegusest kuni sügiseni aastal 2003. Nende sisu on sealt üpriski hõlpsast alla laetav ning pärast mõningast puhastamist ja struktureerimist ka analüüsitav. Siinkohal on analüüsitud kõiki stenogramme kuni Jüri Ratse teise valitsuse lõpuni 2021. aasta alguses. Puhastatud stenogrammid koos mõningase lisainformatsiooniga kõnelejate kohta on saadaval siin.
Kuigi ligi 900 stenogrammi oleks ka nö kvalitatiivselt analüüsitav – st. oleks võimalik kõik need tekstid läbi lugeda ning teha üldistusi ja järeldusi taolise läbitöötamise põhjal, on siinkohal kasutatud nendest esmase ülevaate andmiseks tekstilistele andmetele keskendunud masinõppemeetodeid, mis on suutelised võrdlemisi kiiresti töötlema ka palju suuremaid tekstihulkasid. Ning mitte ainult töötlema, vaid ka sisuliselt analüüsima.
Stenogrammide esmaseks analüüsiks on kasutatud kahte meetodit, mis üldiselt langevad nimetuse alla “teemade modelleerimine”, ning mille eesmärk on tekstidest tuvastada koos kasutatavaid sõnu, mis moodustavad semantilisi tervikuid, ning tuvastama selliste teemade esinemist analüüsitud dokumentides. Esimene neist on “struktuurne teemade modelleerimine”, mis tugineb sõnade koosesinemisel dokumentides (vaata siit). Teine mudel on “top2vec” (vaata siit), mis loob sõnade ja dokumentide representatsiooni kõrge-mõõtmelises ruumis nende omavaheliste tähenduslike seoste kuvamiseks ning läbi selle saavutab sama eesmärgi – tuvastab semantiliselt kokku kuuluvaid sõnu ehk teemasid ning määrab taoliste teemade esinemissageduse dokumentides.
Need on kaks üpriski erineva mehhaanikaga meetodit, mis peaksid täitma sama eesmärki ning andma sarnase tulemuse. Ehk siis ennekõike tuvastama teemad, mis analüüsitud tekstikorpuses esinevad. Kui ära kasutada täiendavat informatsiooni, mis meil on tekstide kohta – näiteks nende aeg, kõneleja erakondlik kuuluvus ja valitsus, mis parajasti ametis oli – saame luua juba palju põhjalikuma pildi sellest, millest meie valitsused on ligi 20 aasta jooksul rääkinud, mis teemad on tõusnud ja langenud ning millal ja millised on teemad, mis väga selgelt kuuluvad ühele või teisele erakonnale.
Tuvastatavate teemade arv ei ole statistiliselt paika pandud, see sõltub paljuski analüütiku suvast. Peamine, mis sellest arvust sõltub, on tuvastatud teemade detailsus ja tähenduslikkus. Kui me palume mudelil leida väike arv teemasid, siis leiab ta meile väga üldised teemad, kus erinevad konkreetsed küsimused on tihti läbisegi. Kui me palume leida suurema arvu teemasid, siis on need konkreetsemad, kuid tõenäosus, et mudel tuvastab ka semantiliselt tähendusetuid teemasid, suureneb.
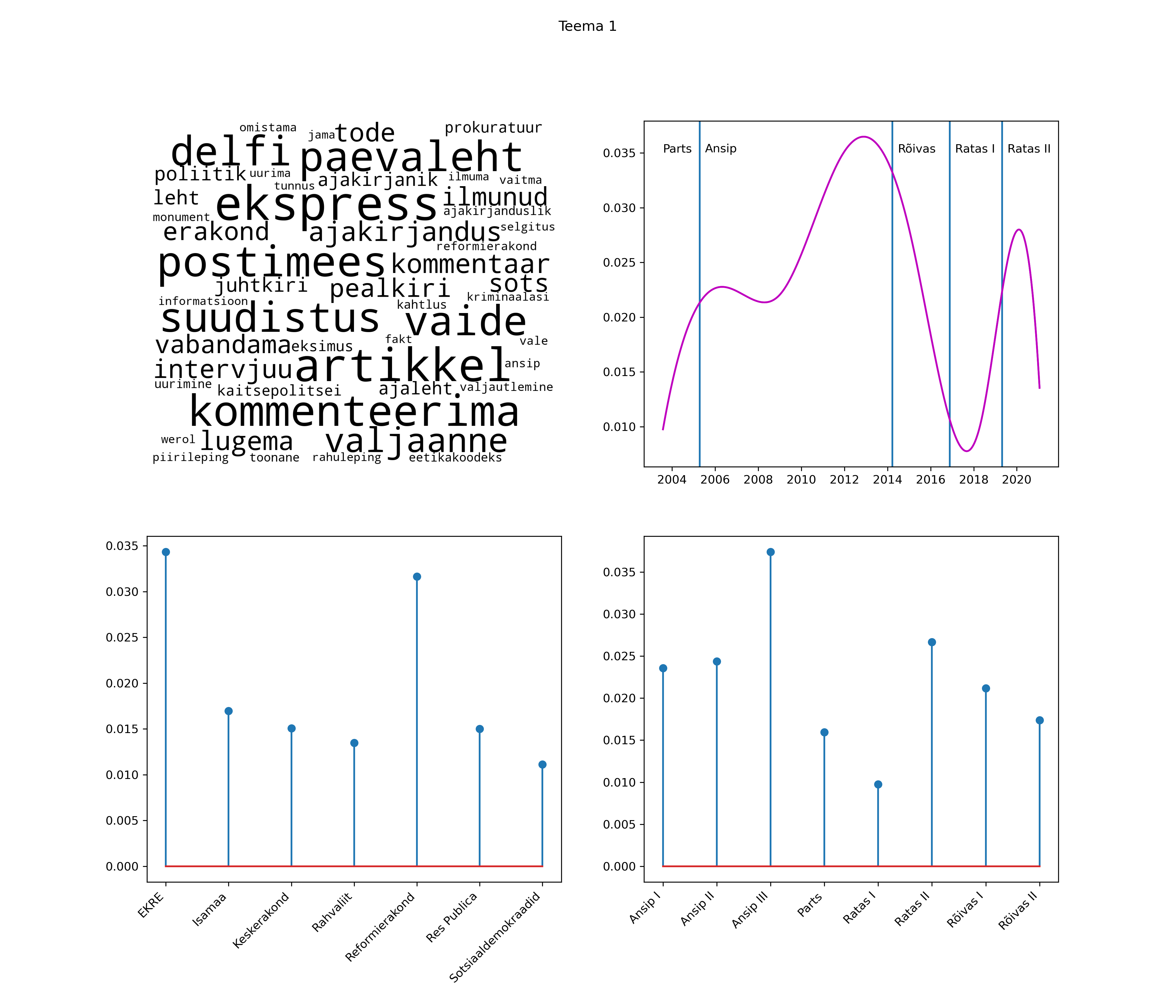
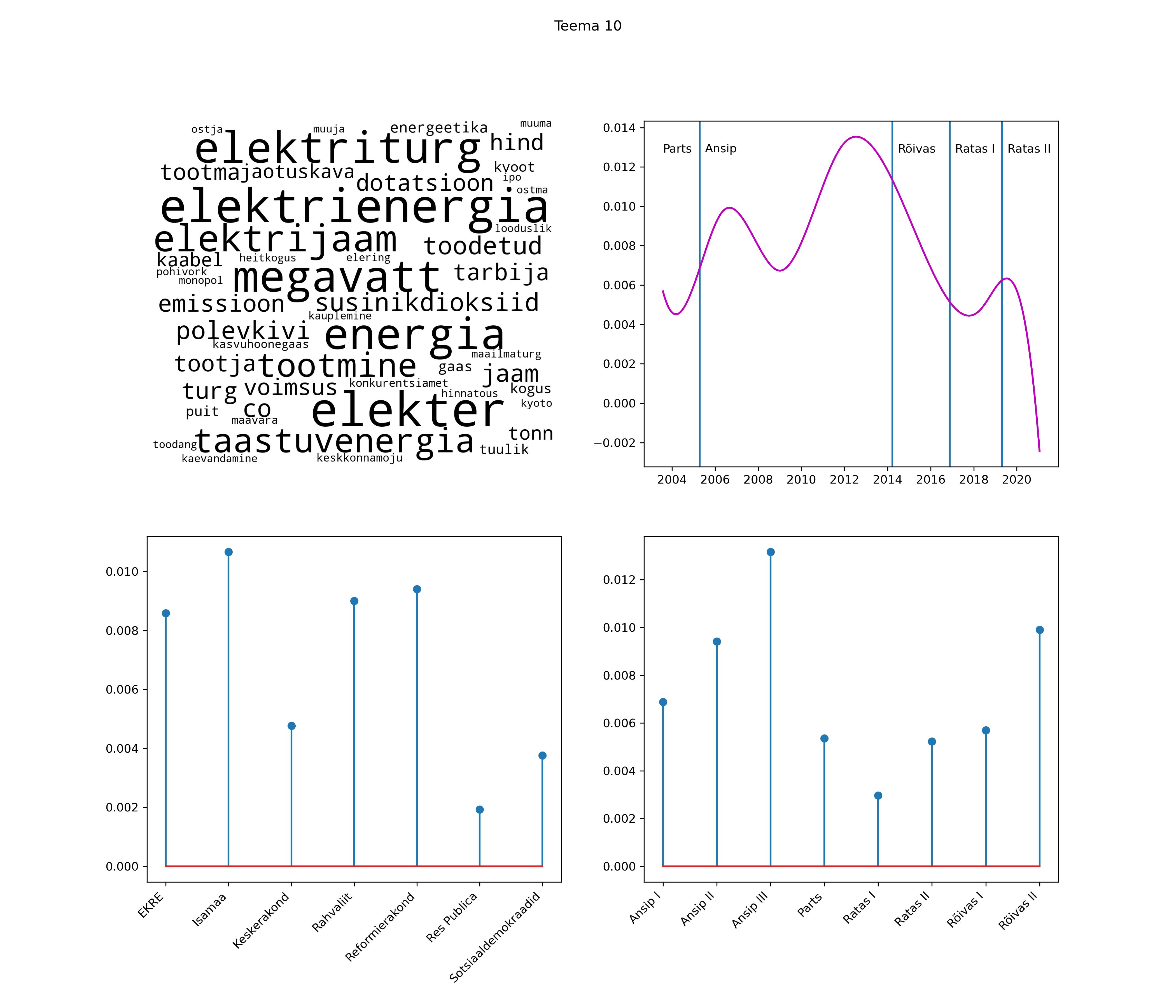
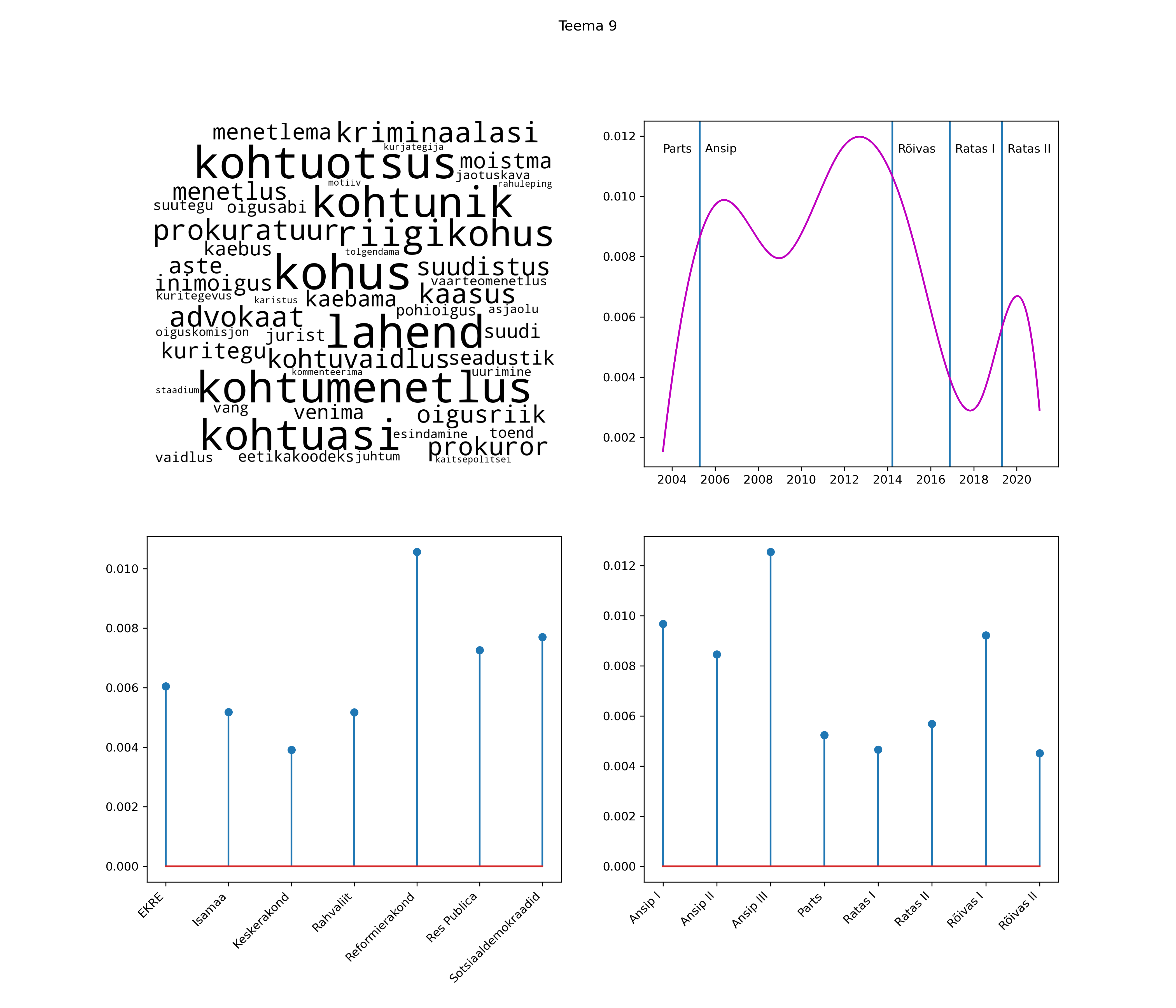
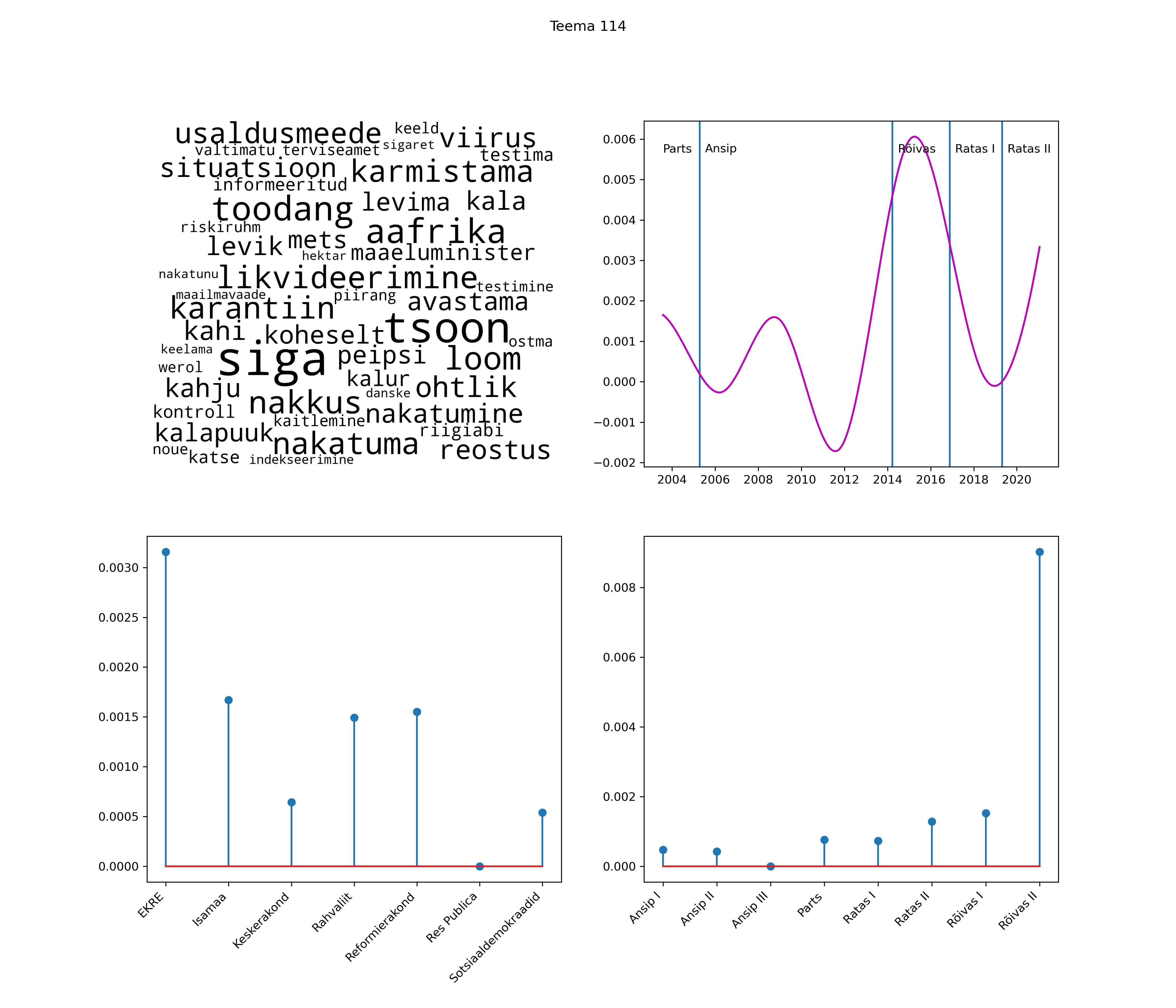
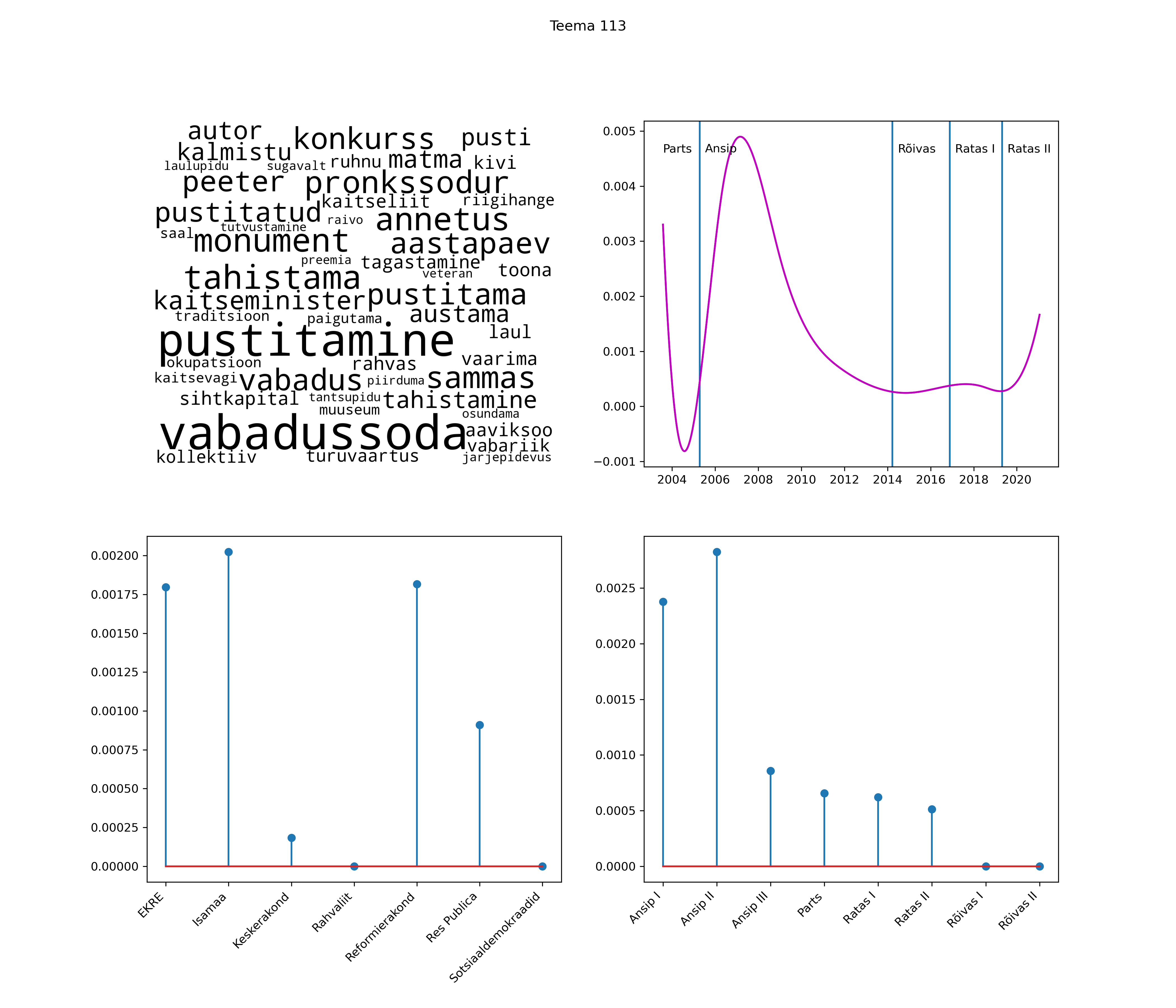
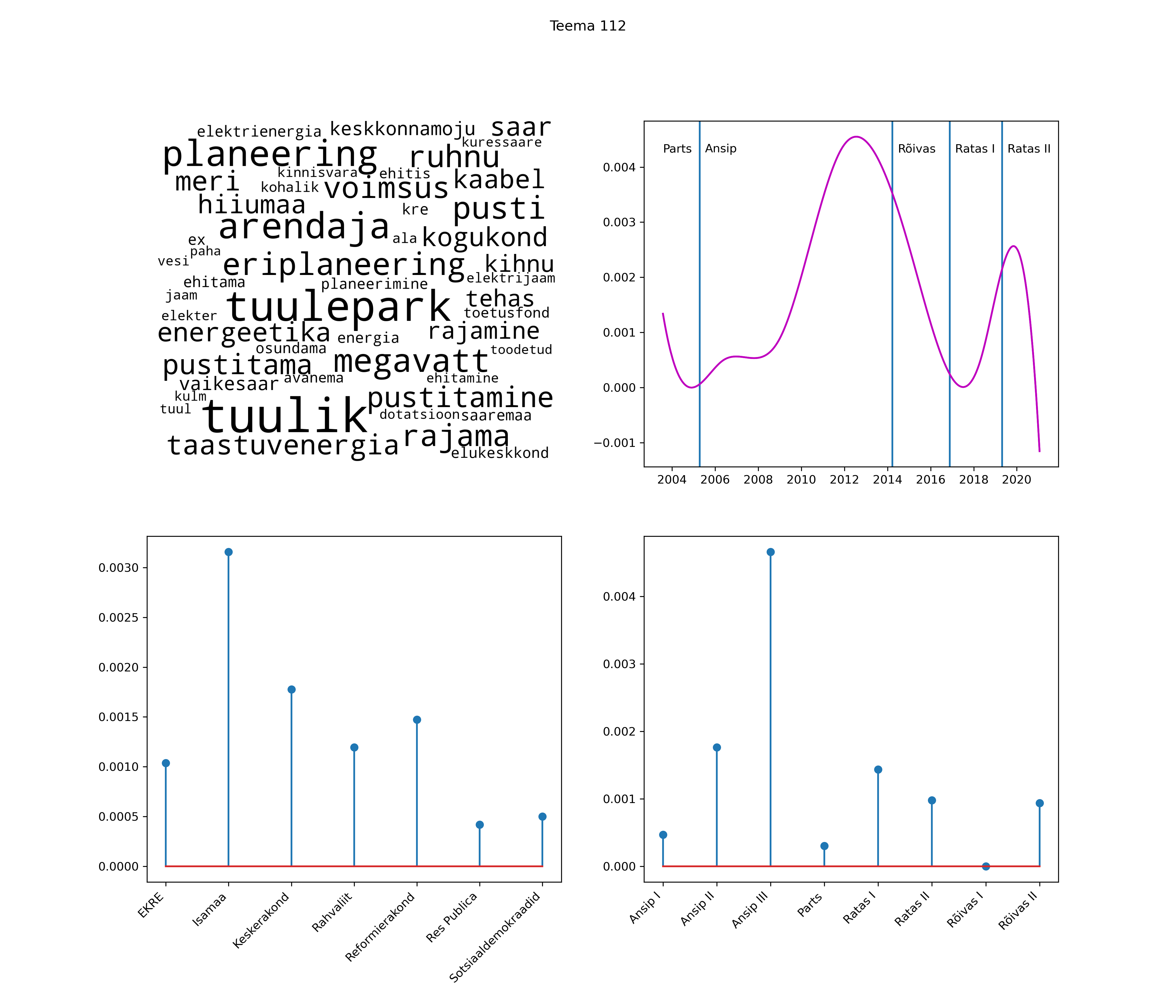
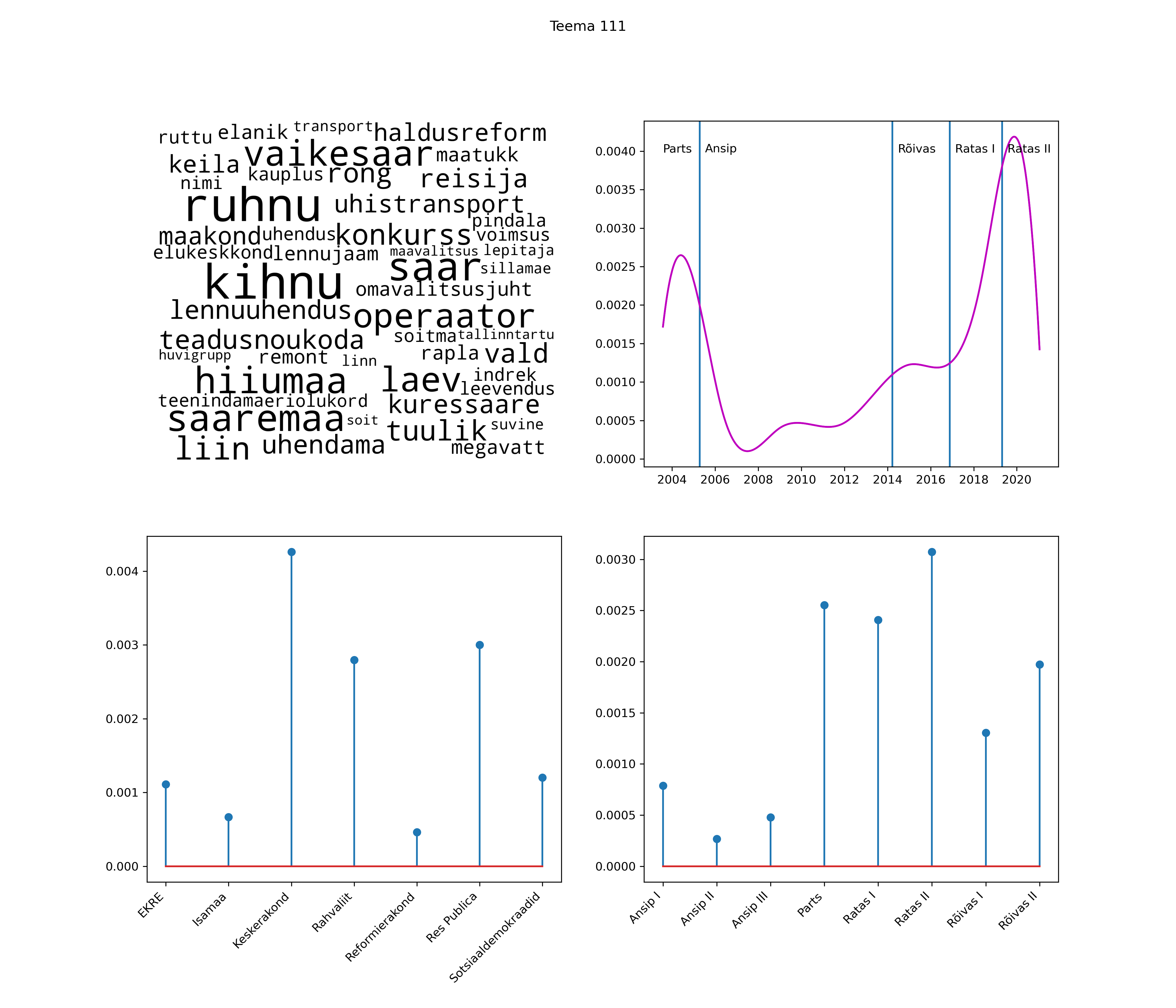
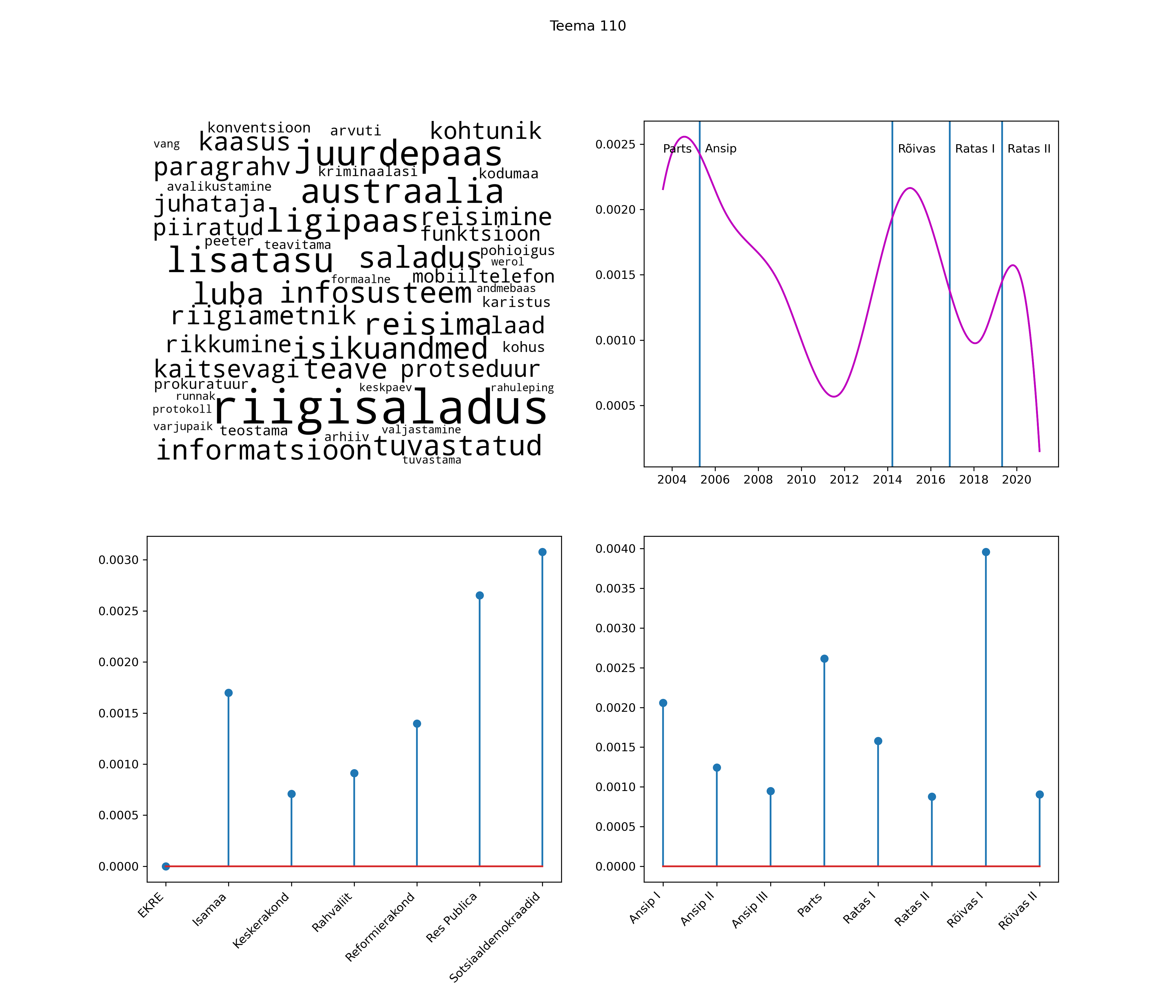
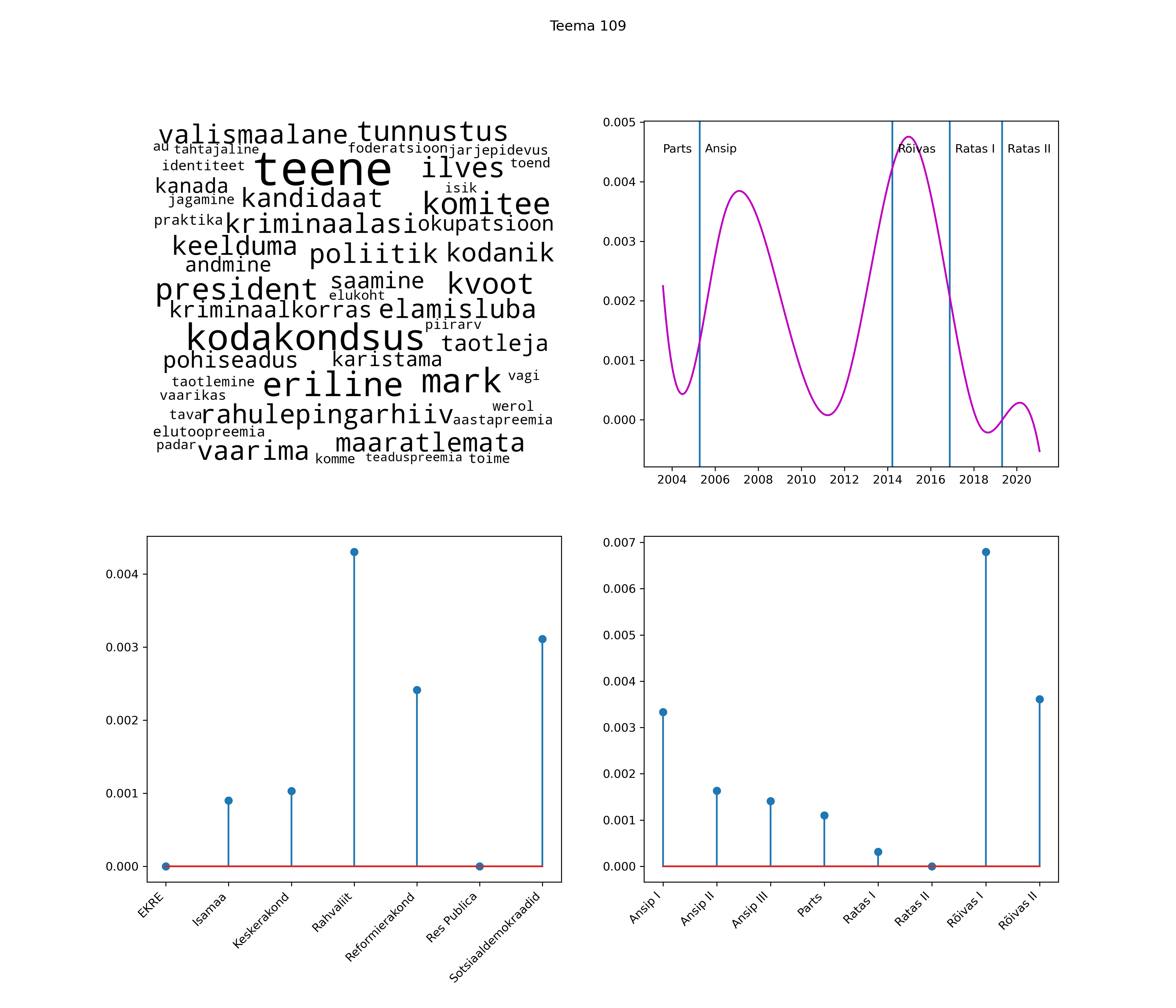
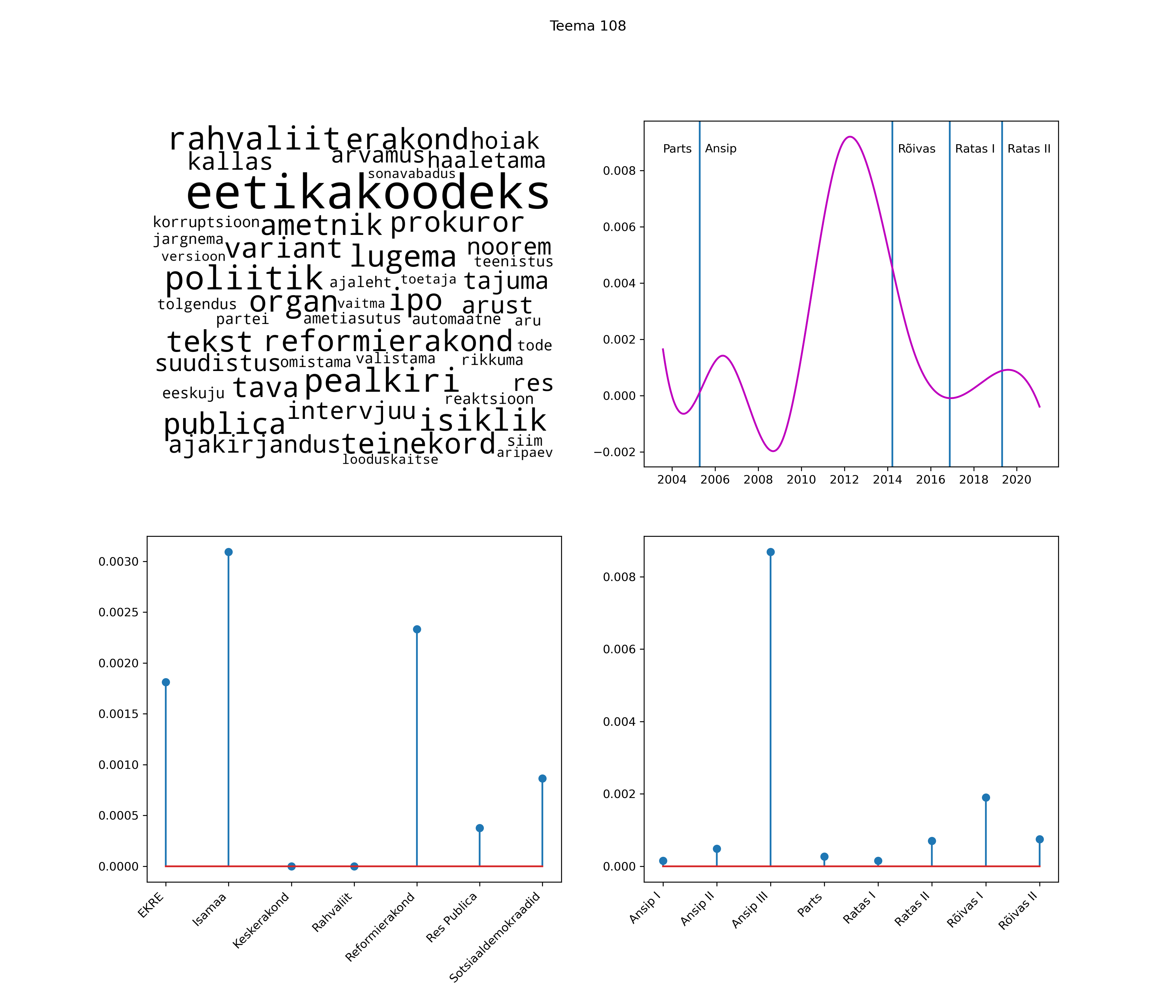
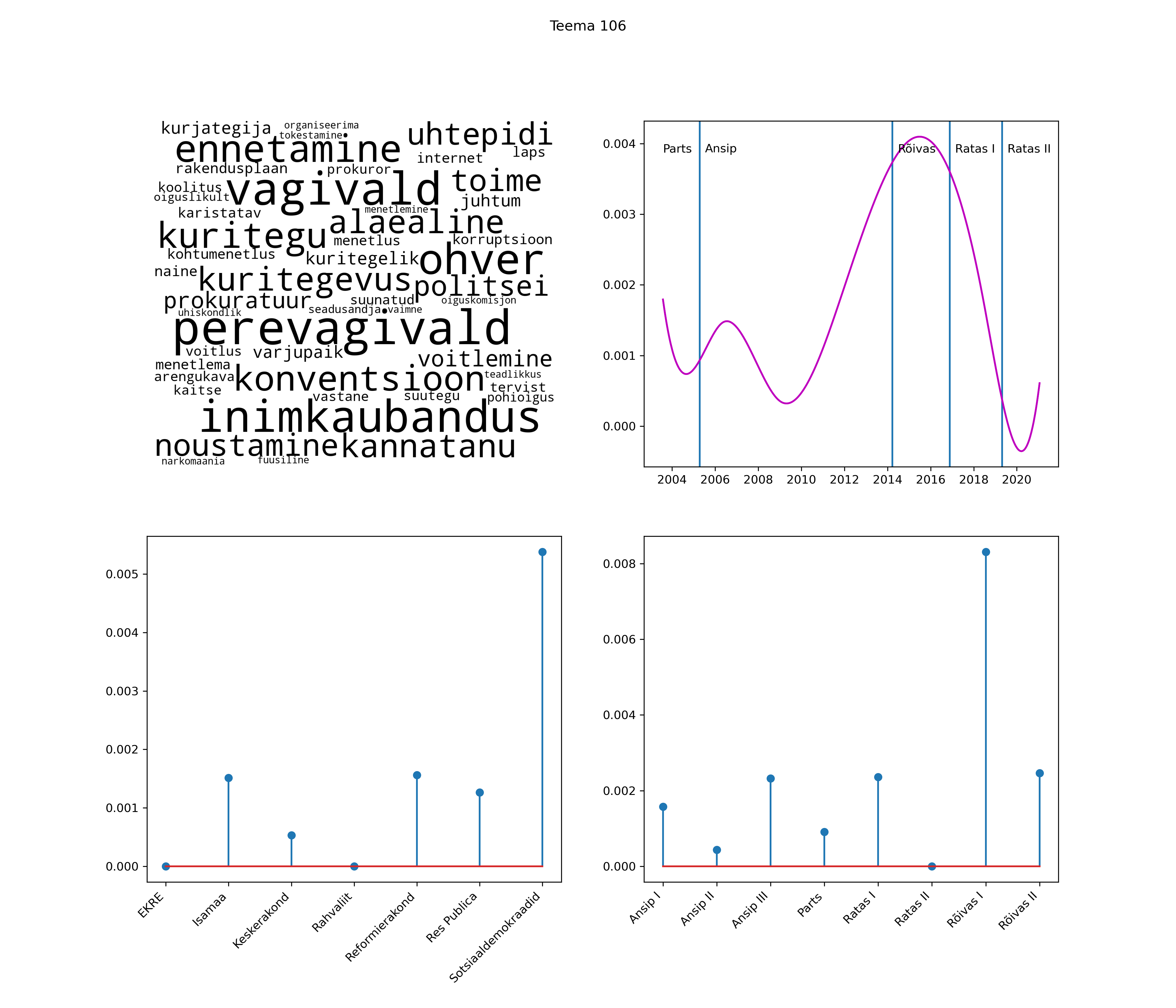
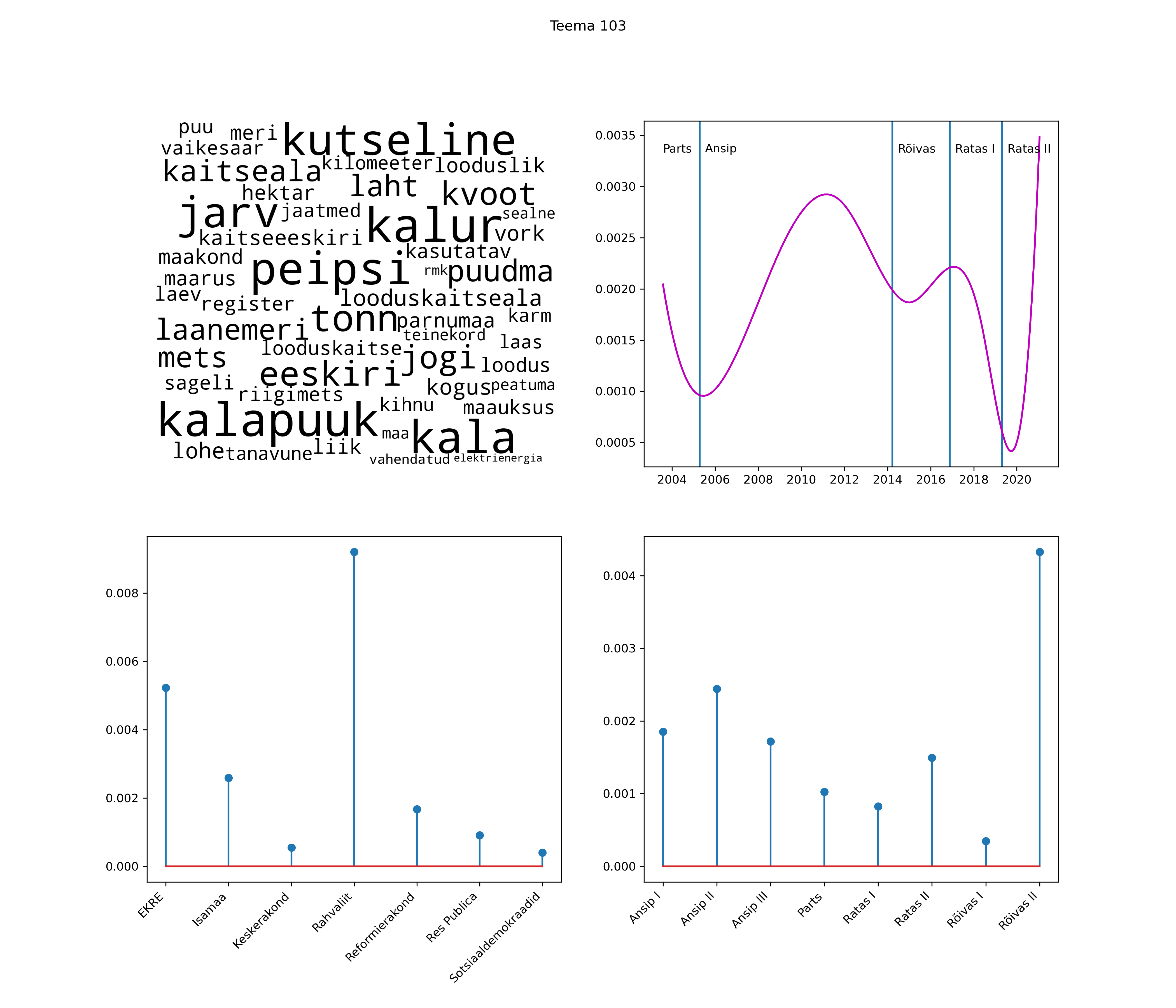
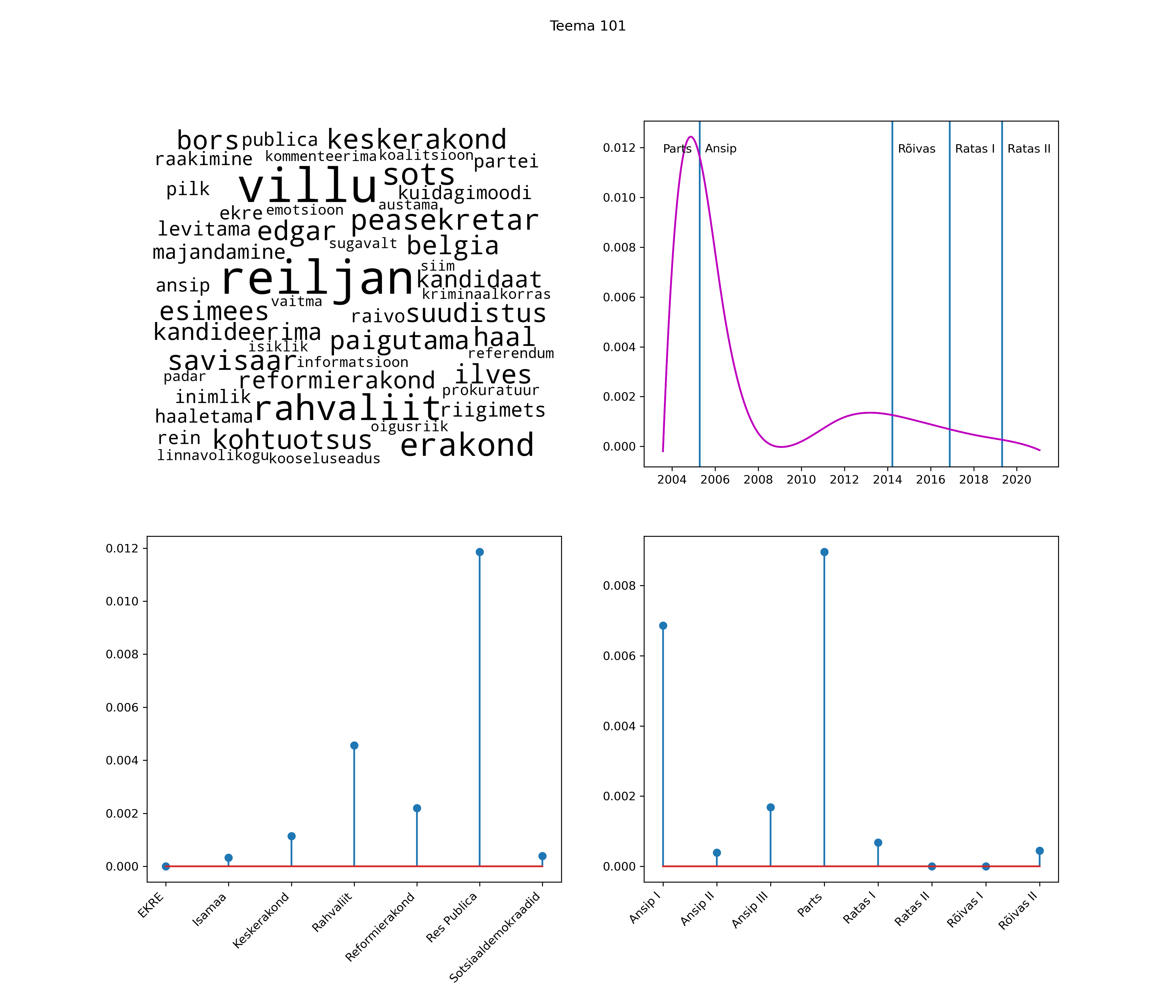
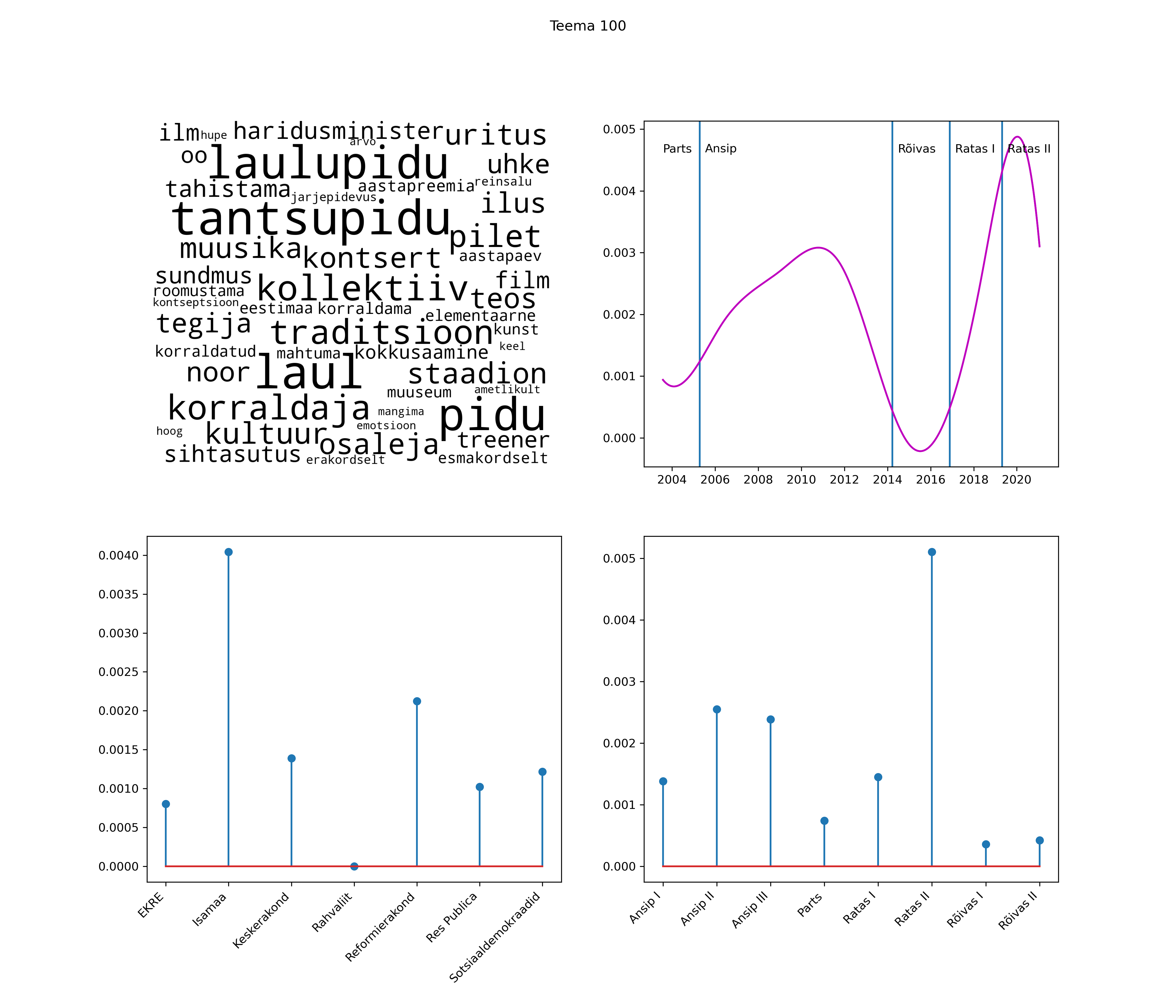
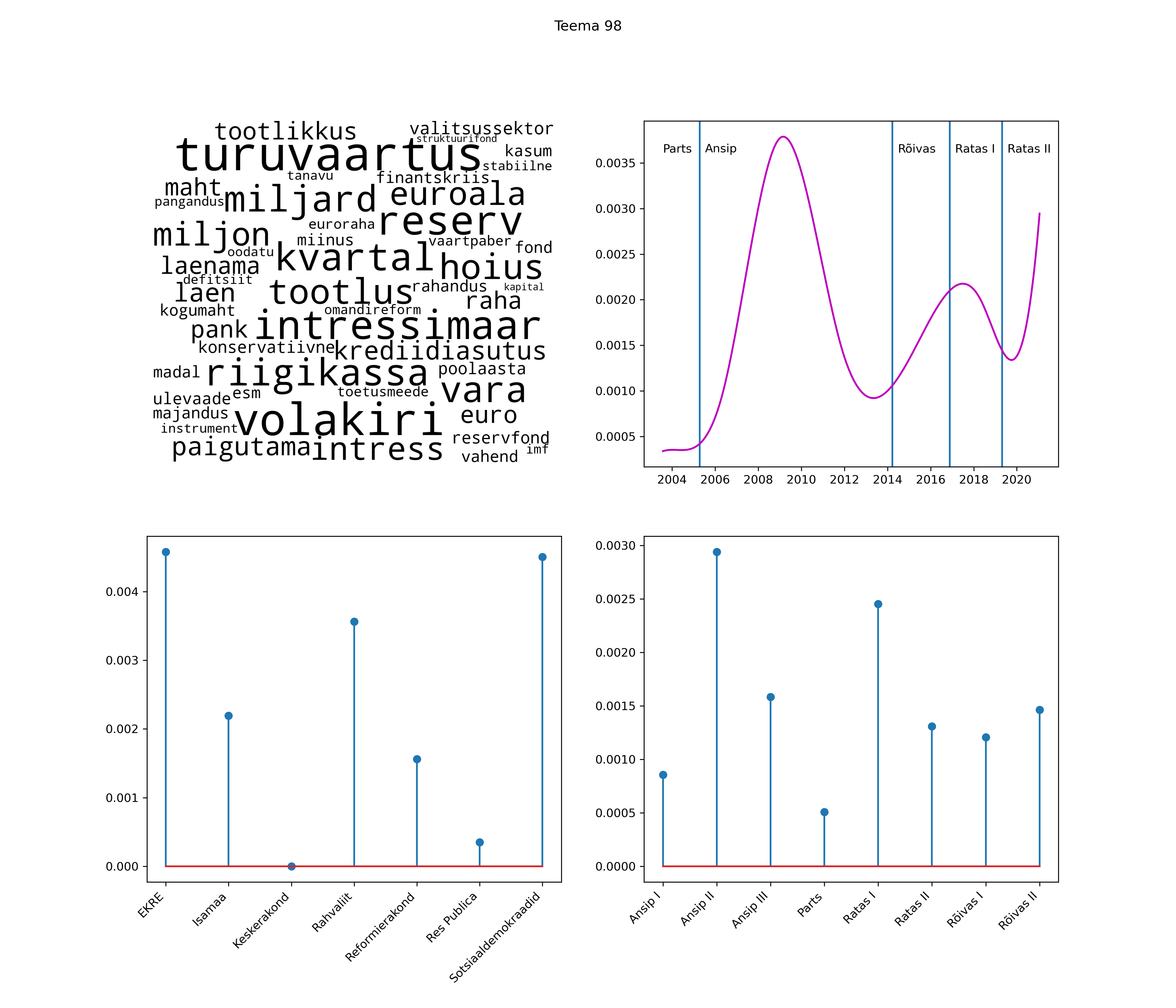
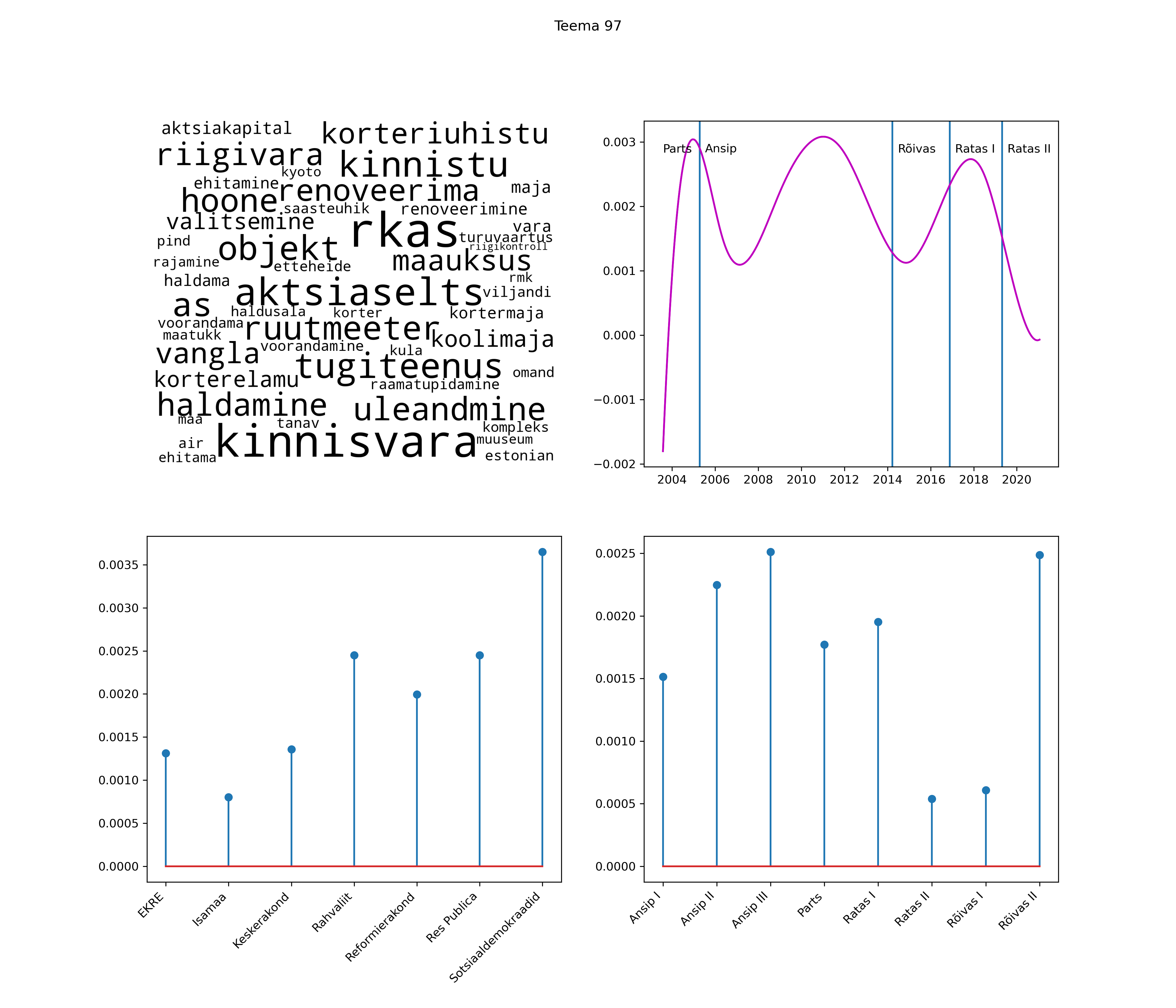
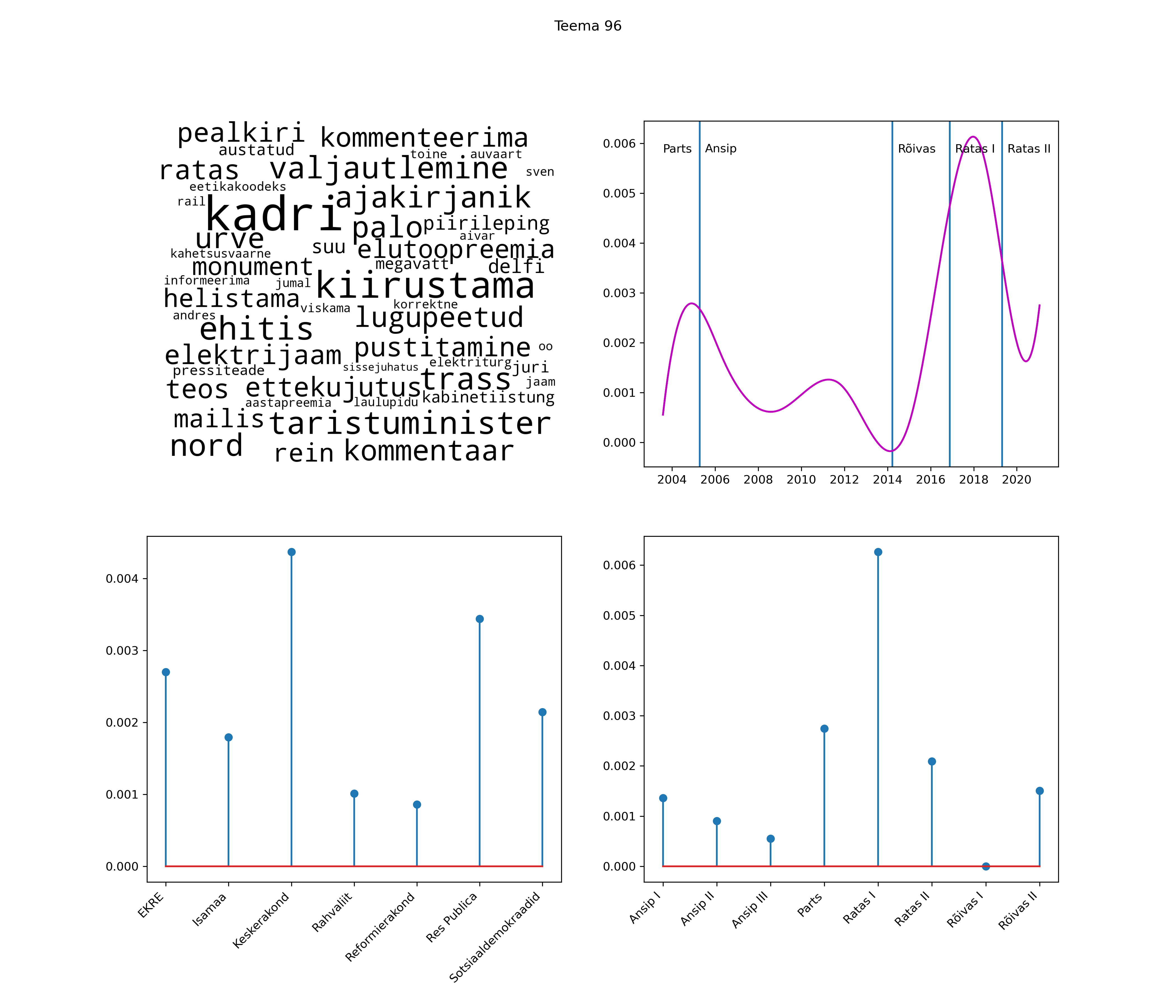
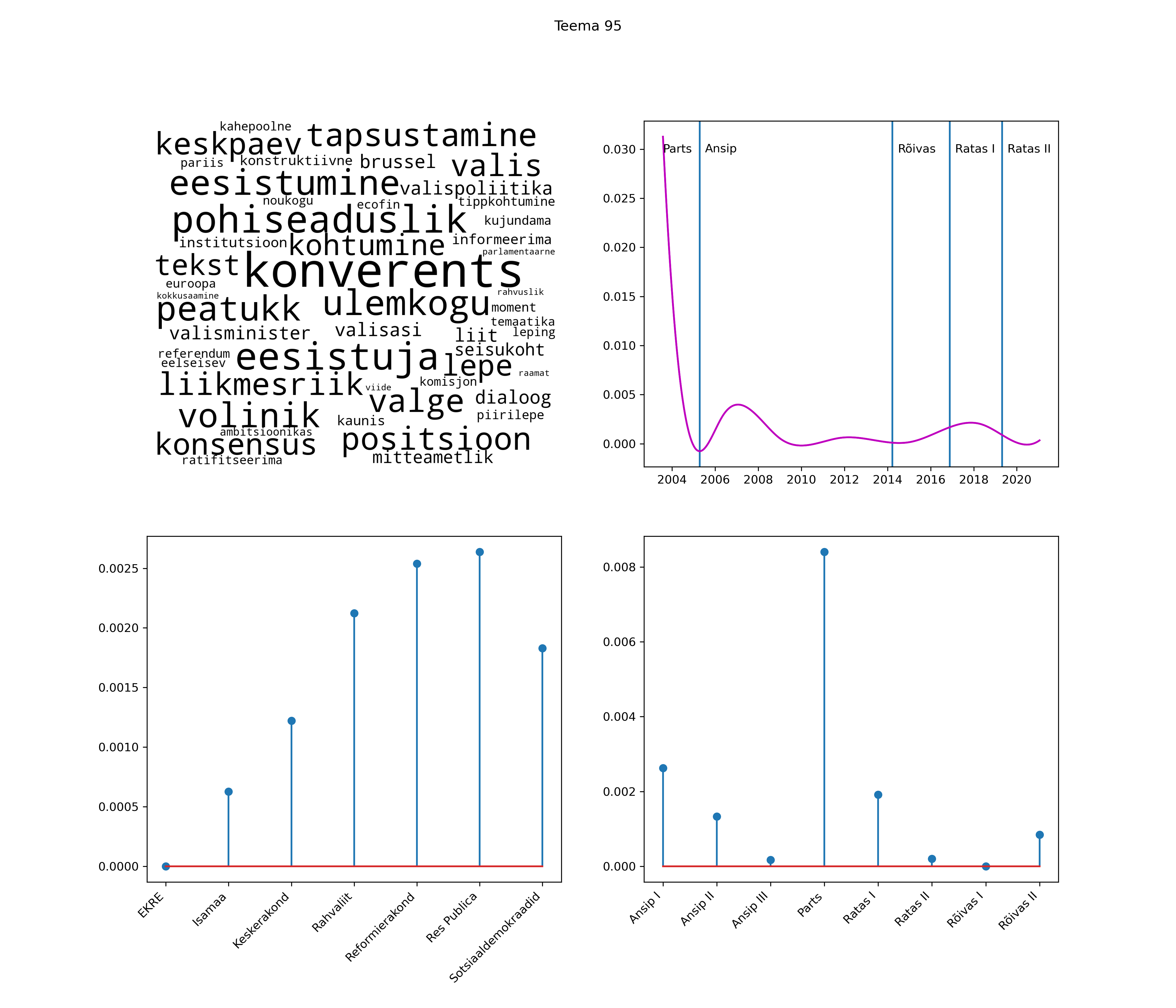
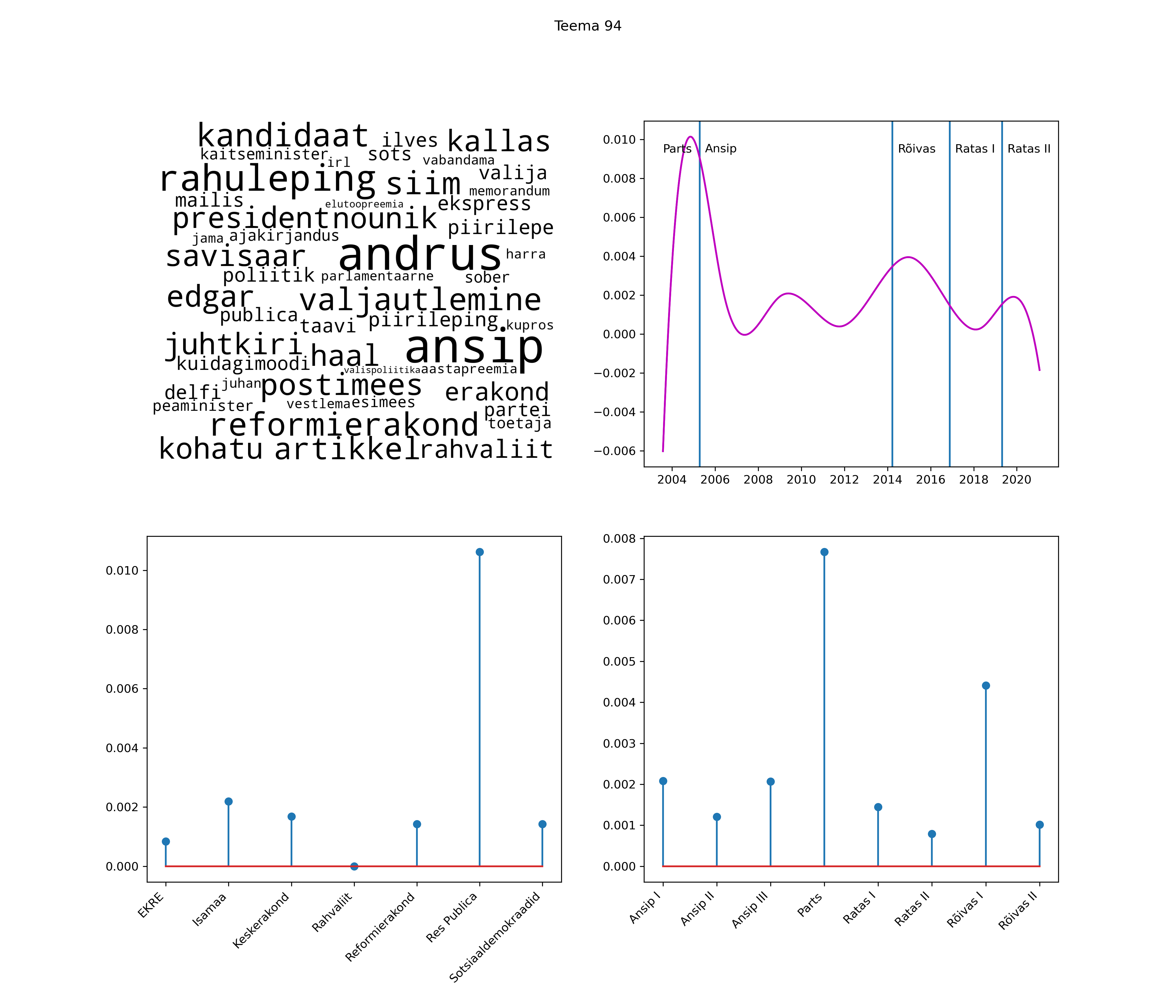
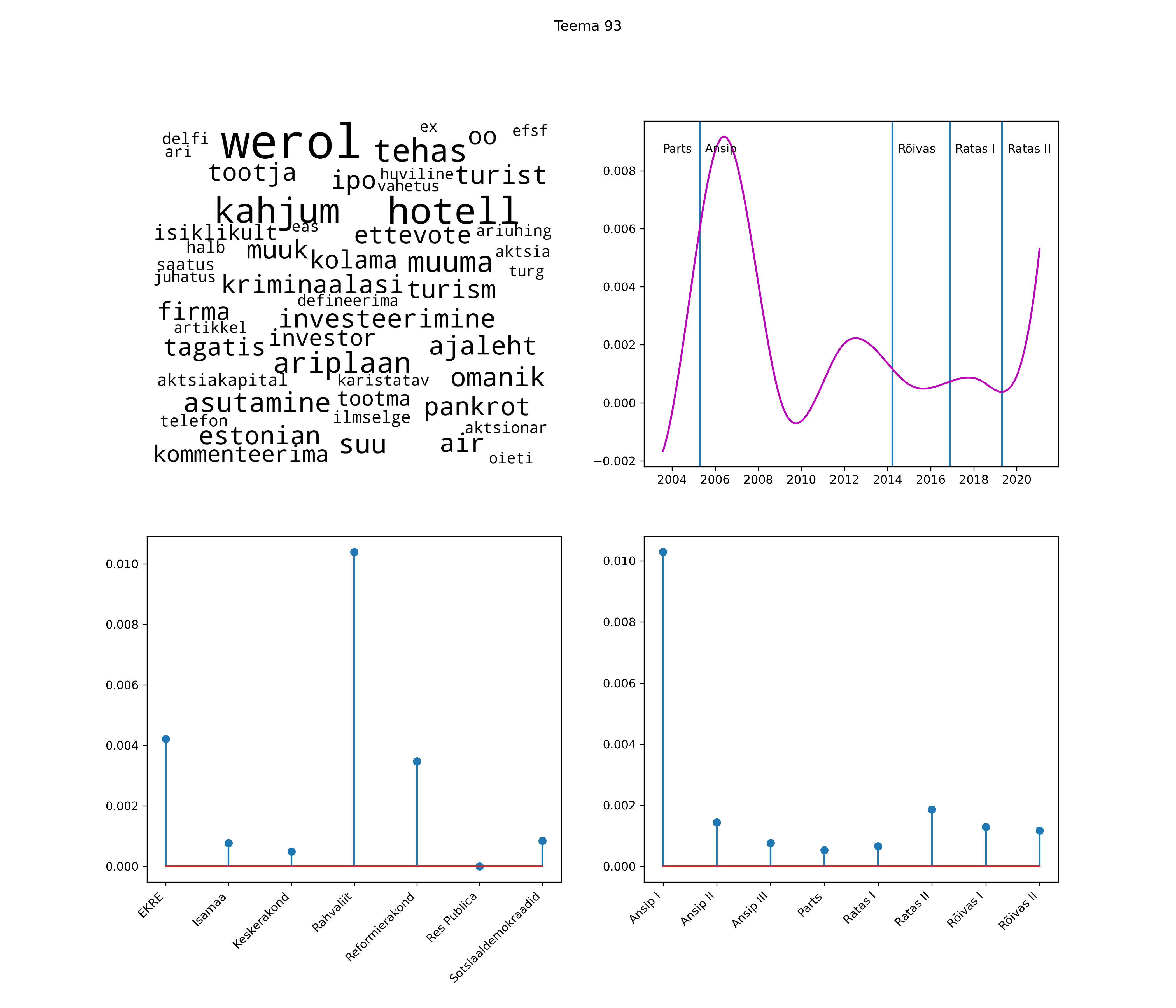
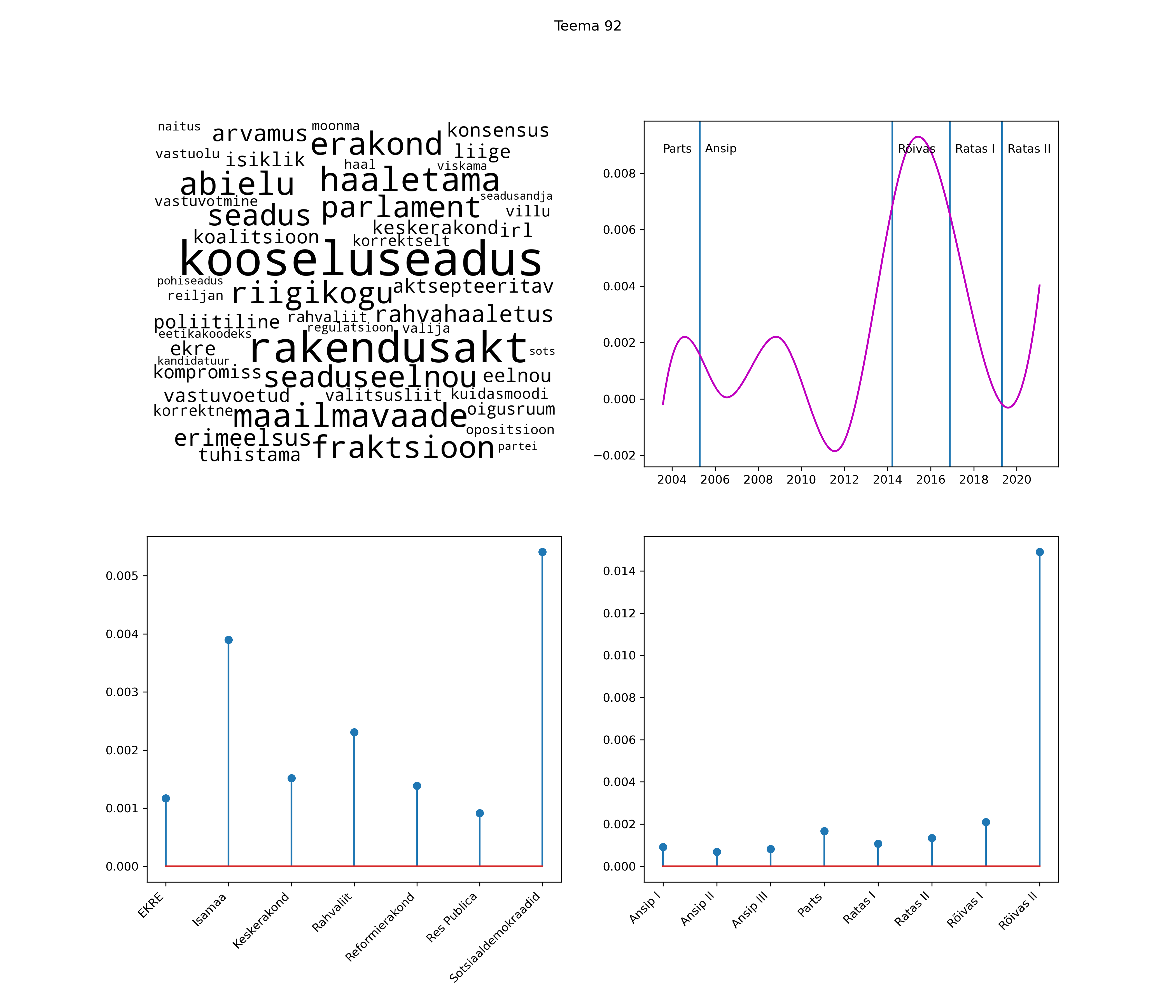
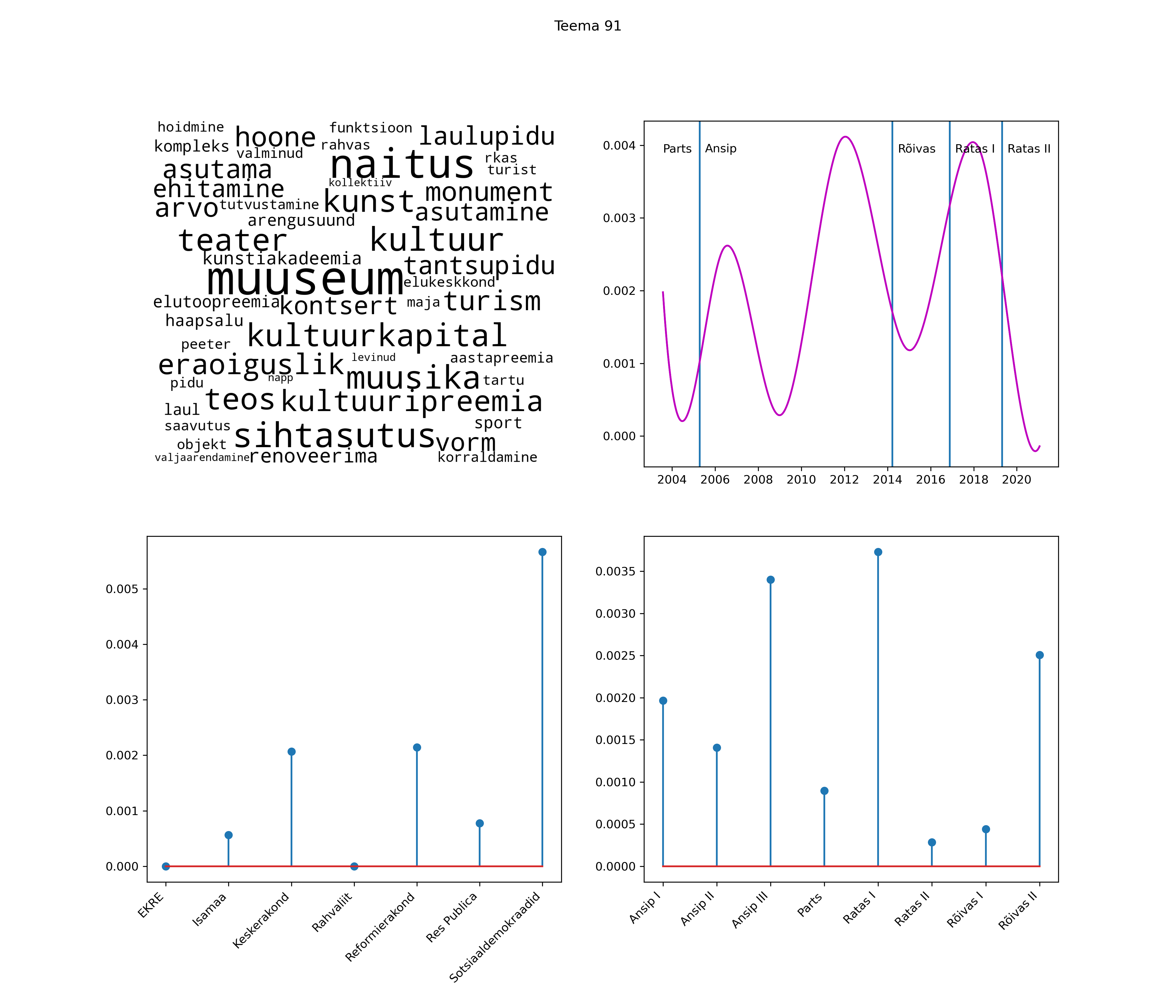
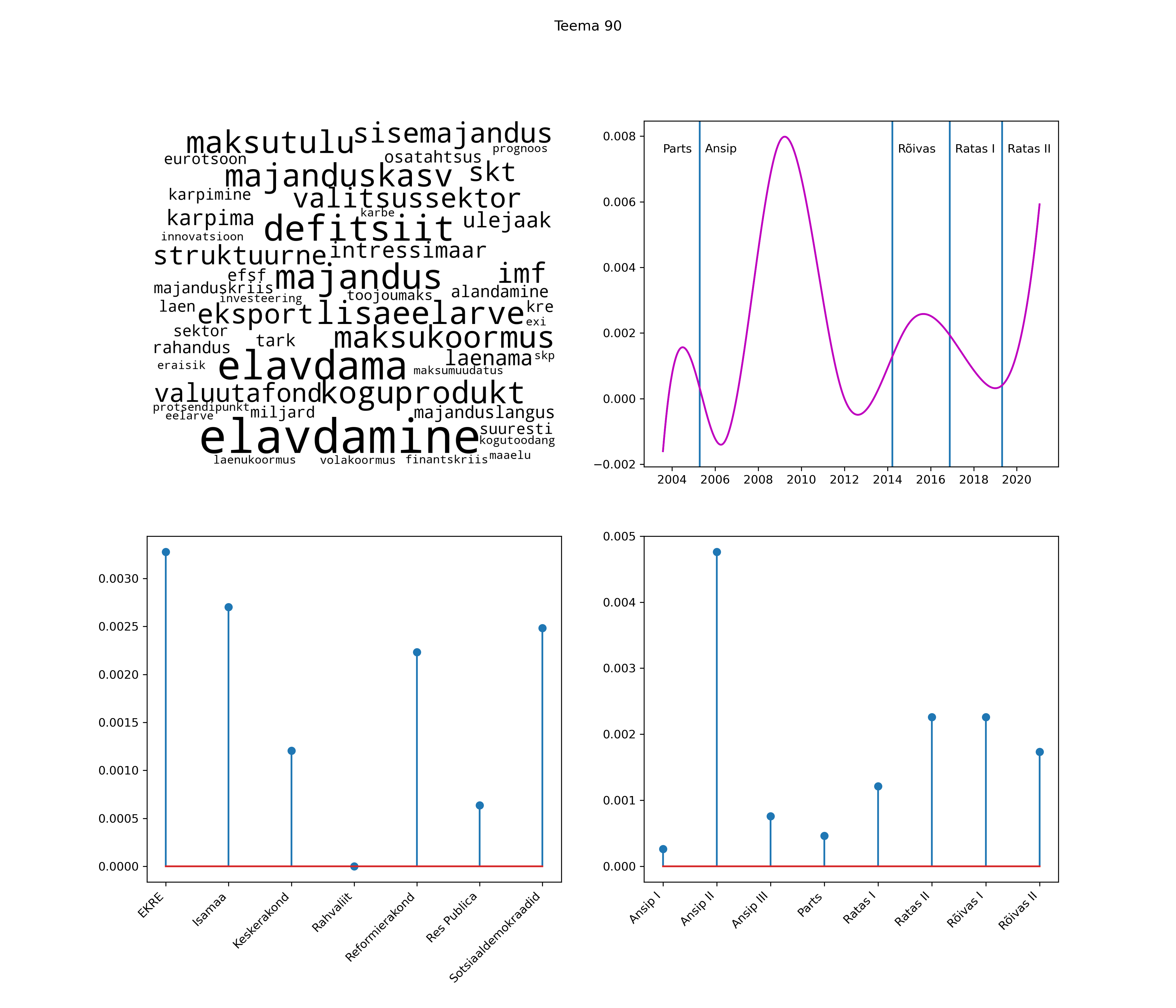
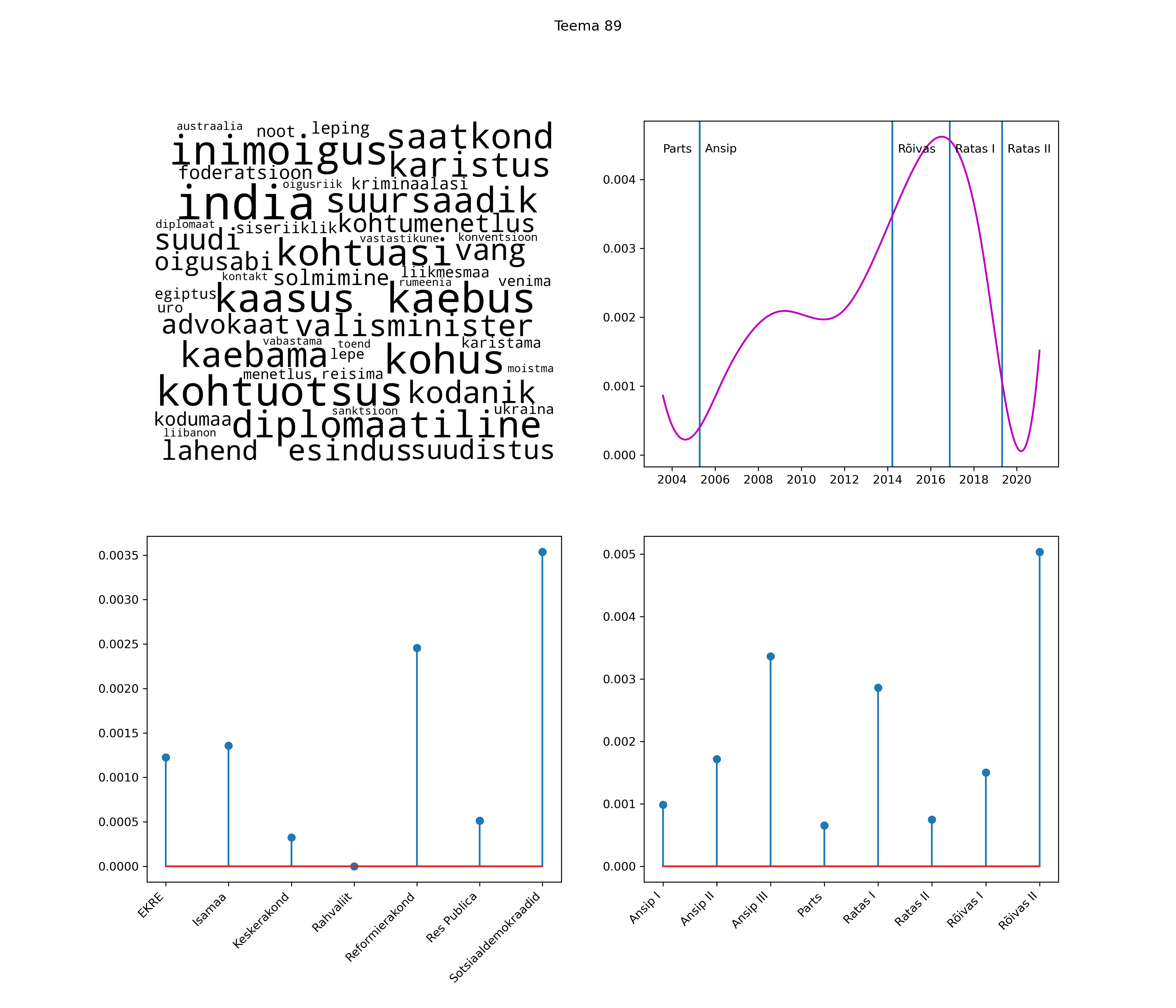
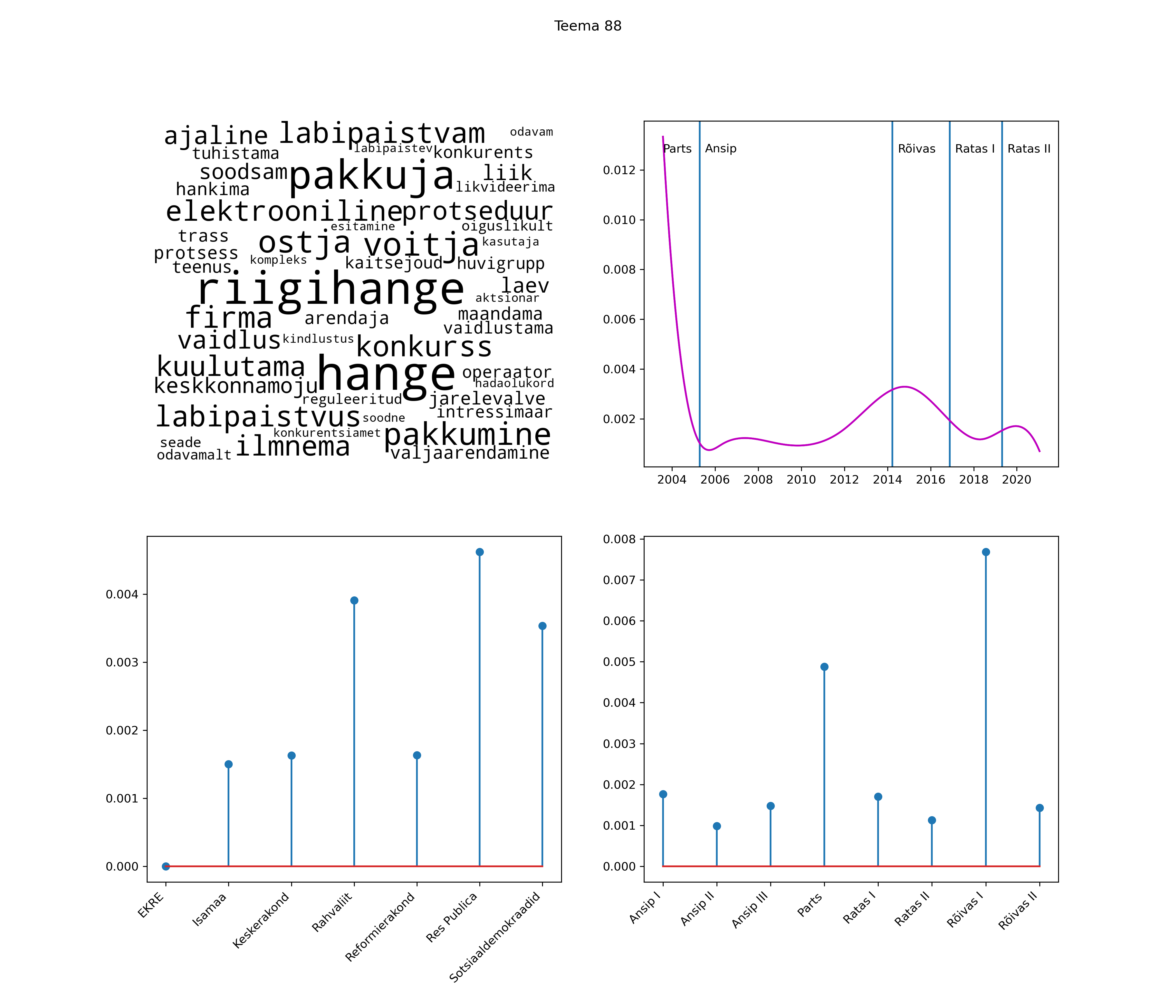
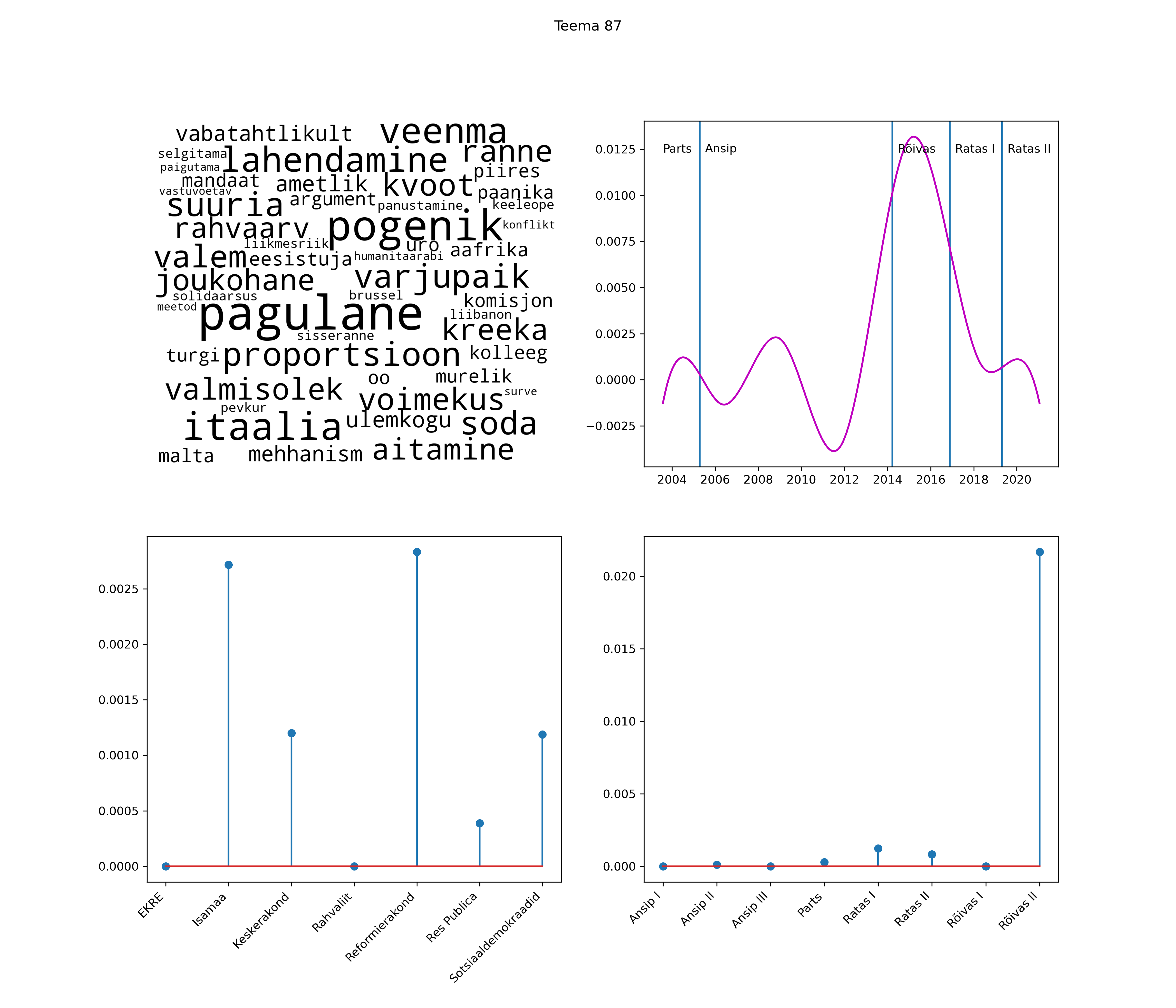
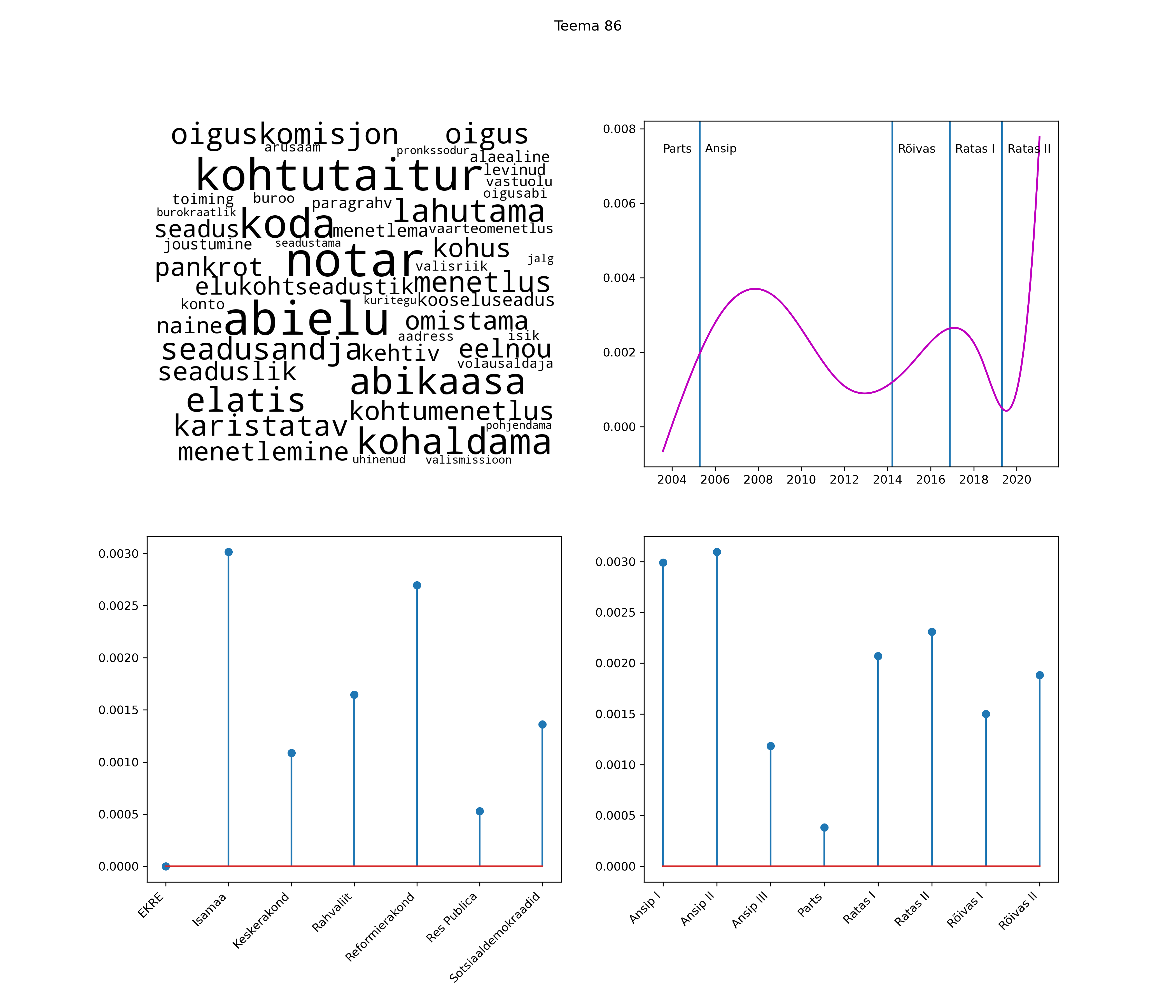
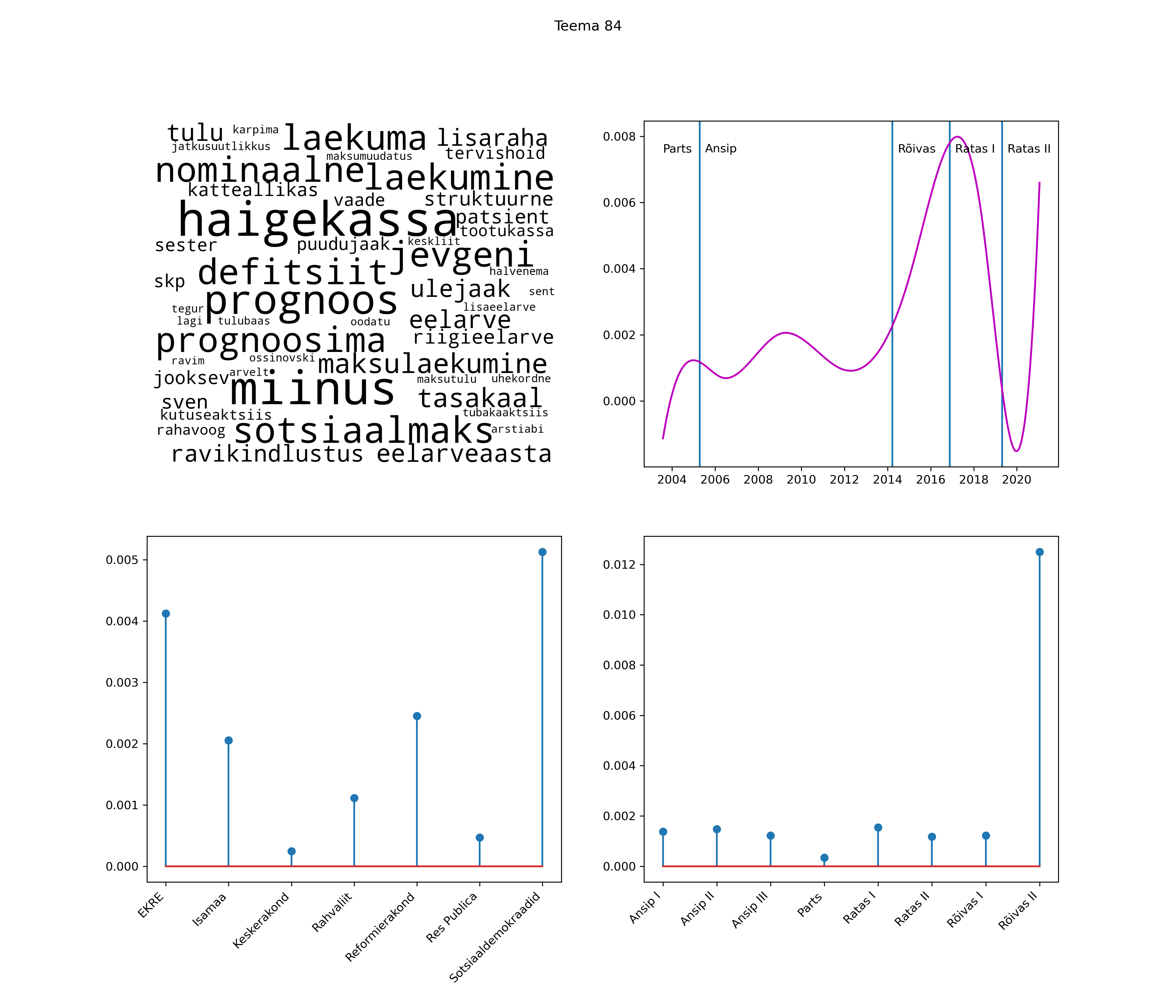
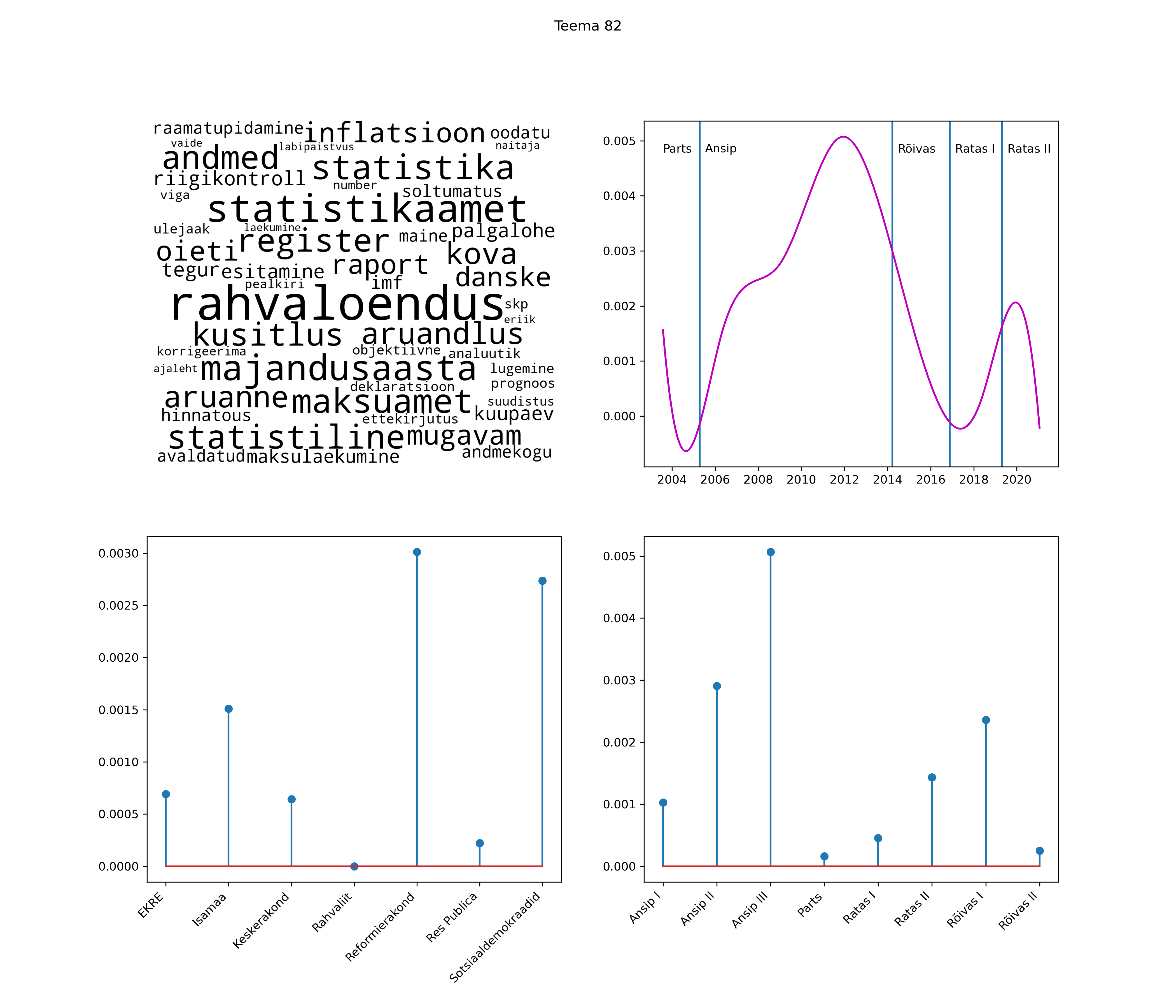
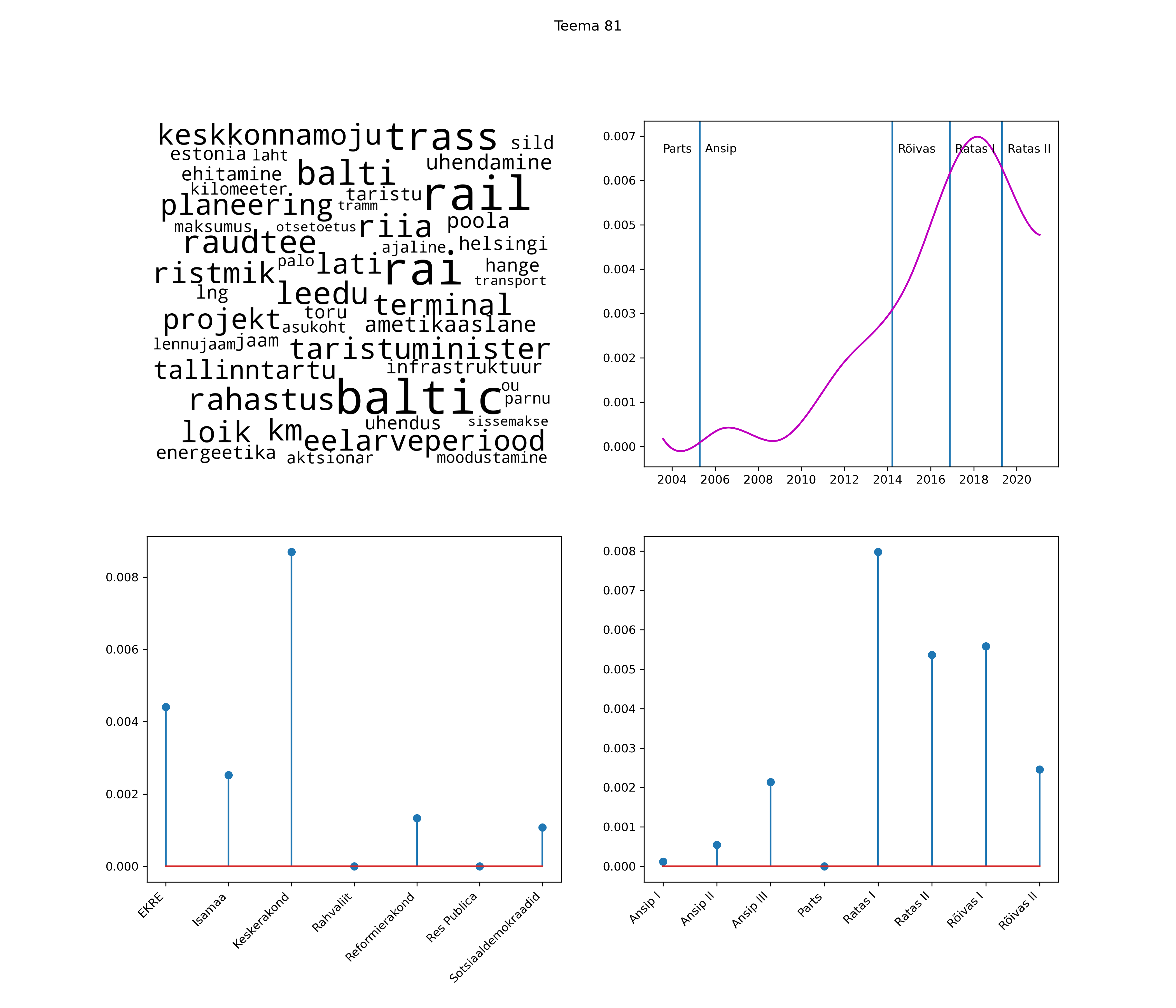
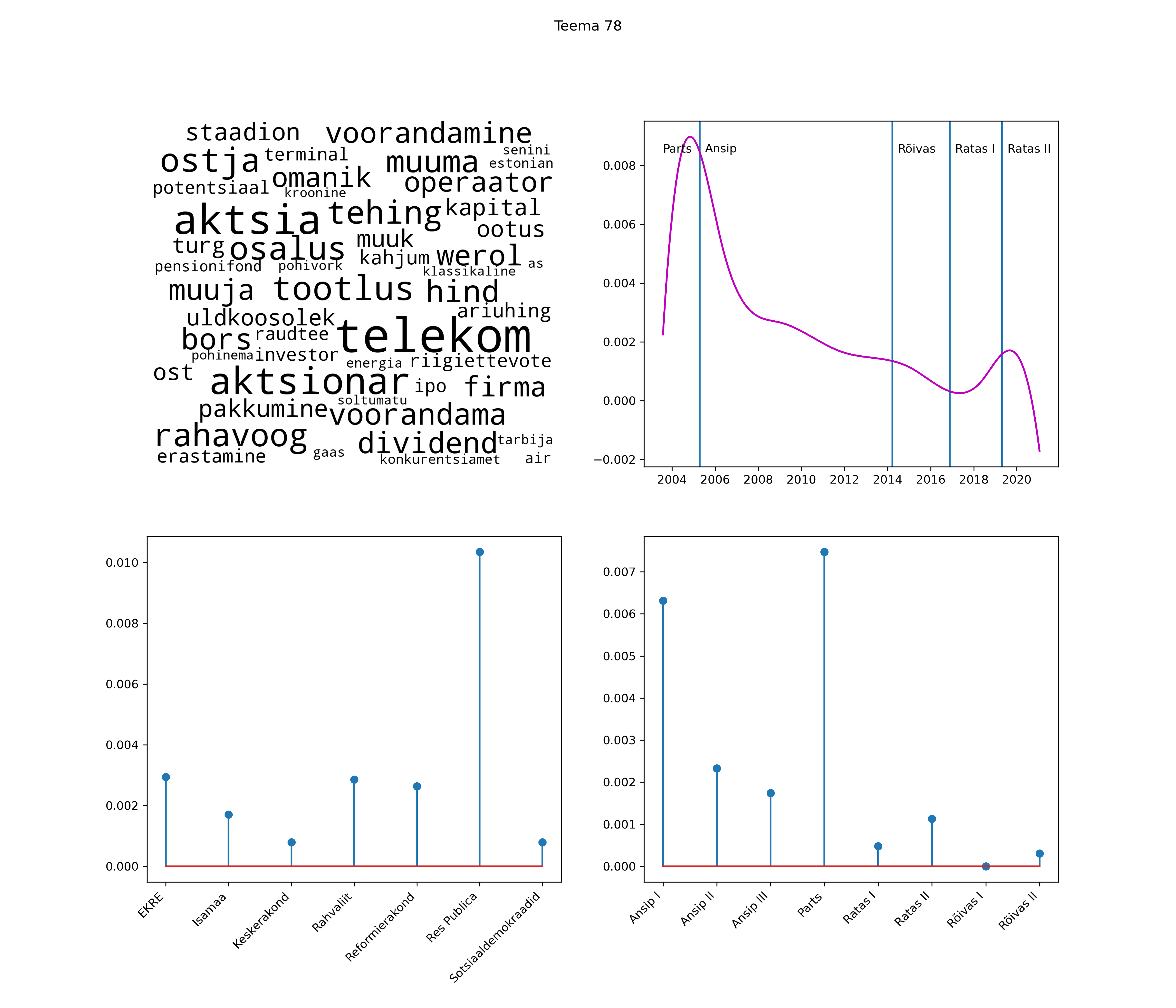
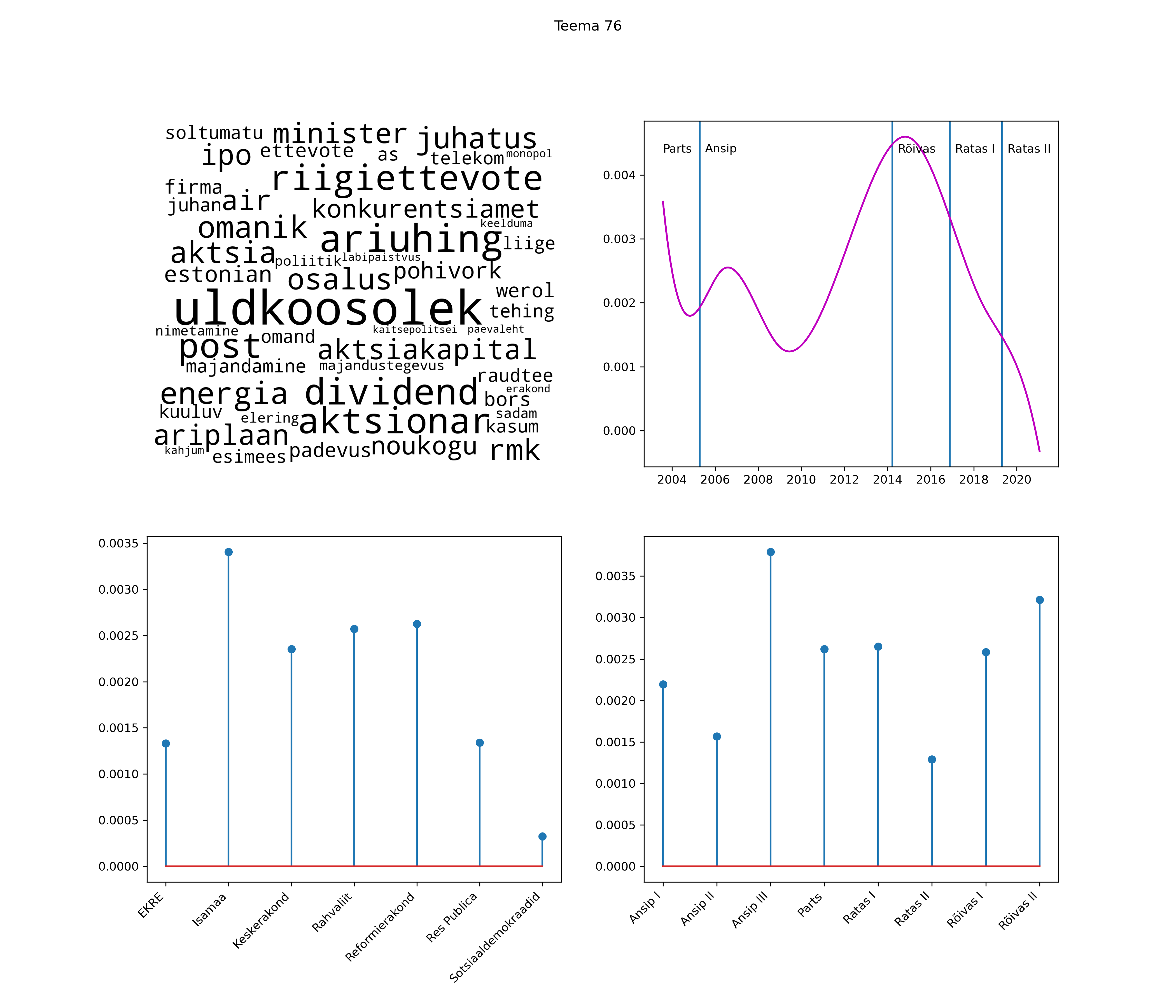
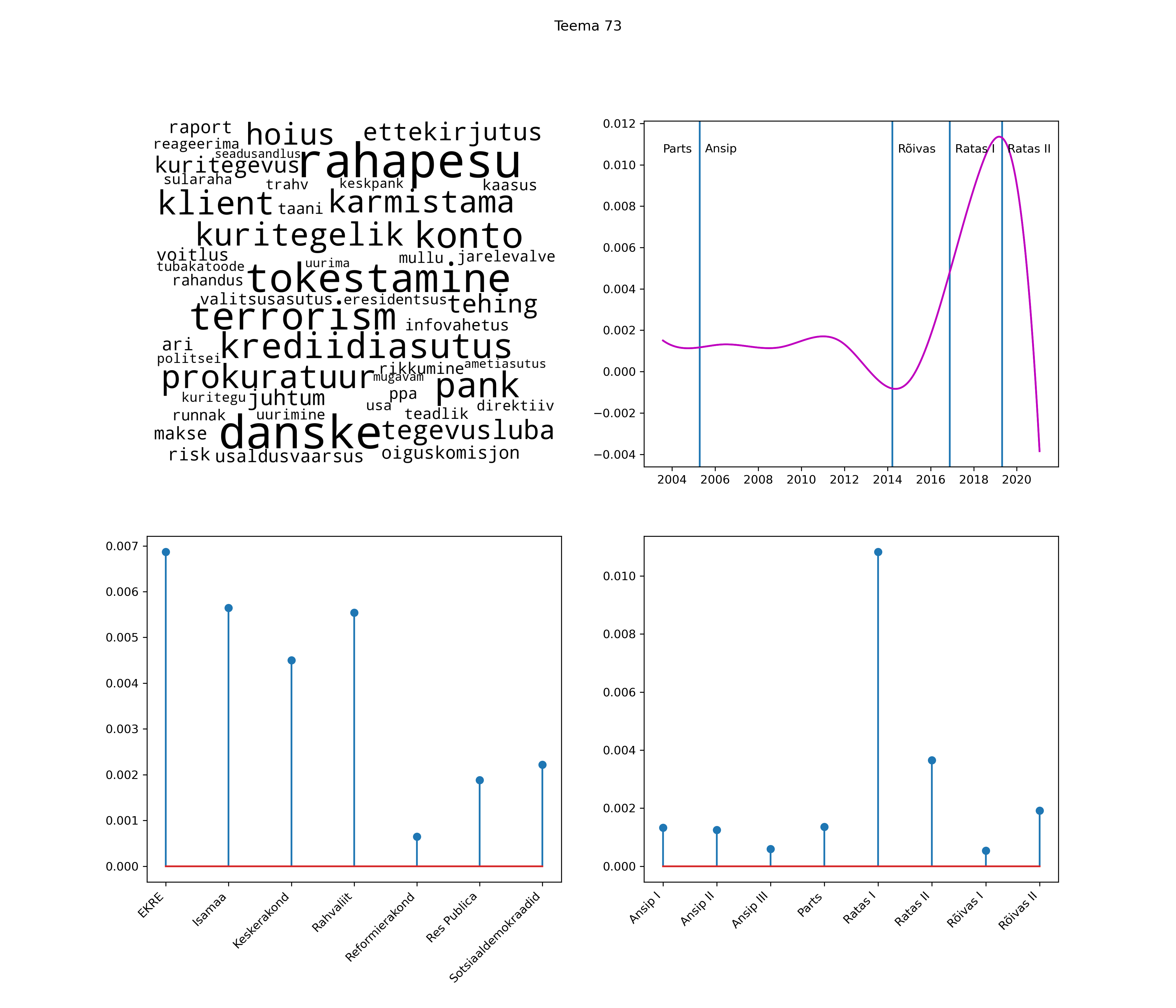
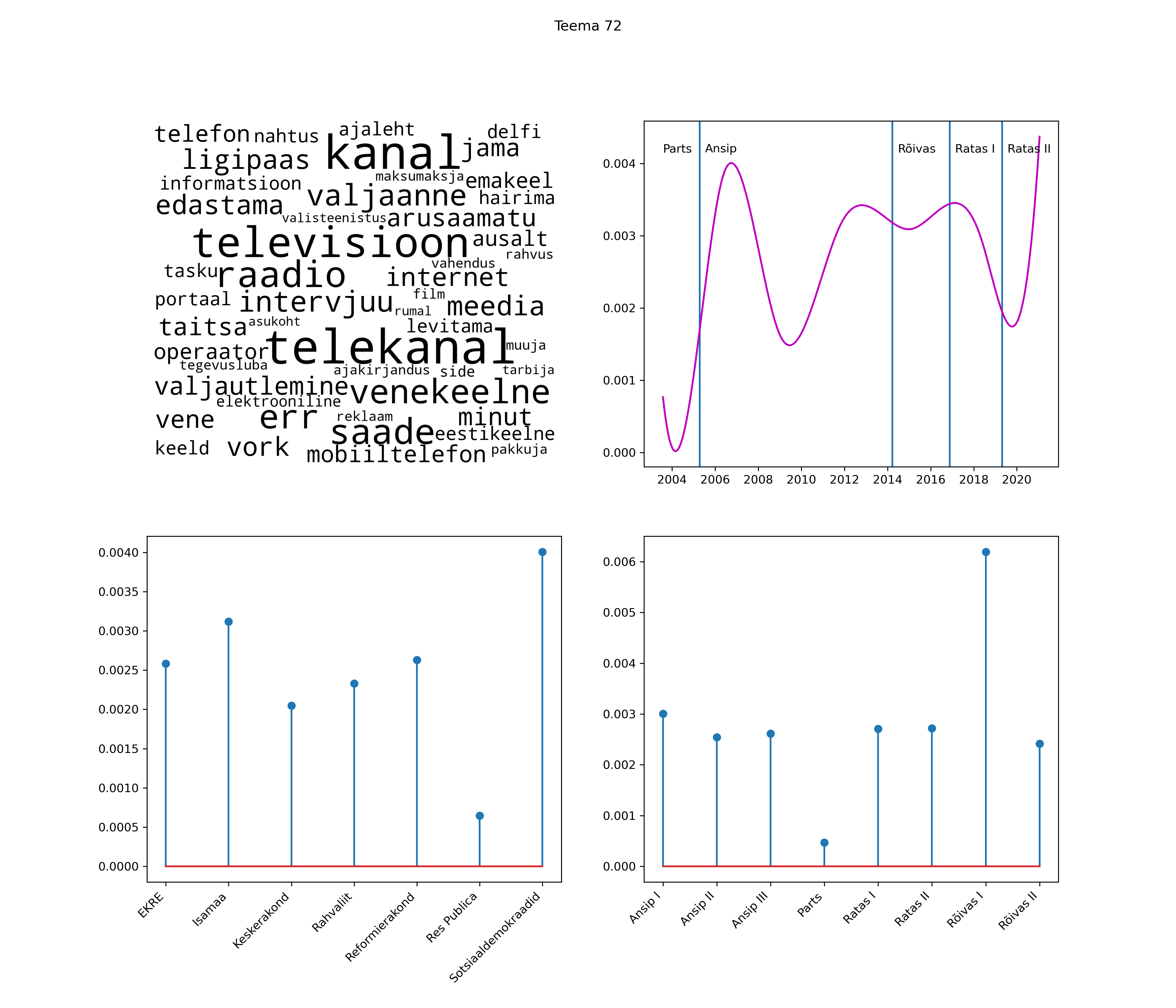
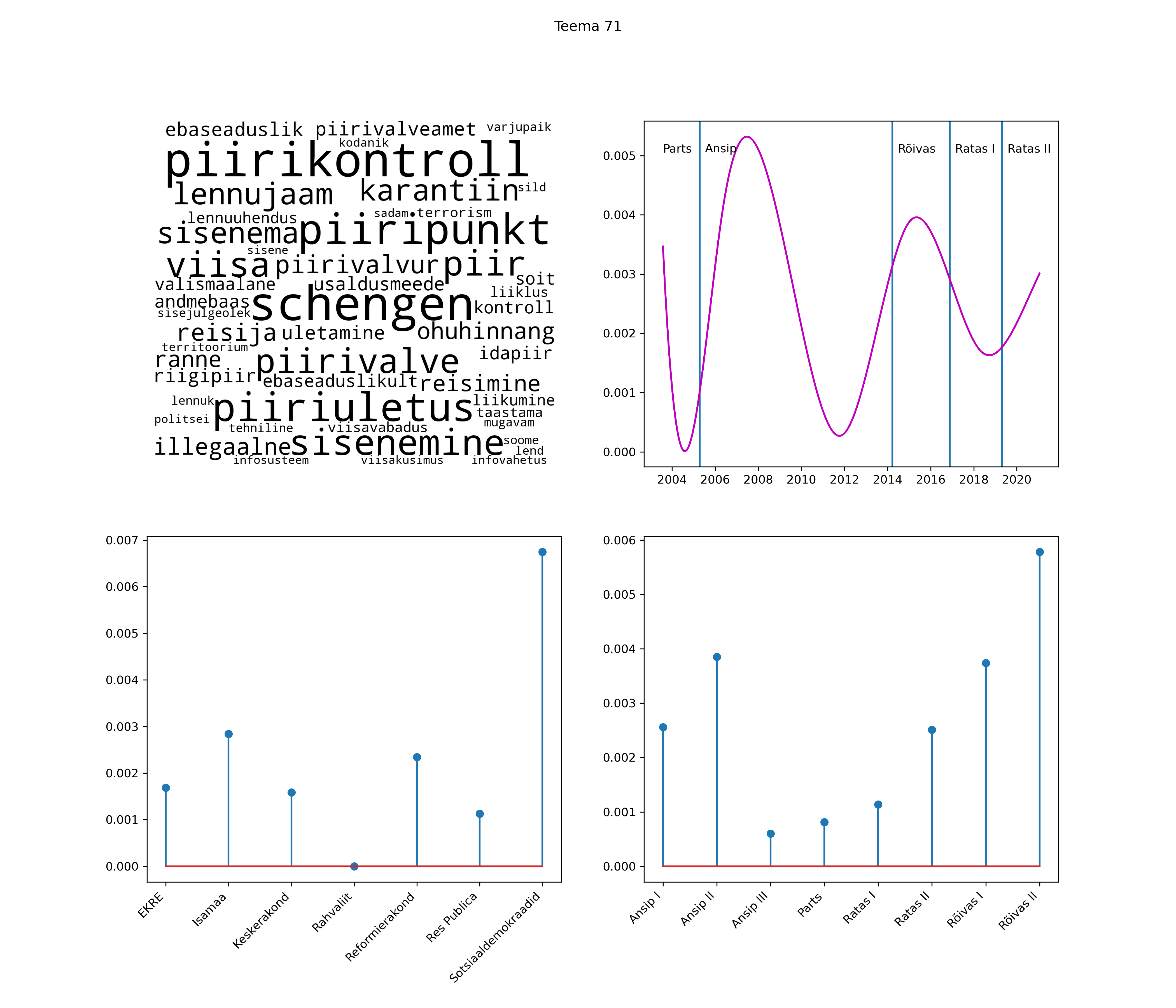
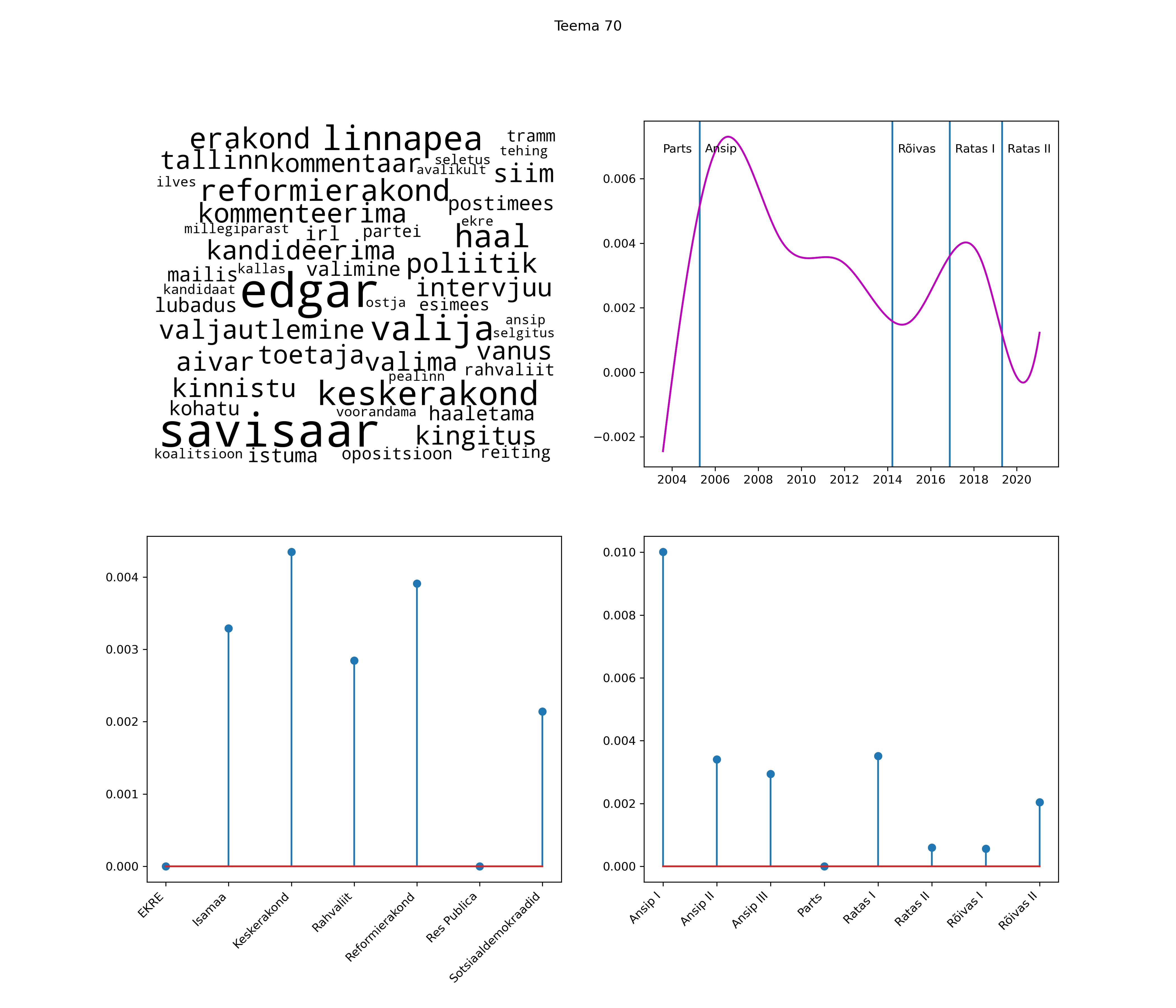
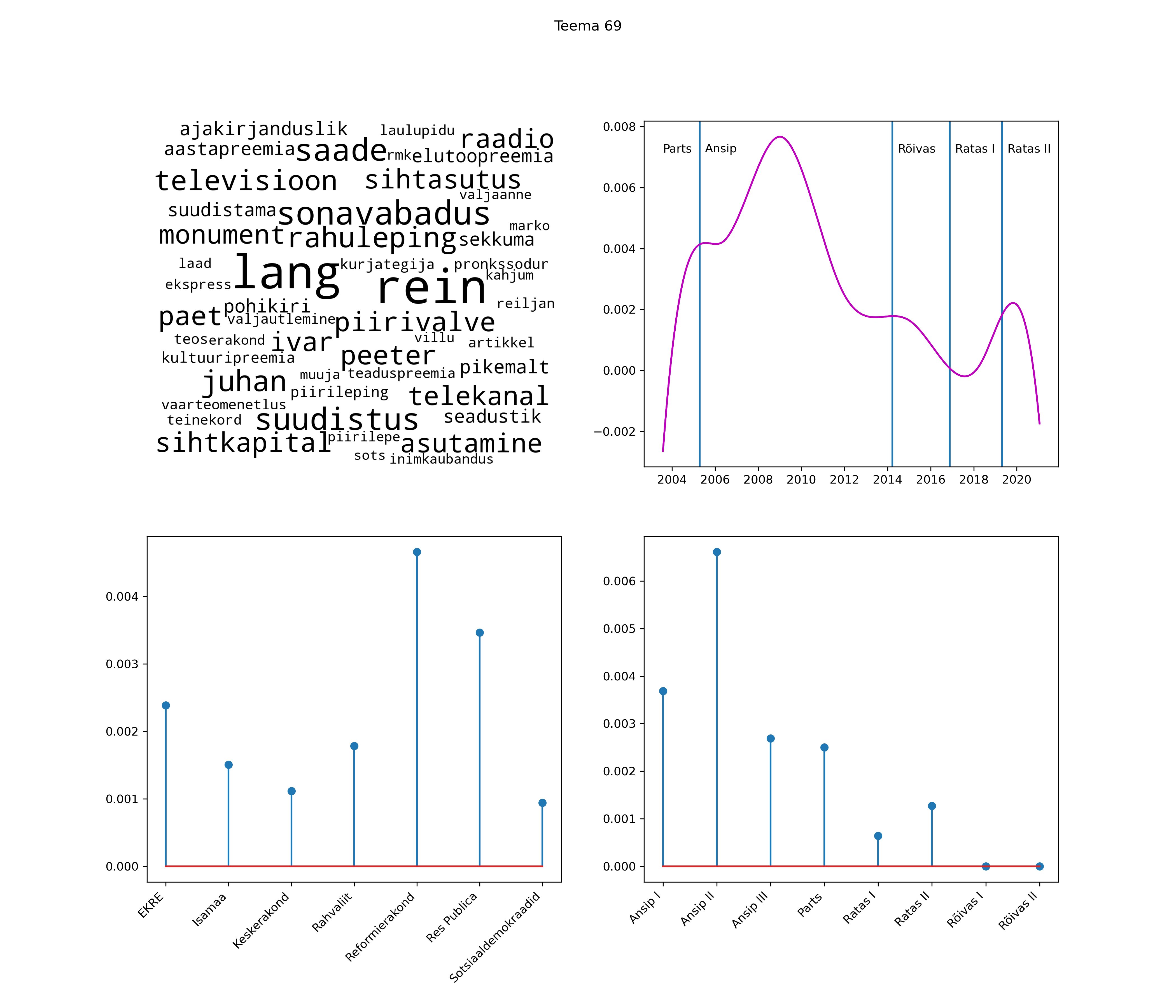
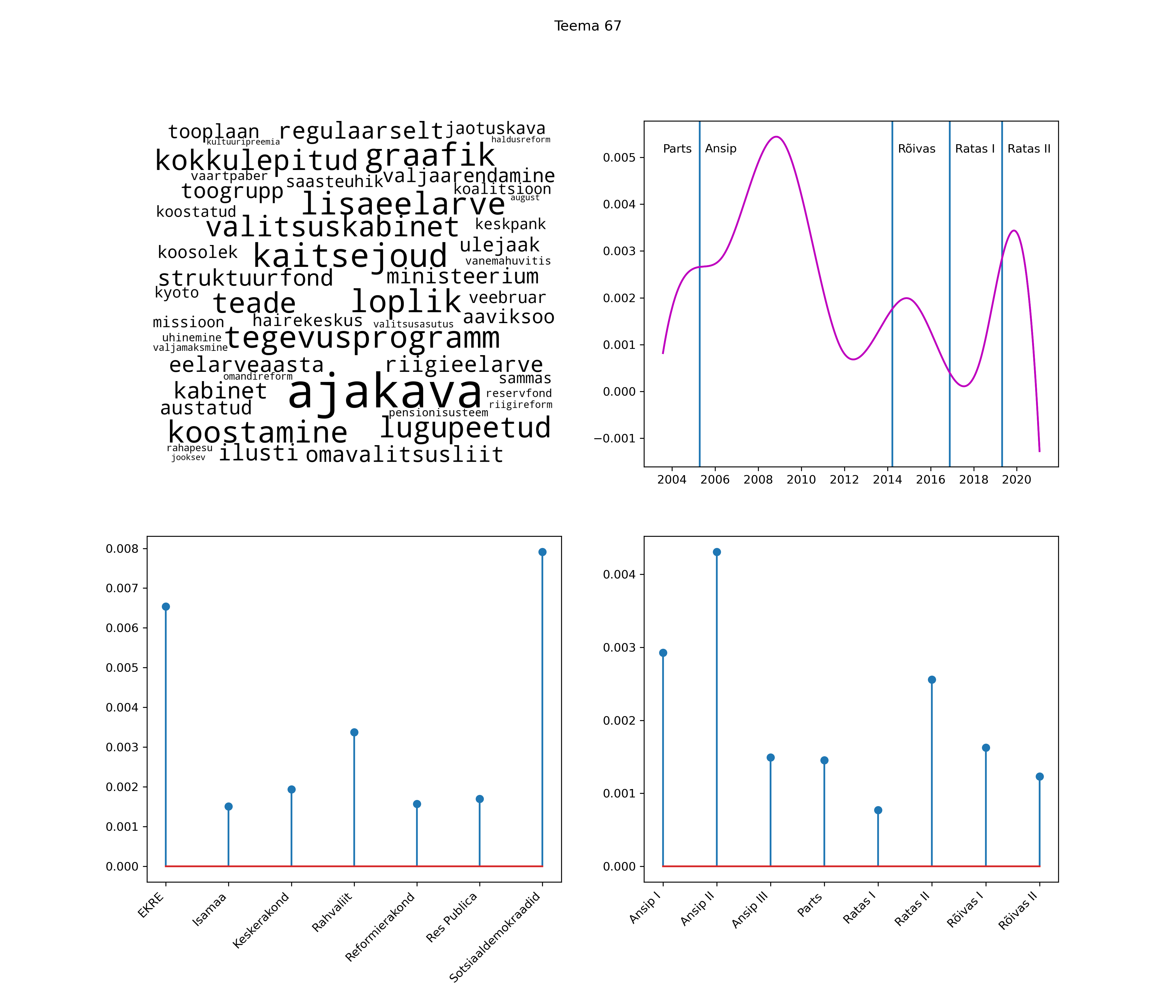
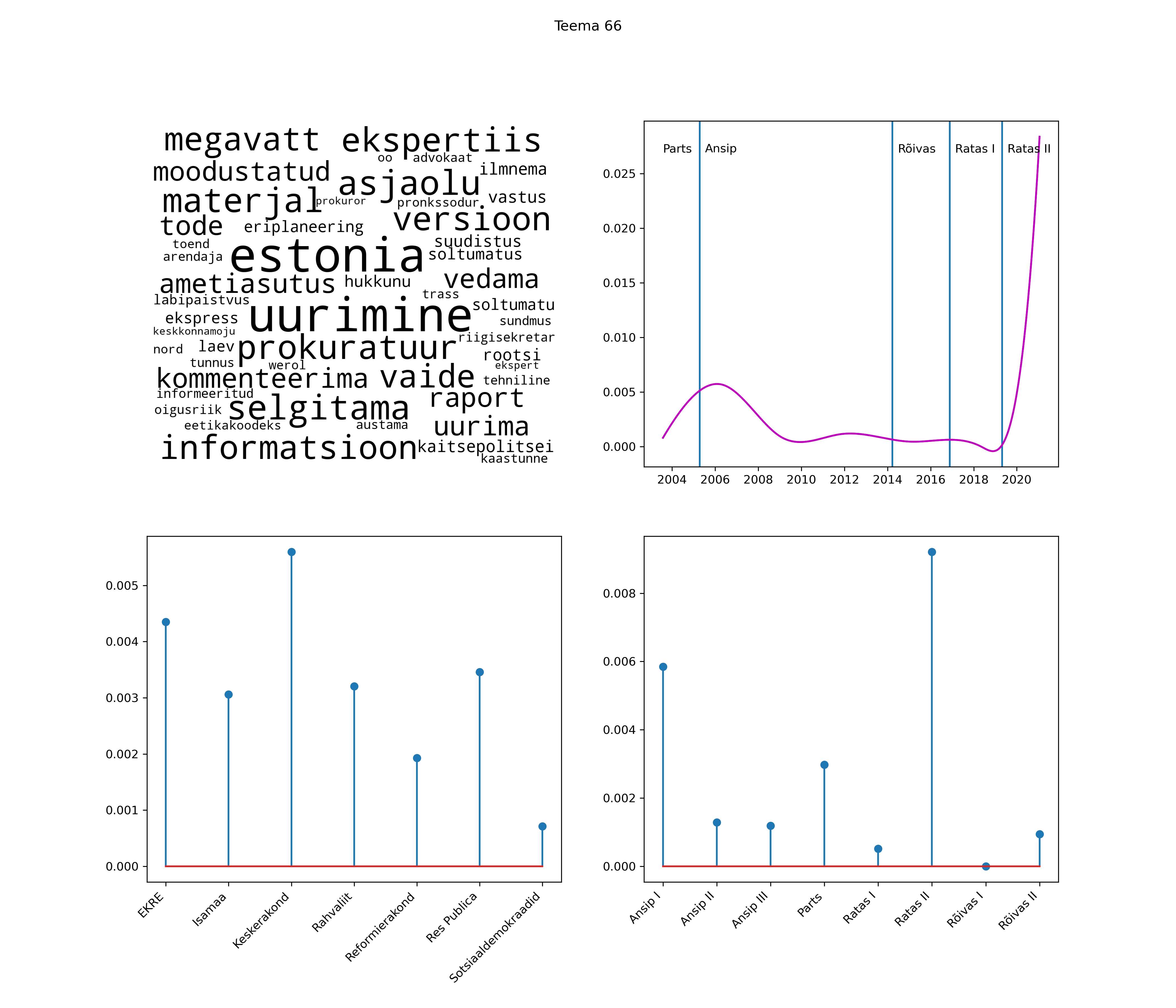
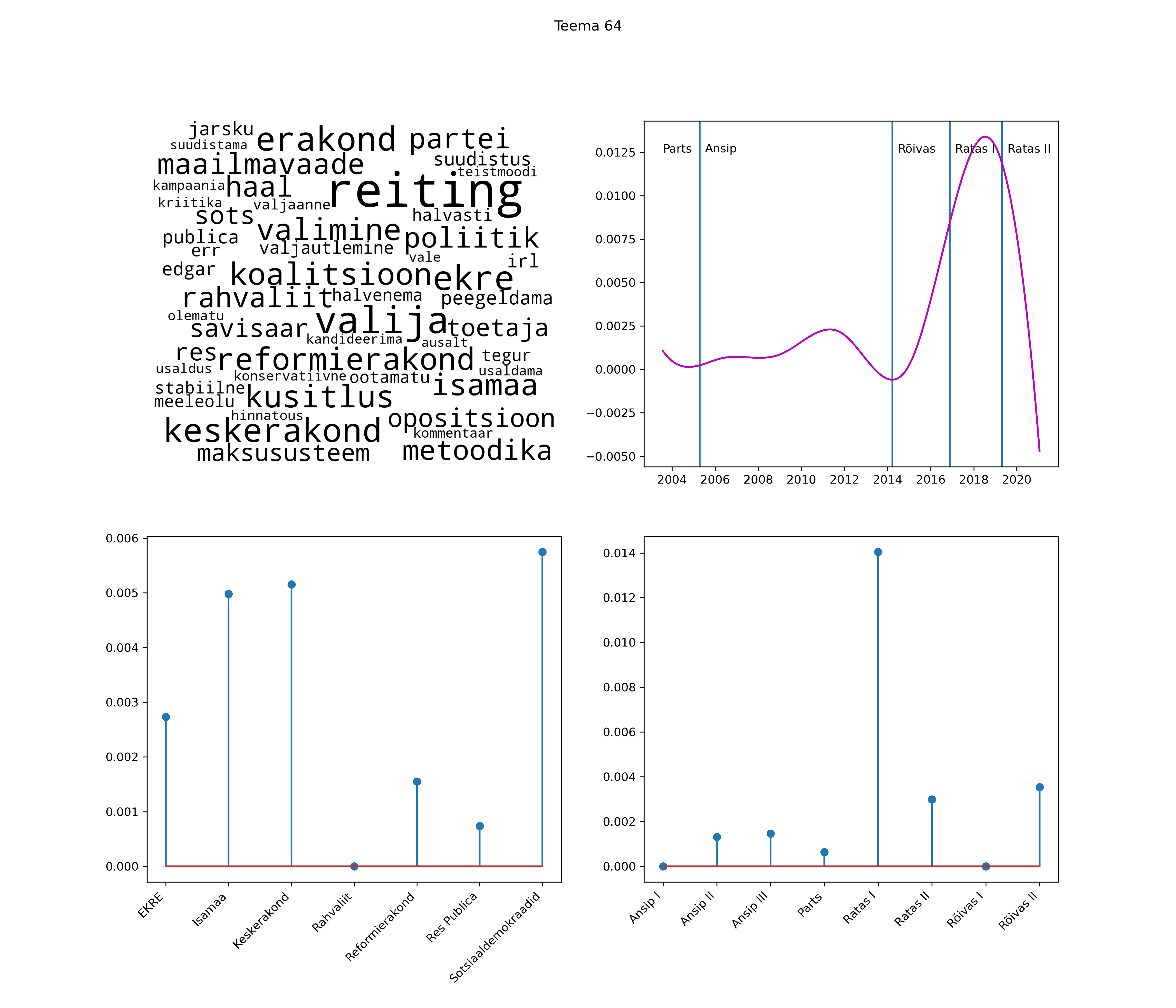
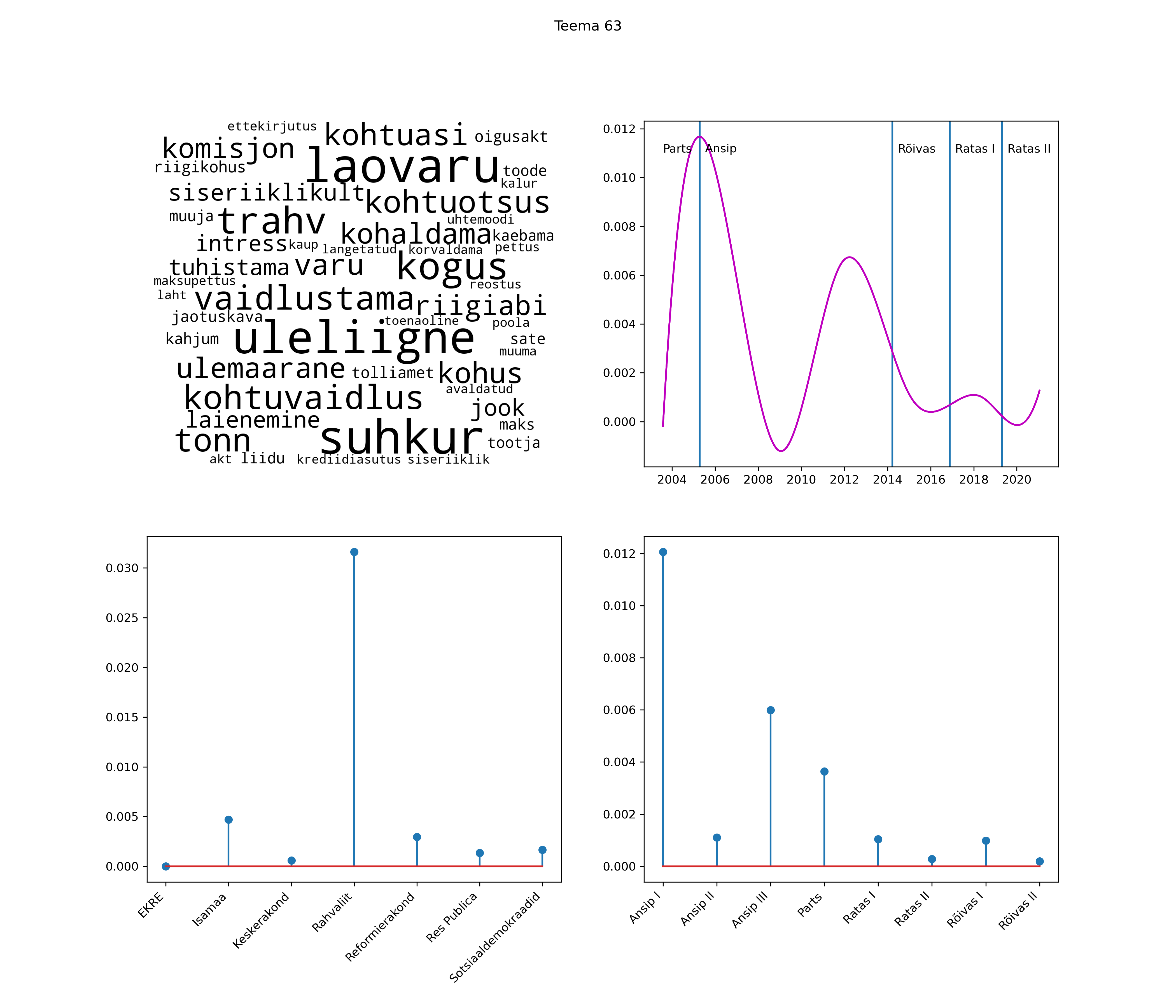
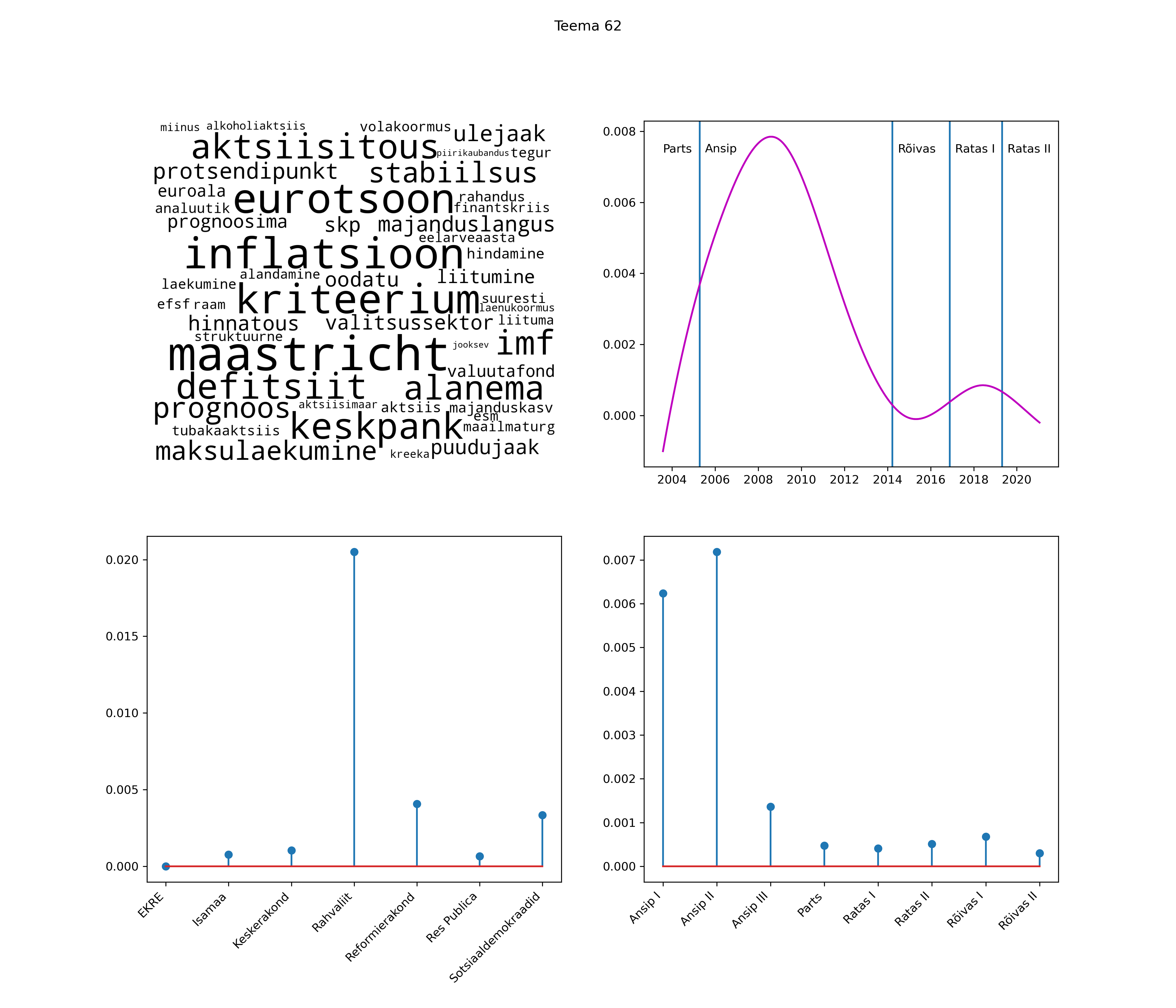
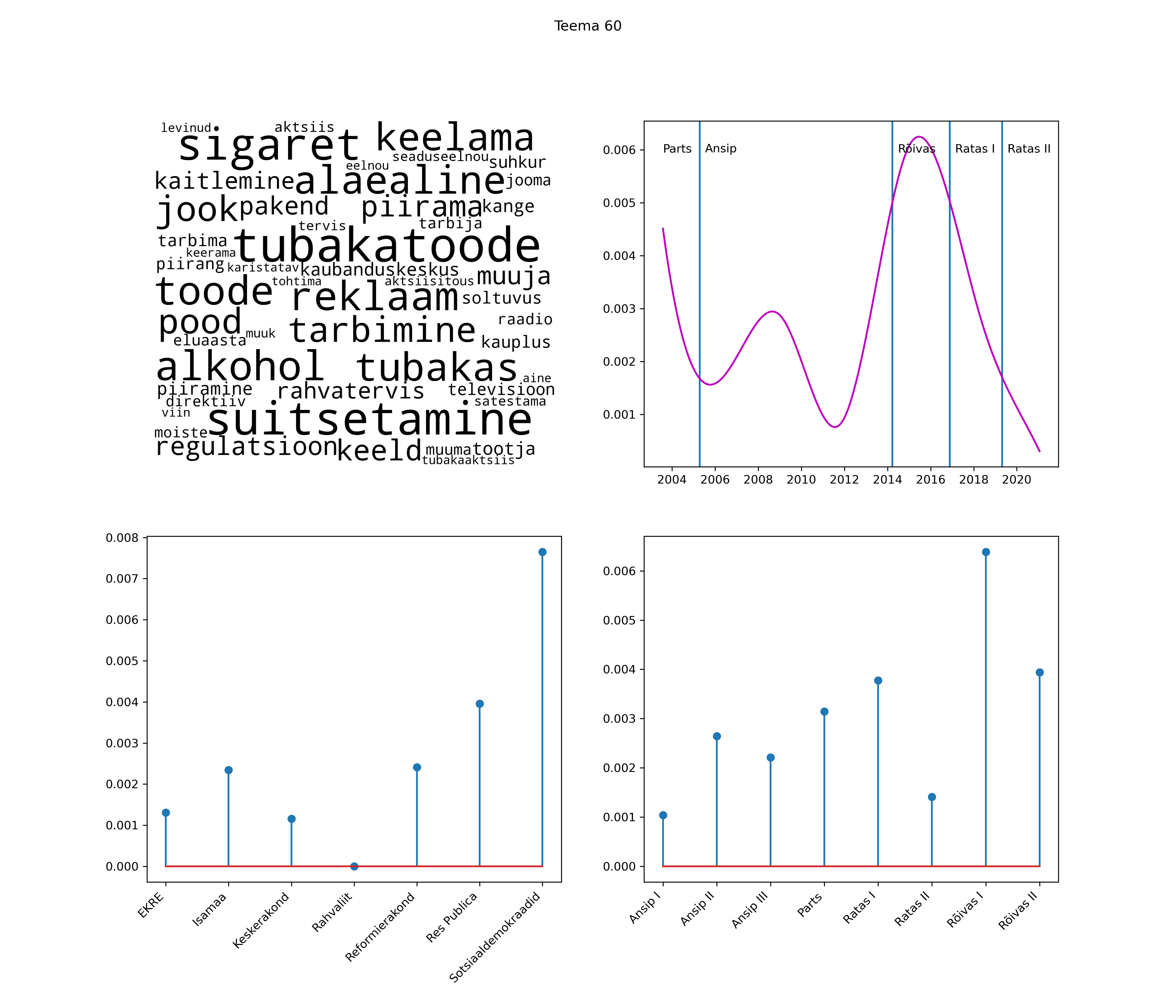
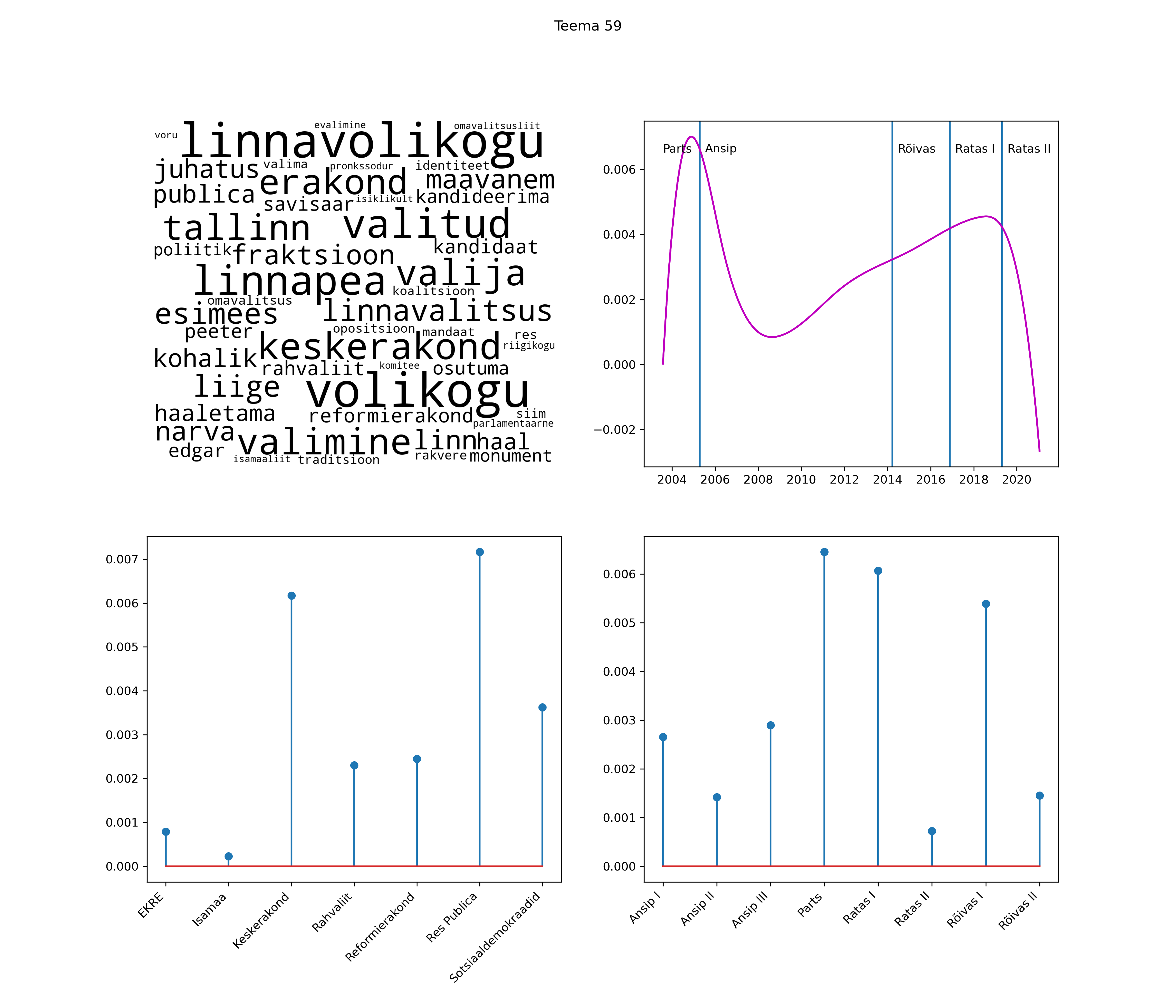
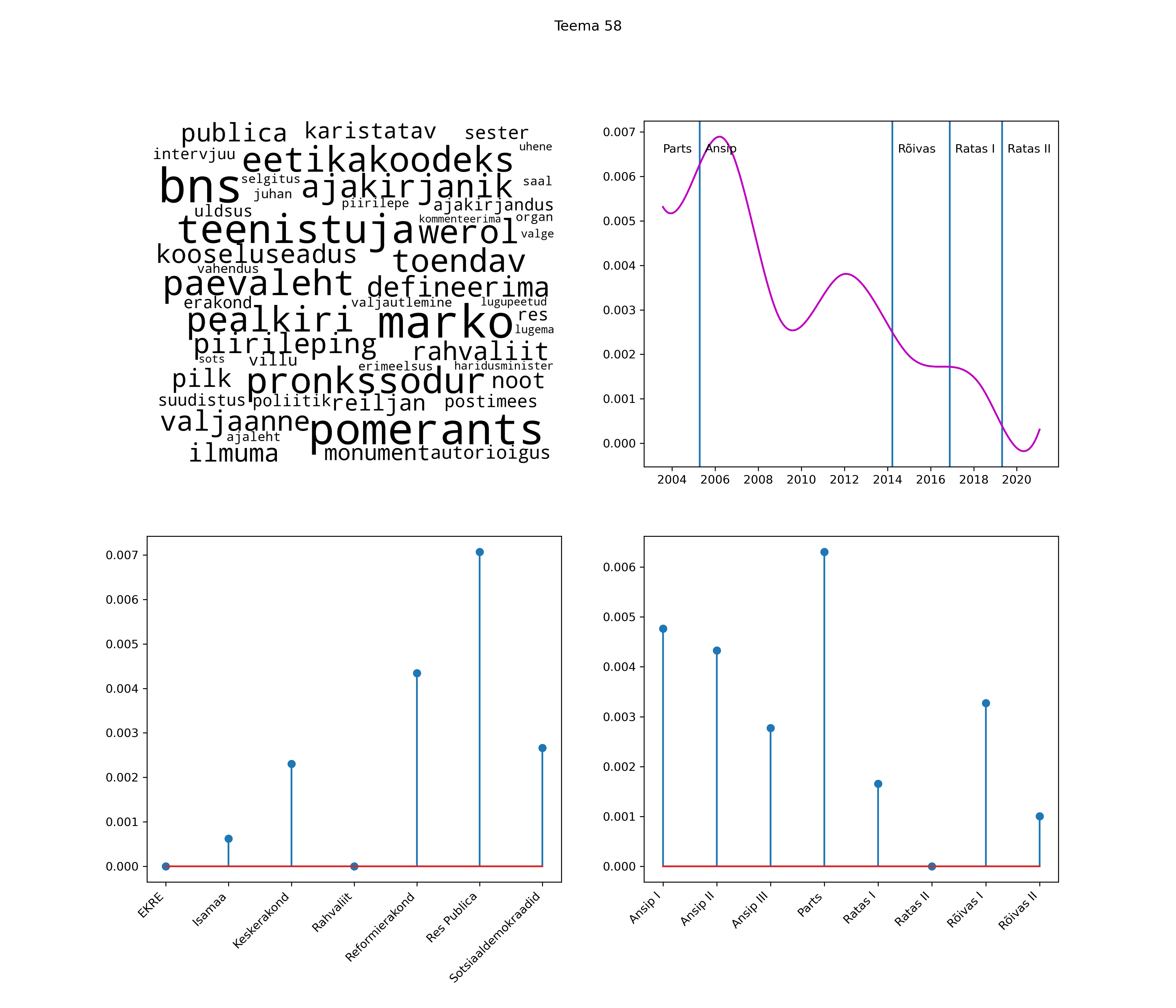
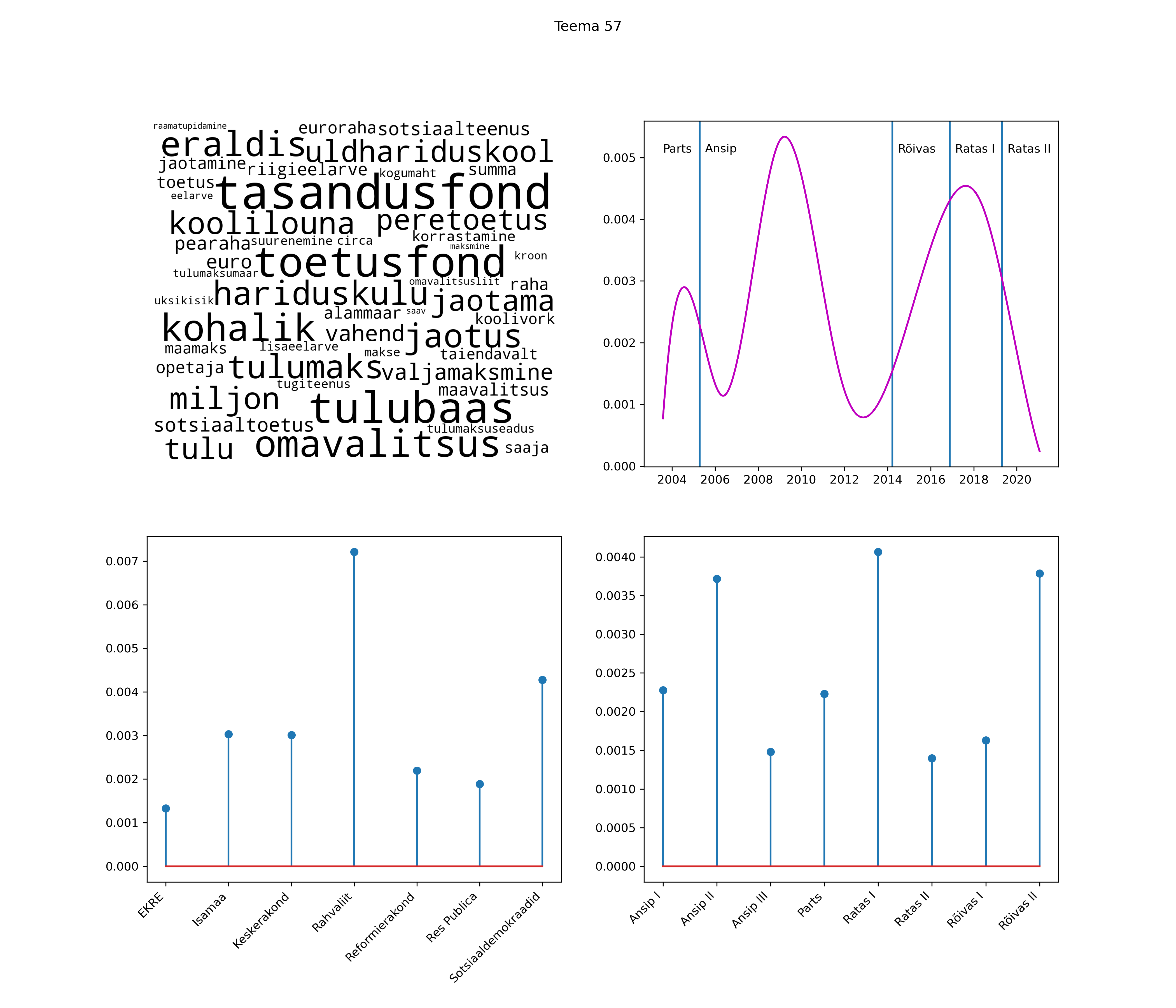
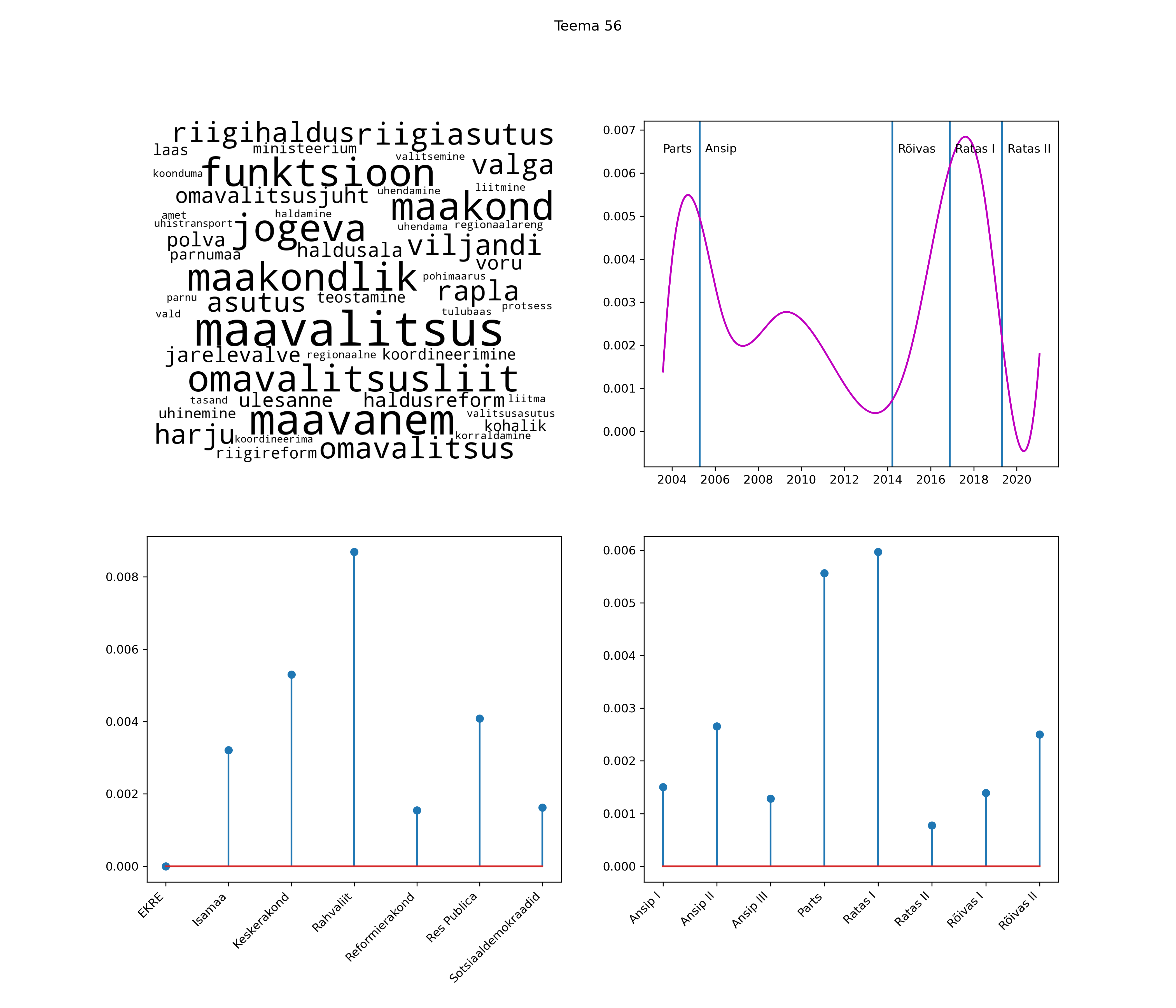
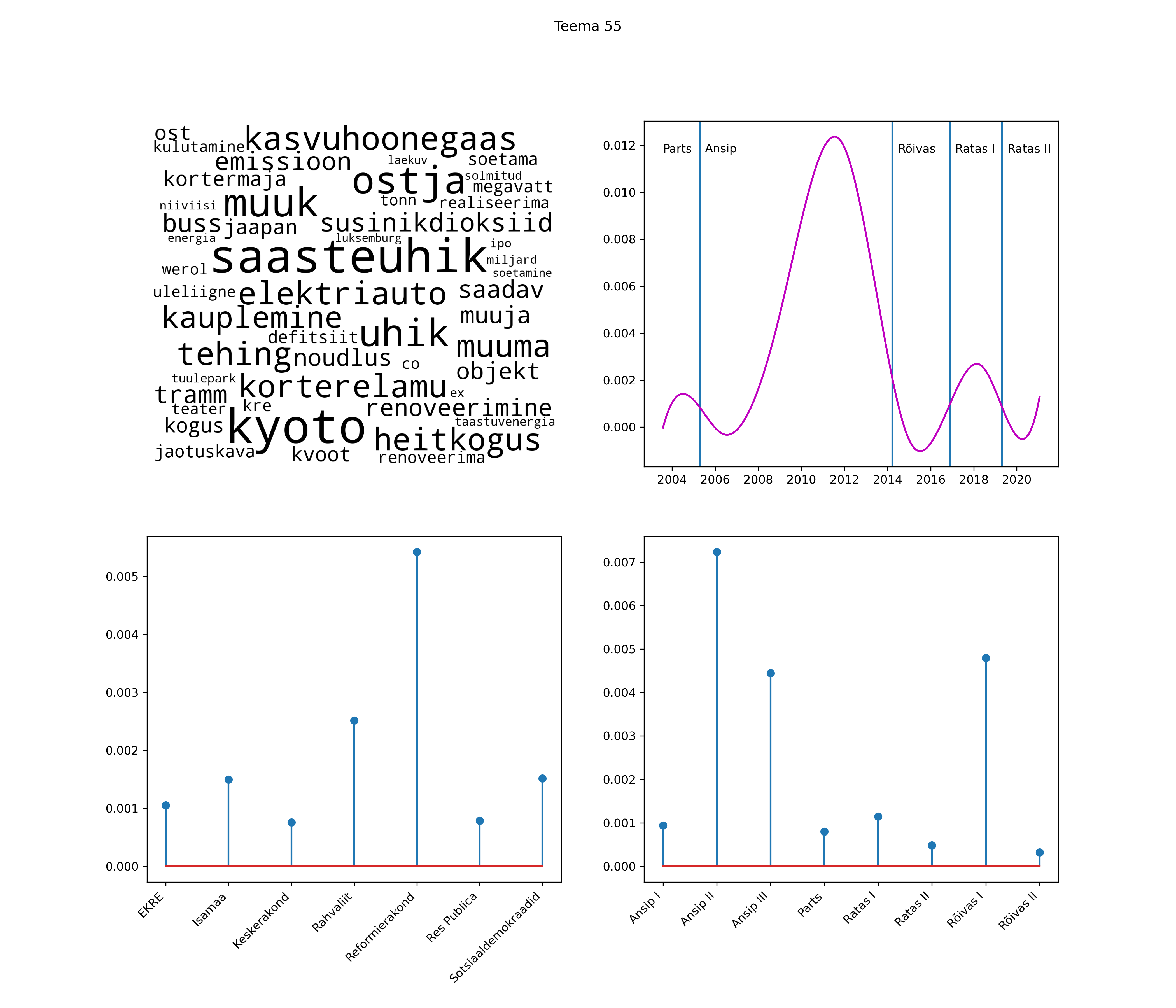
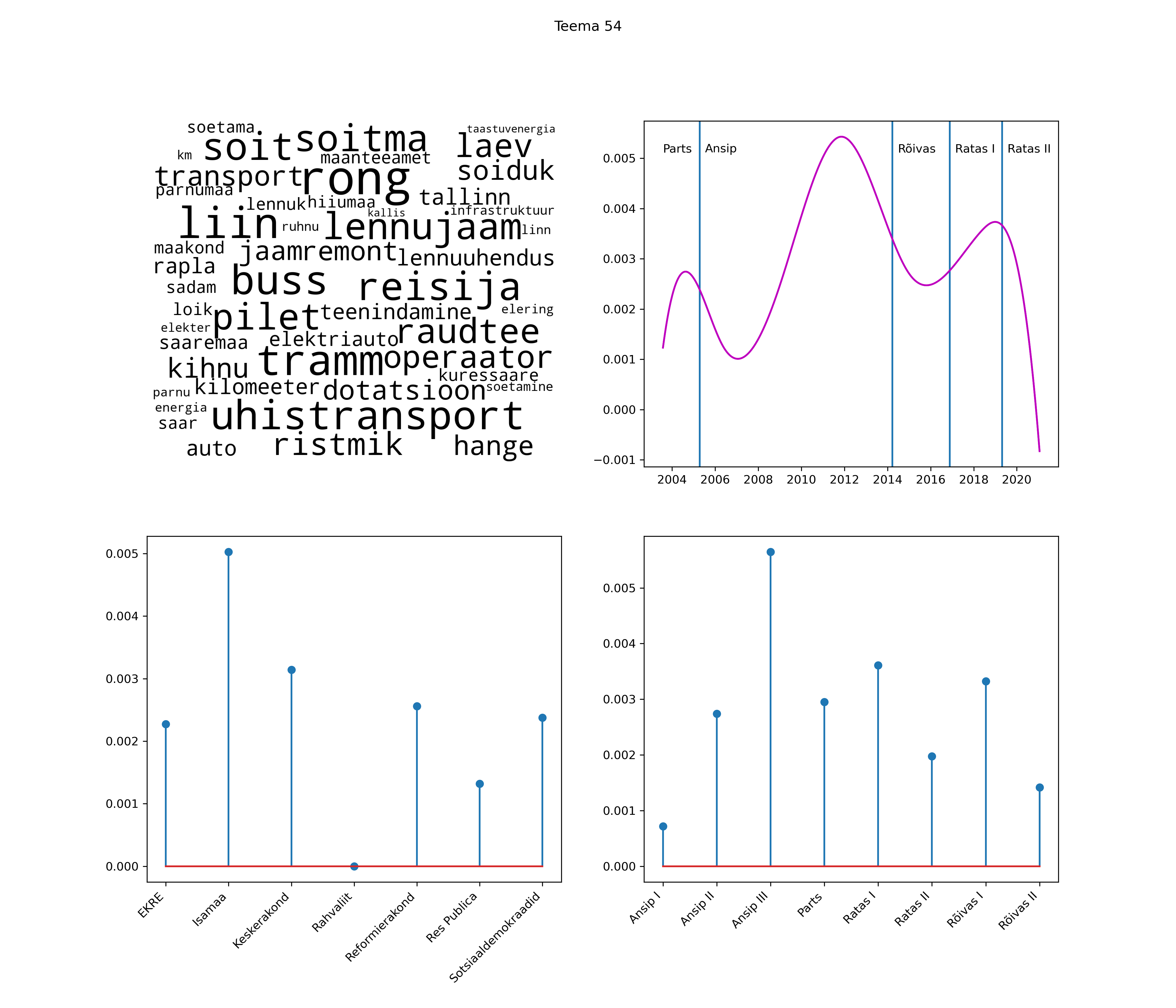
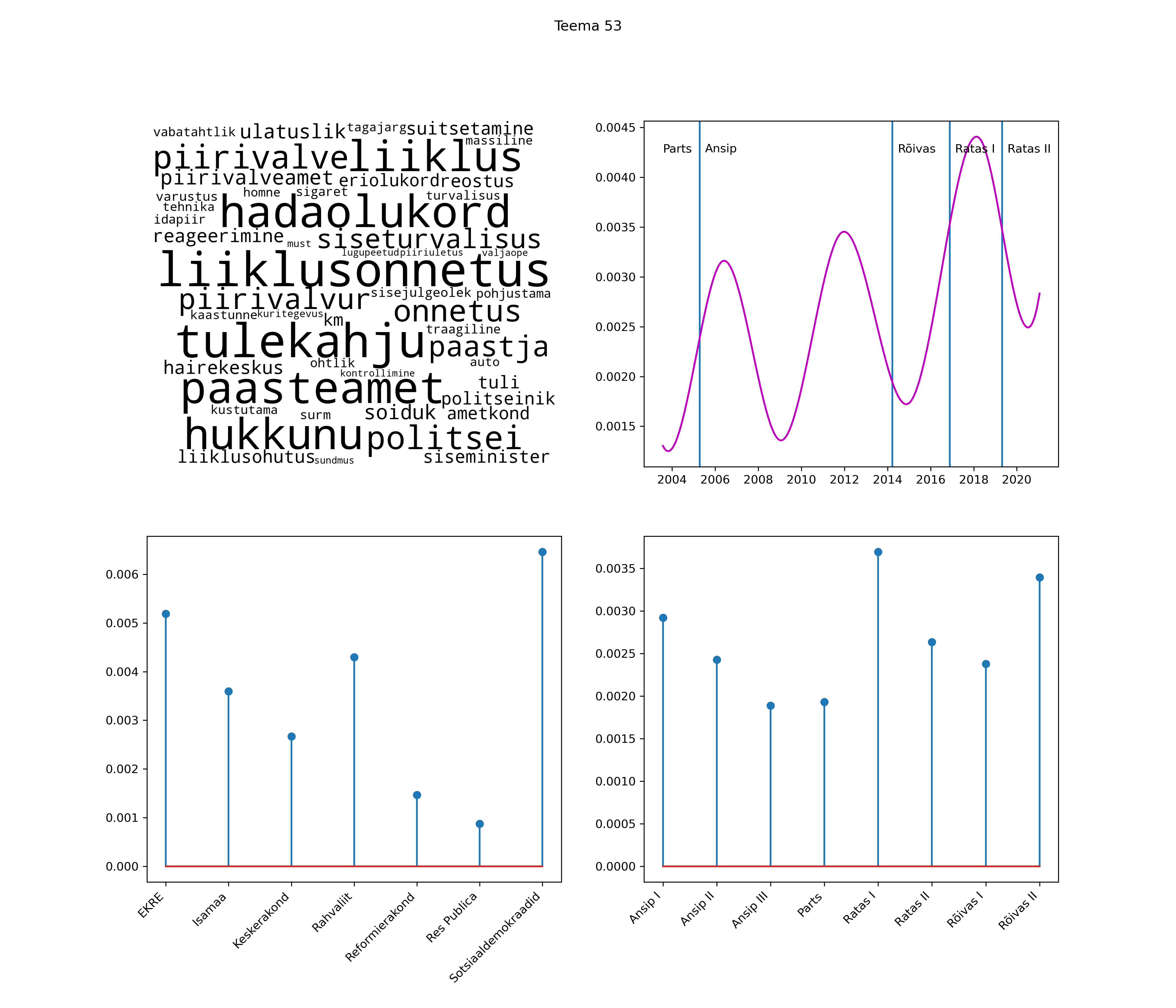
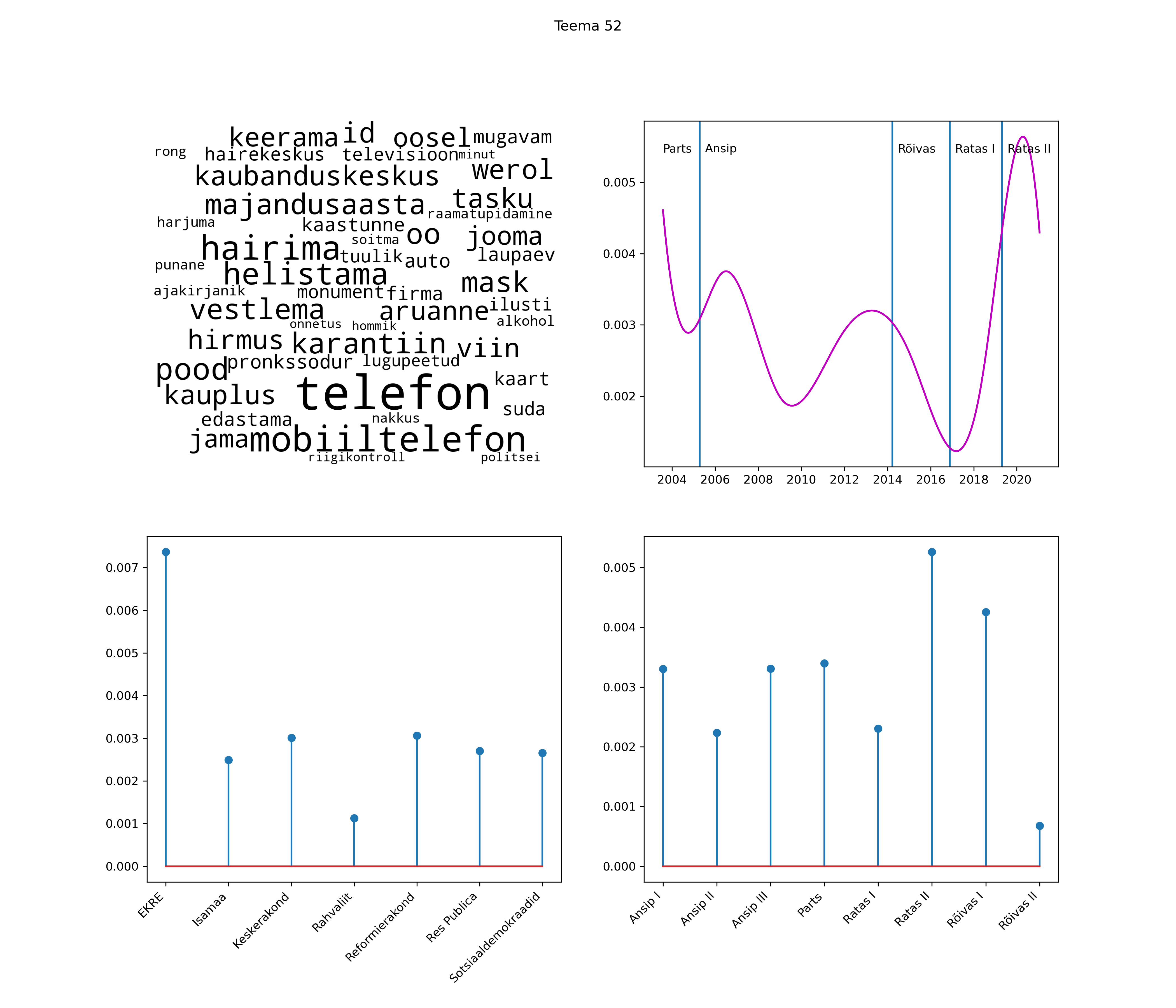
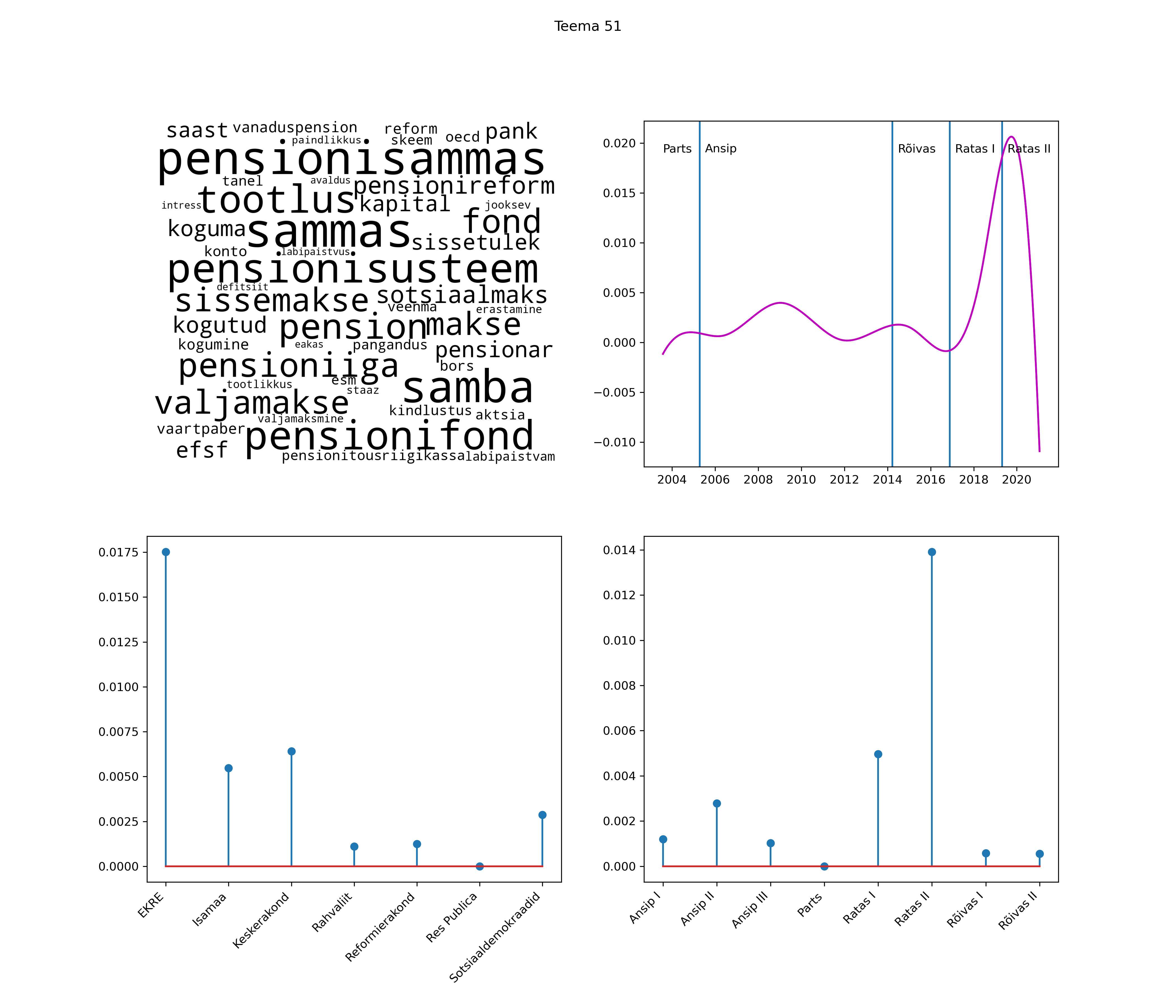
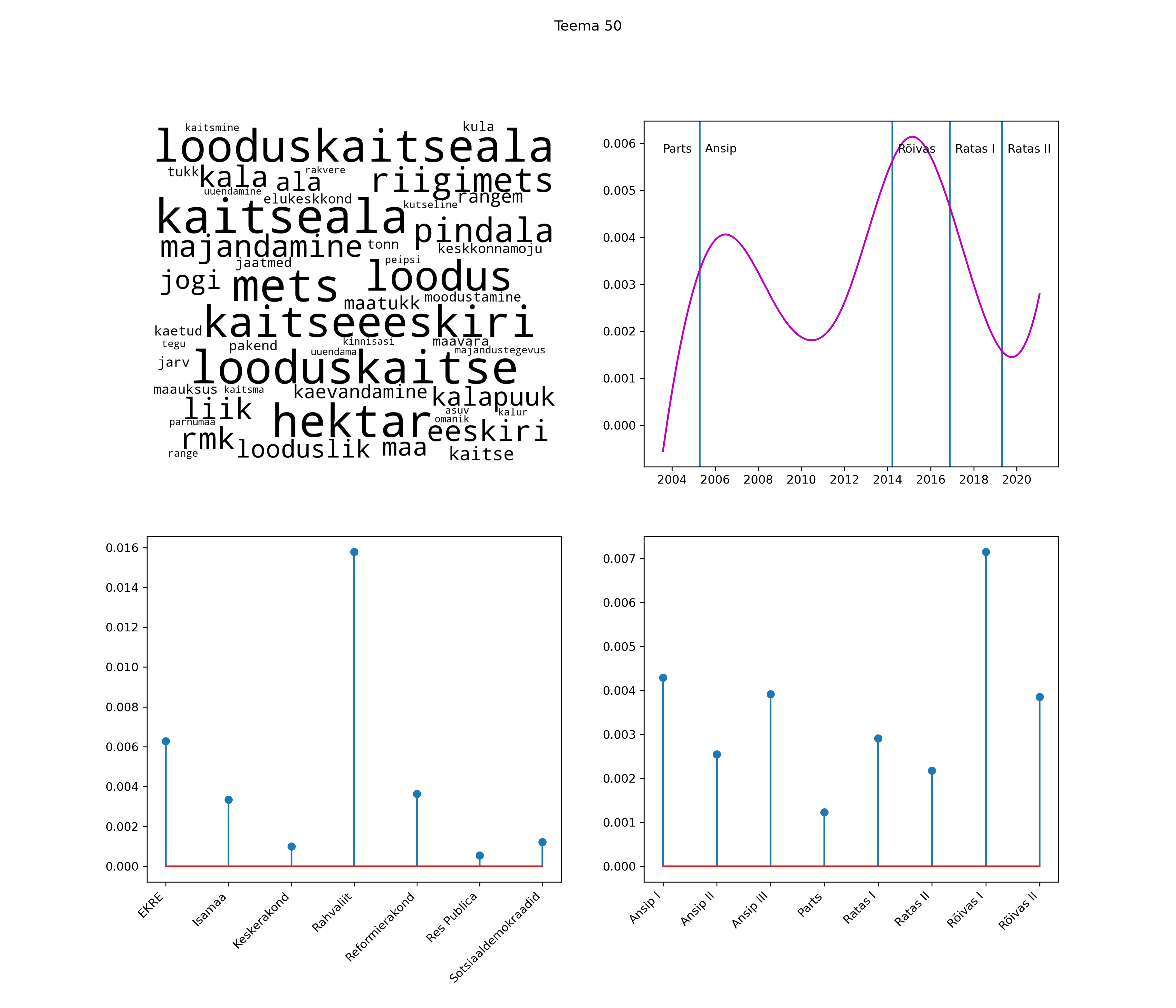
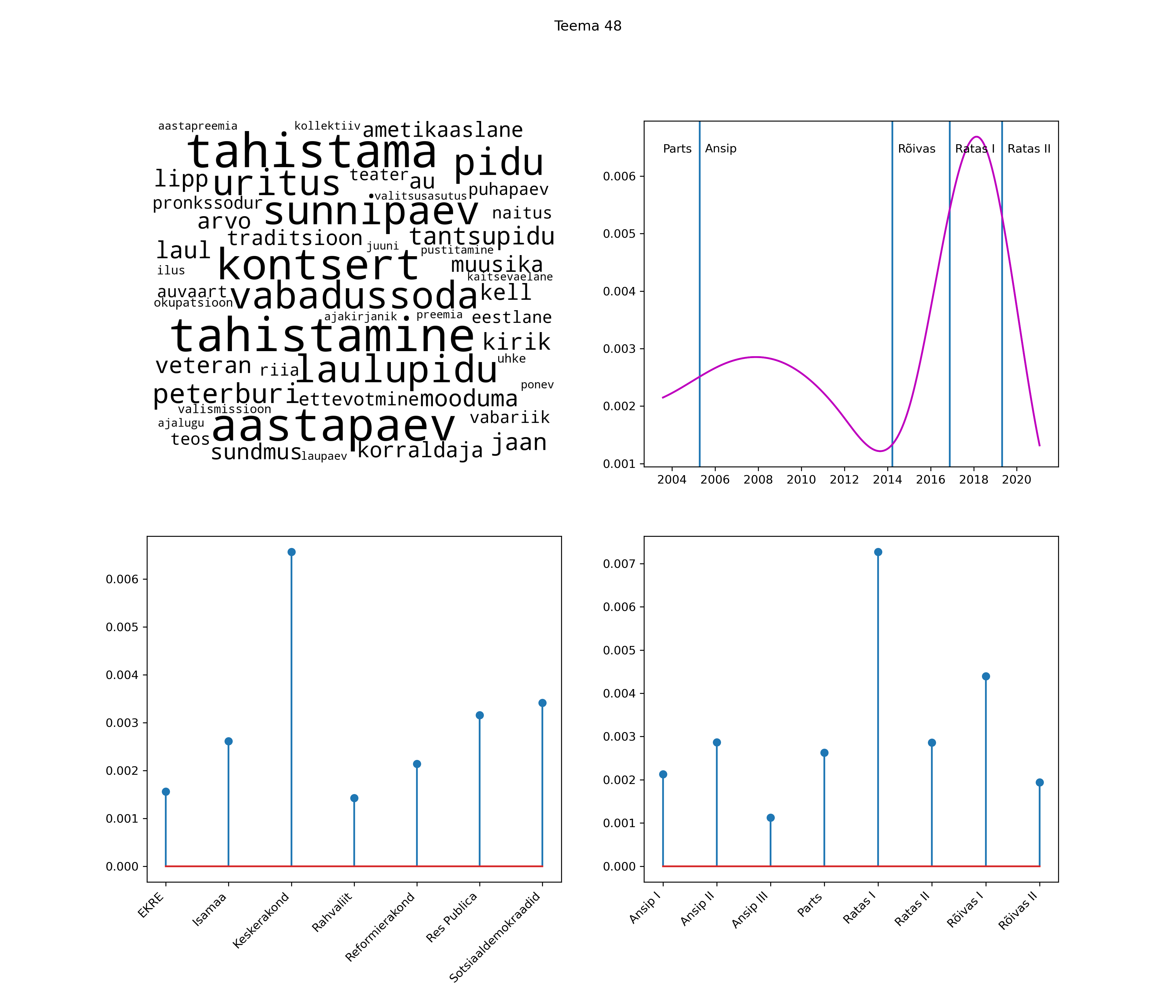
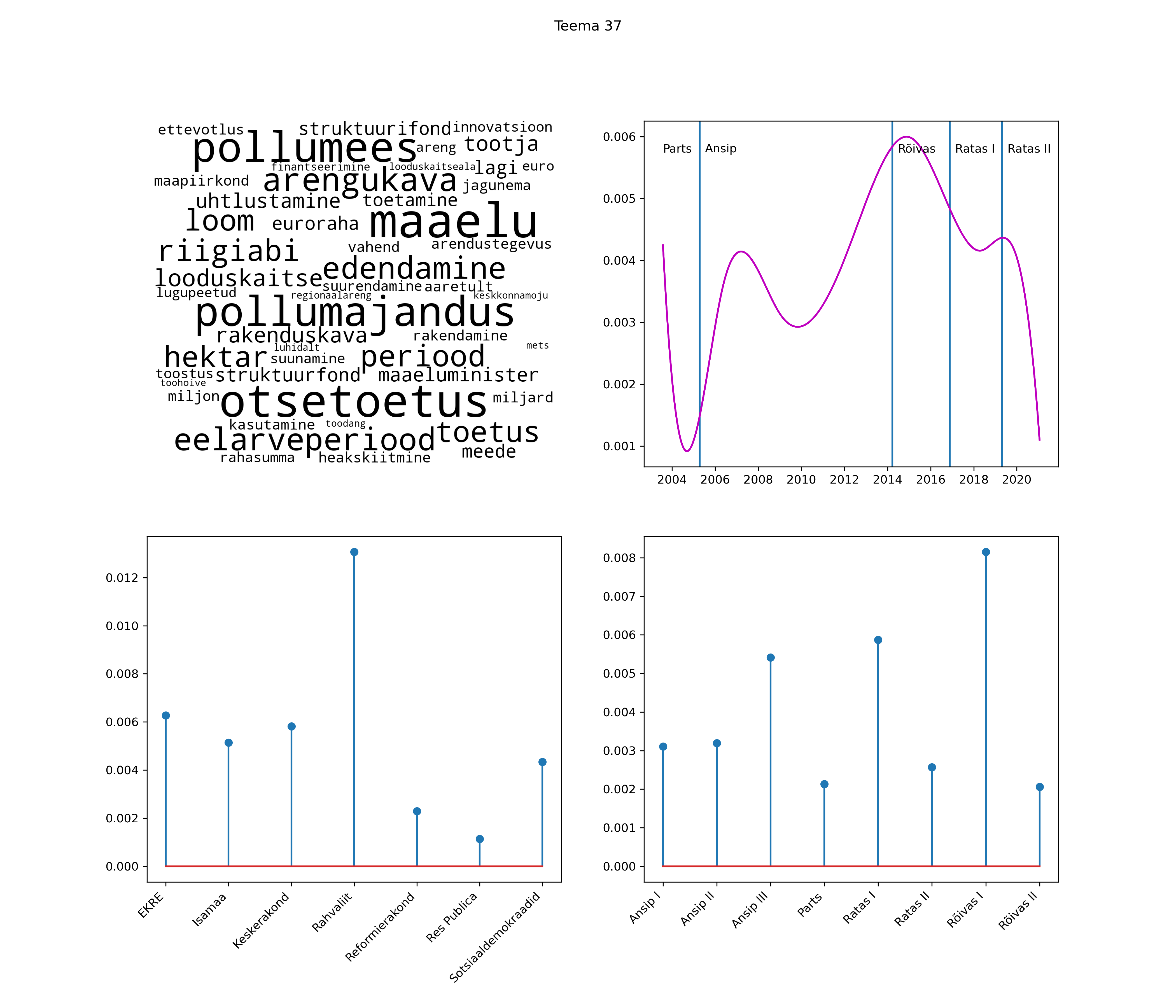
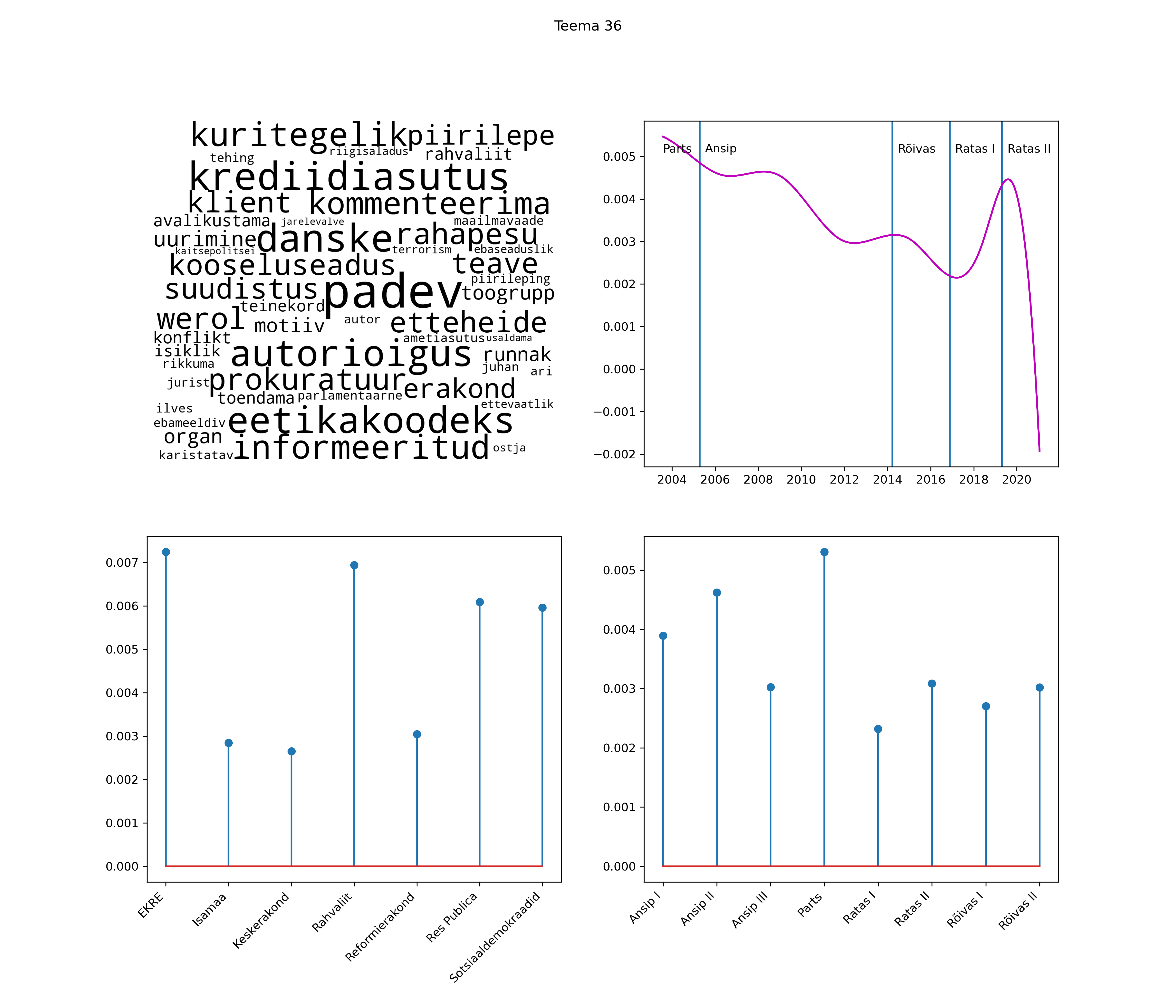
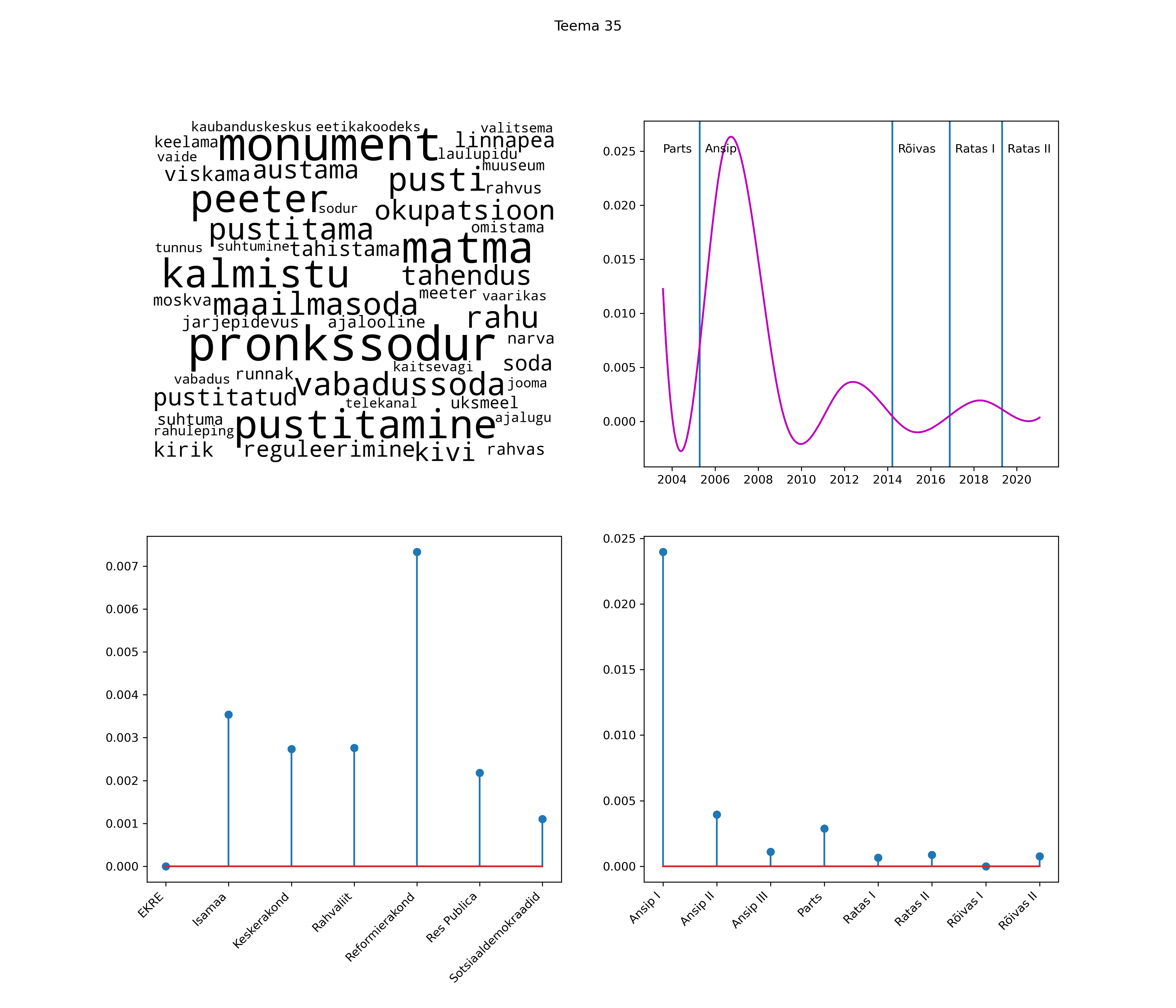
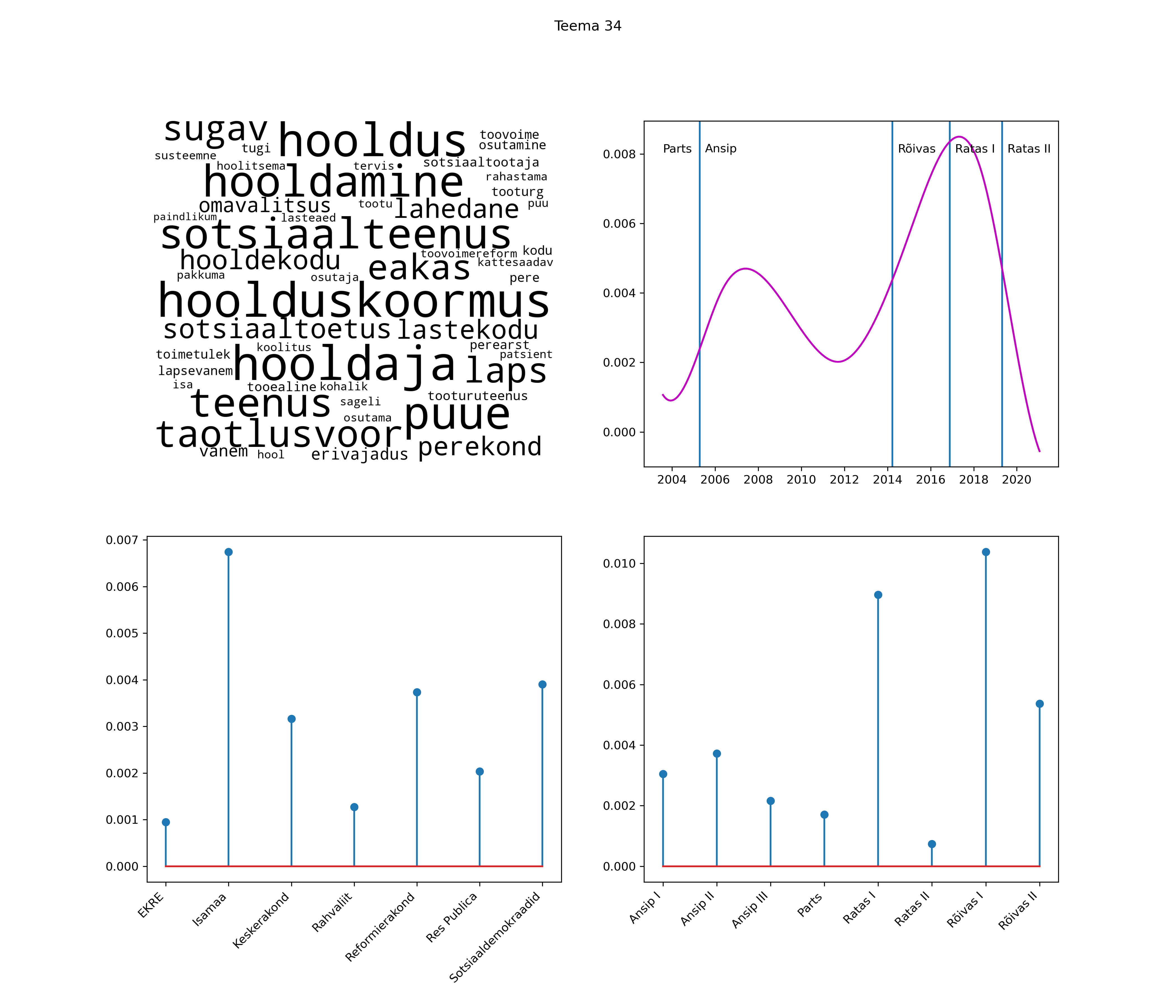
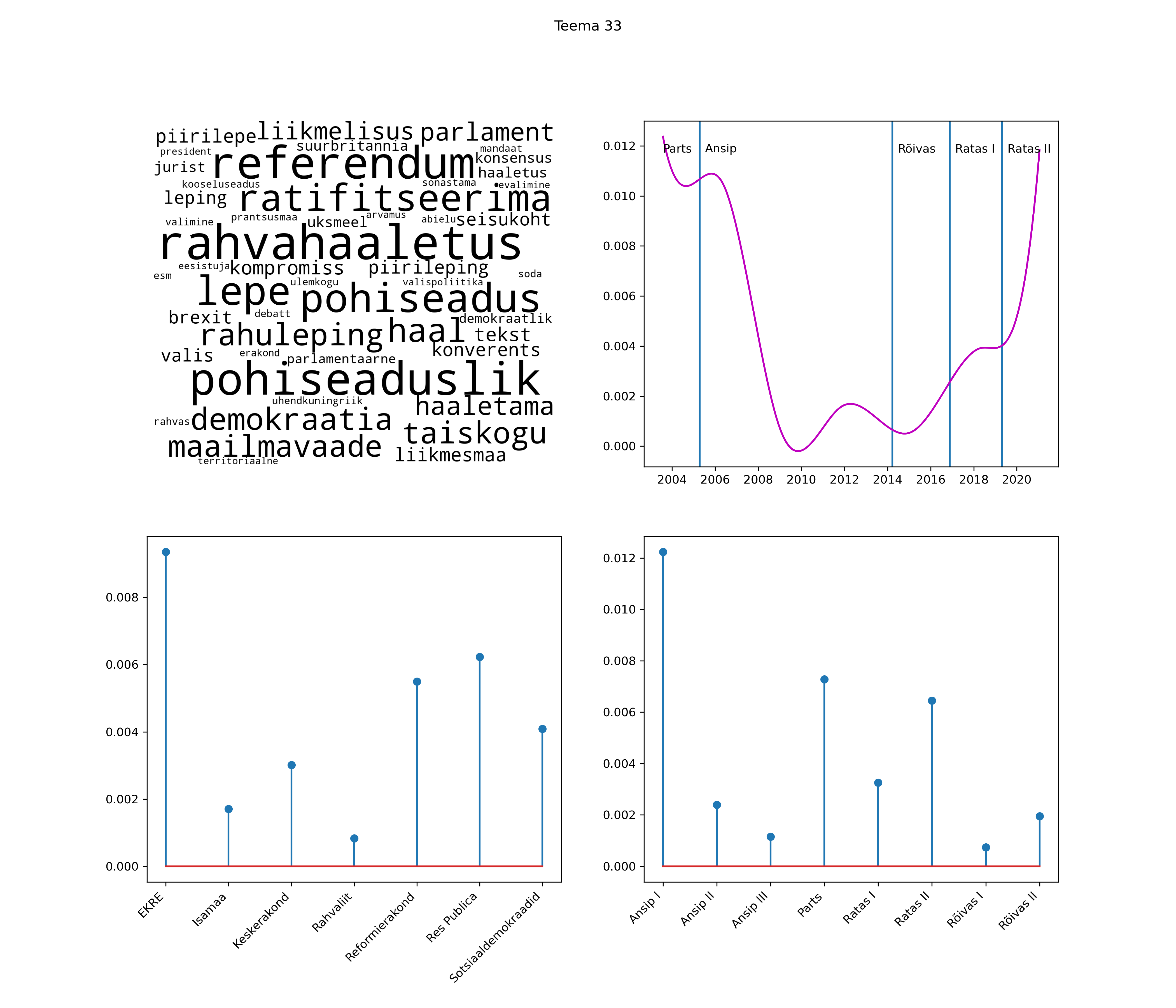
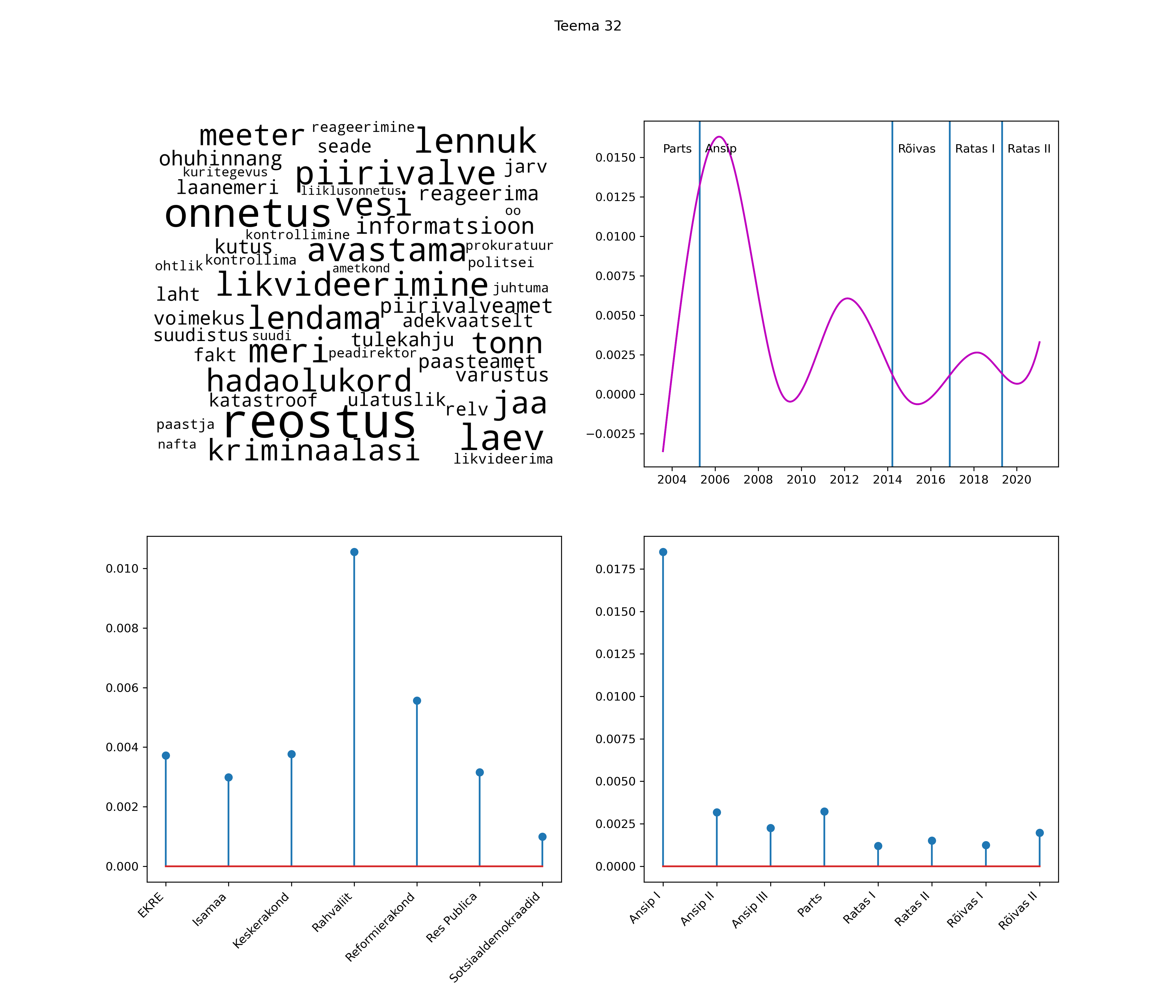
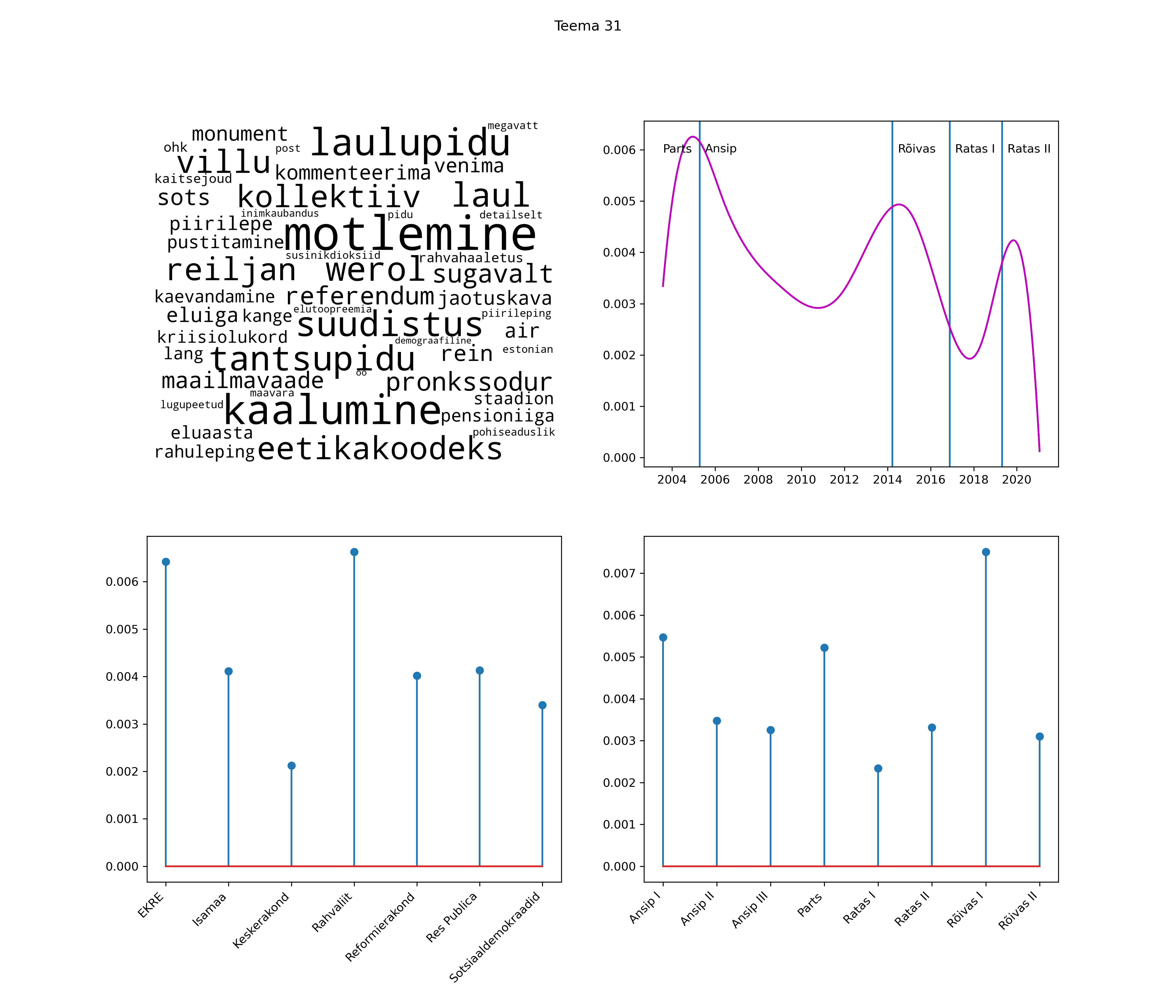
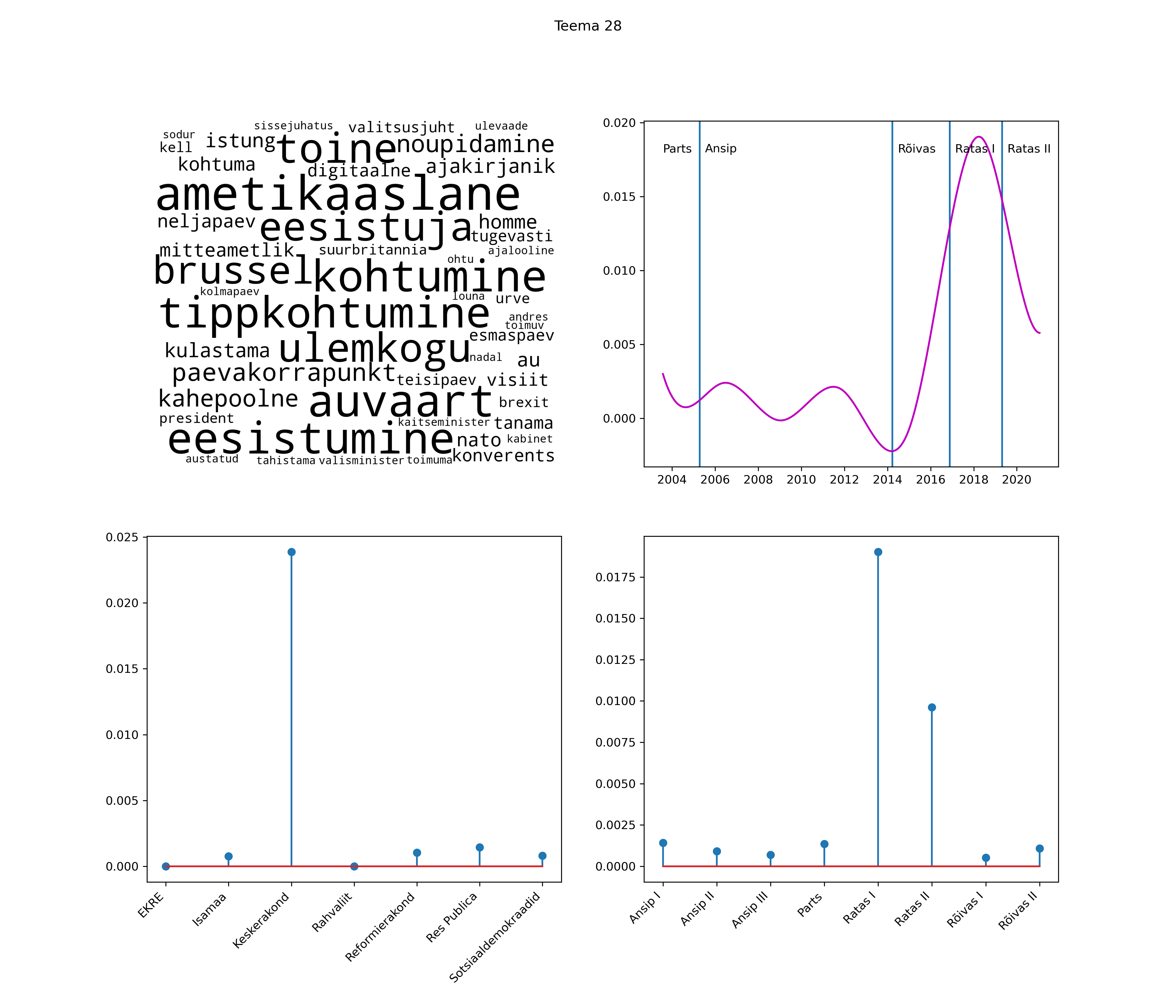
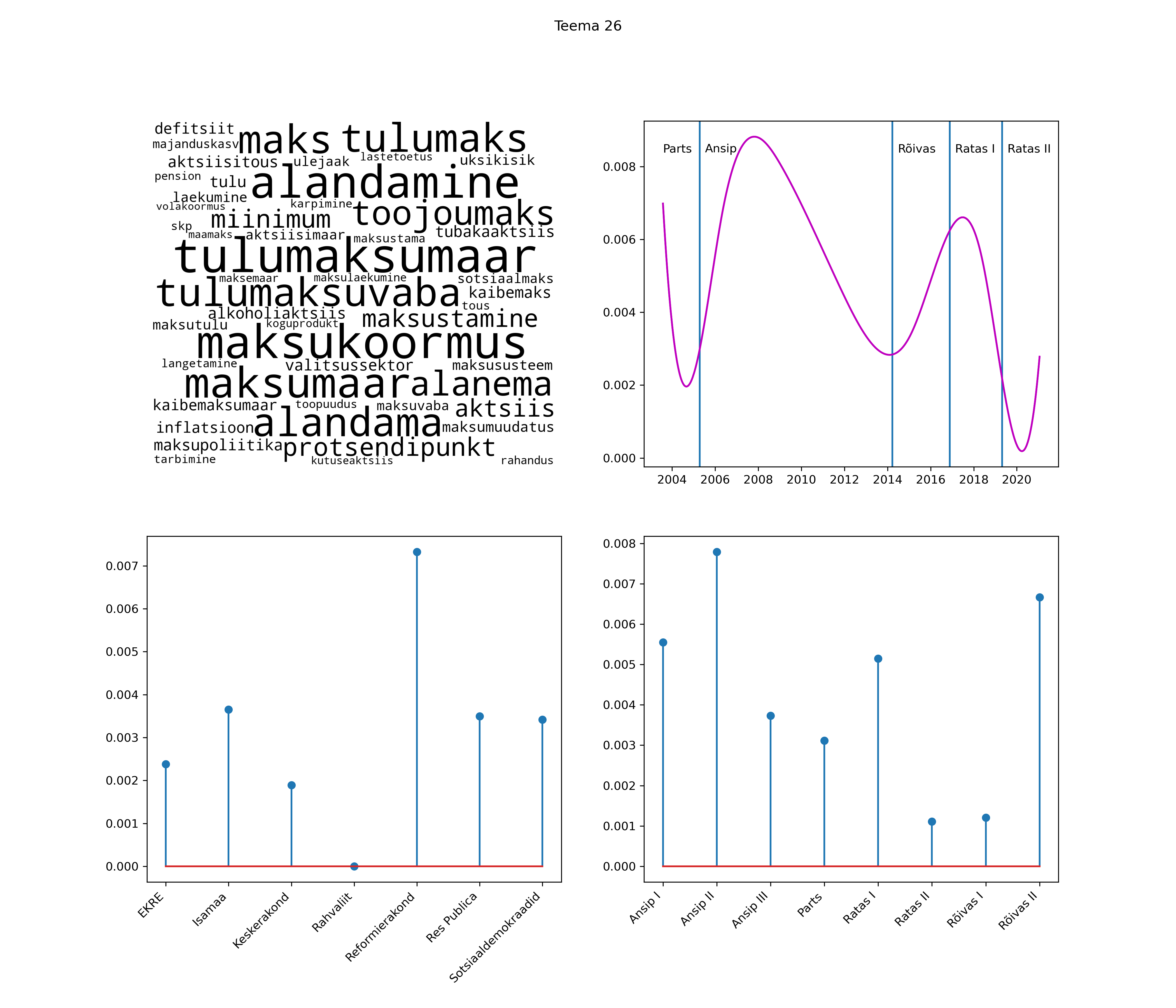
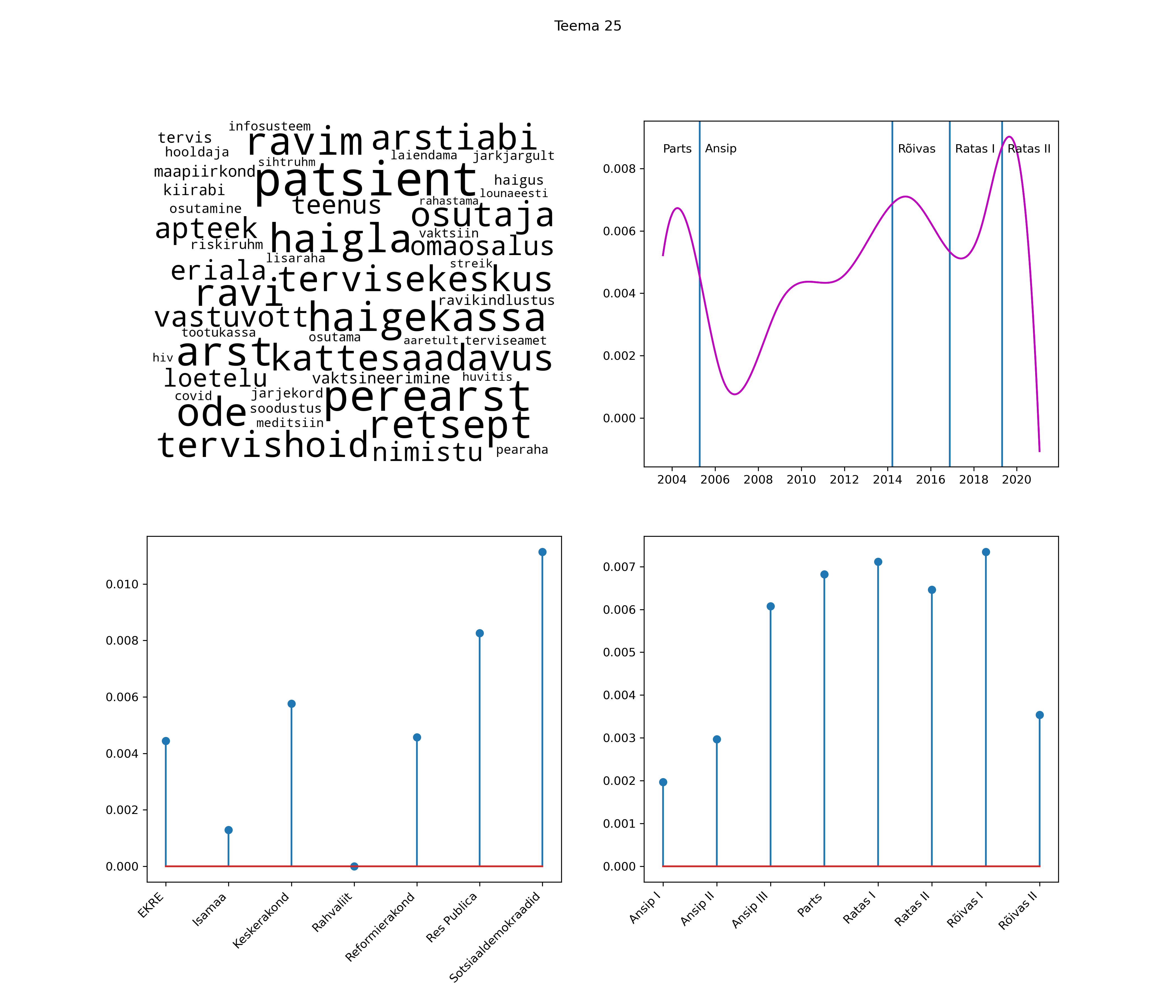
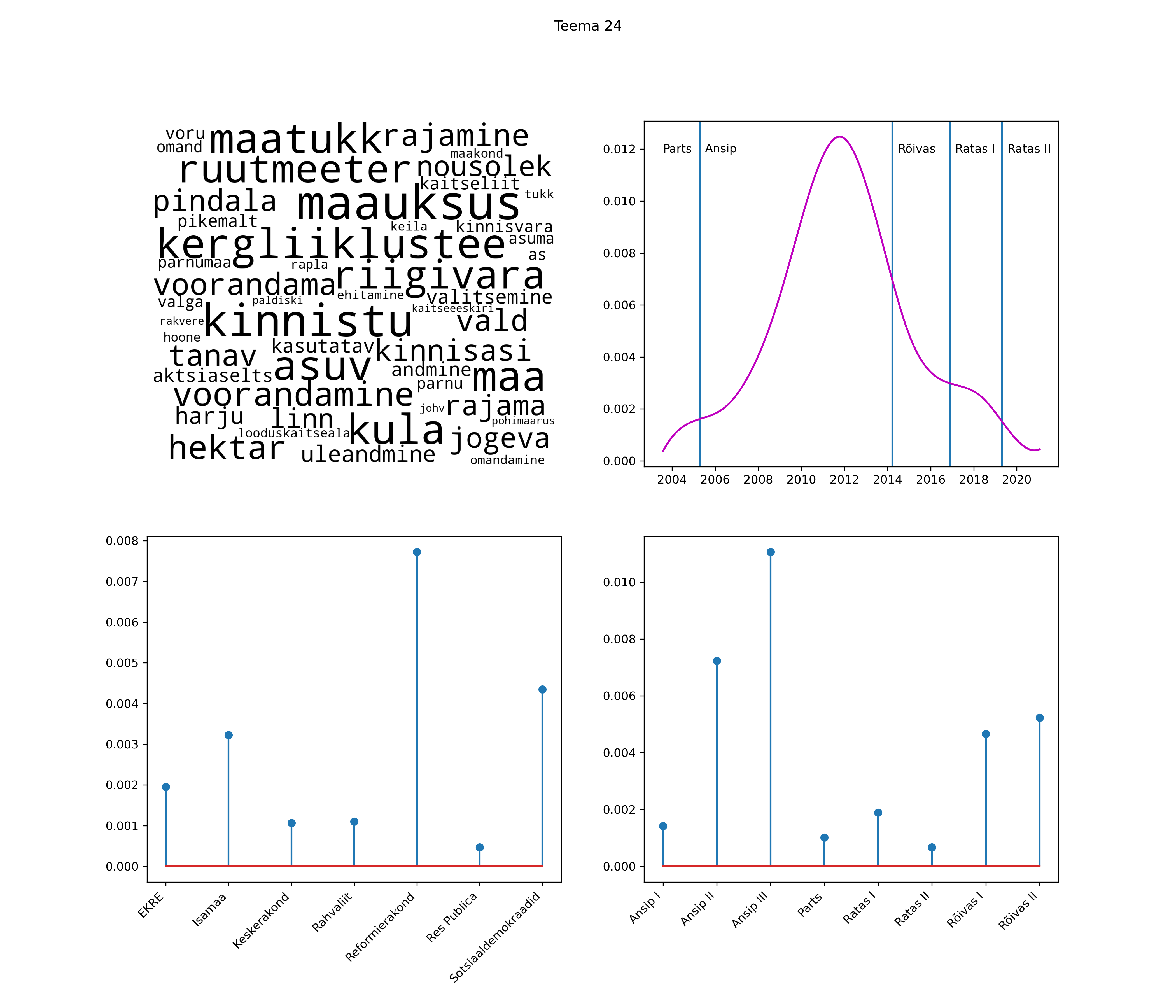
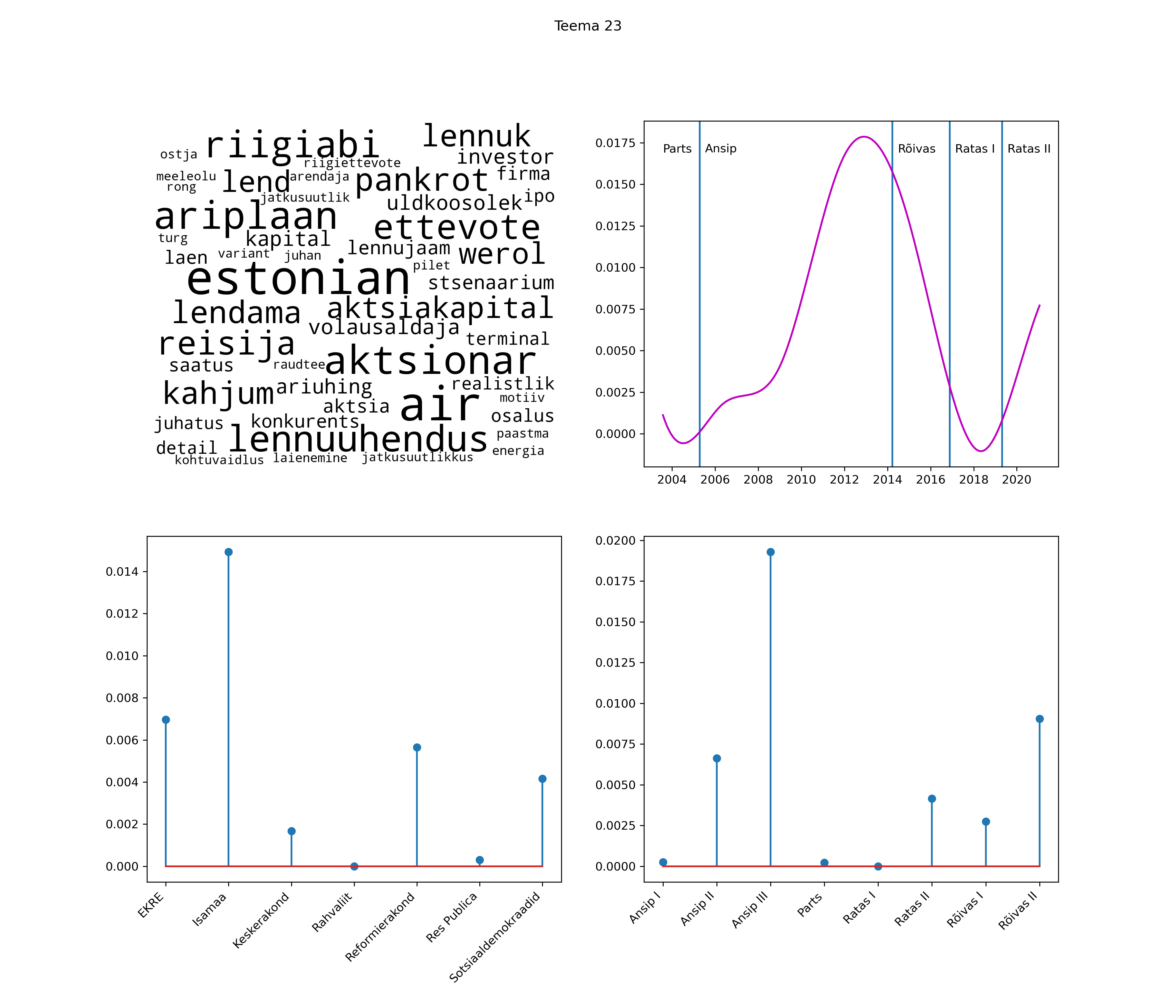
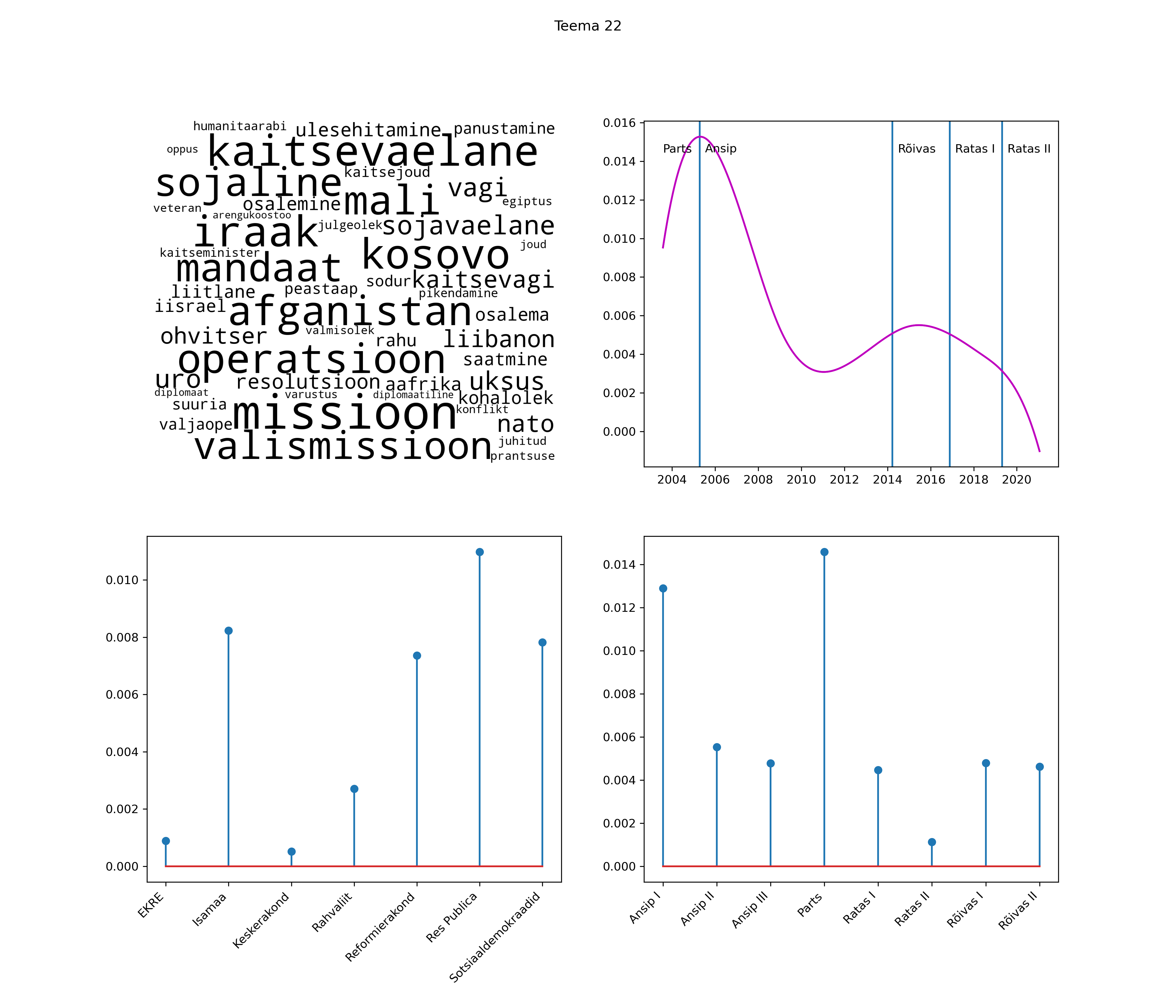
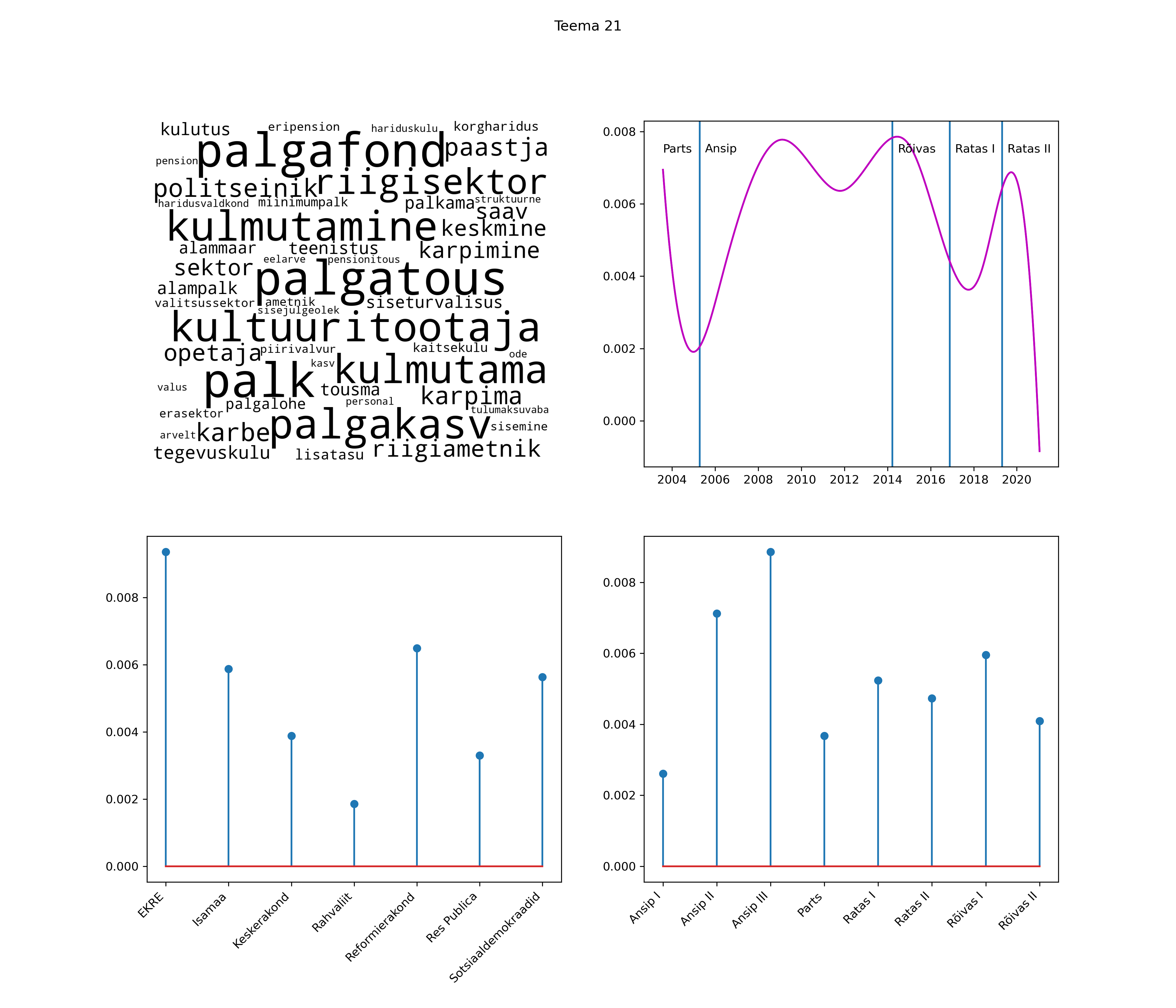
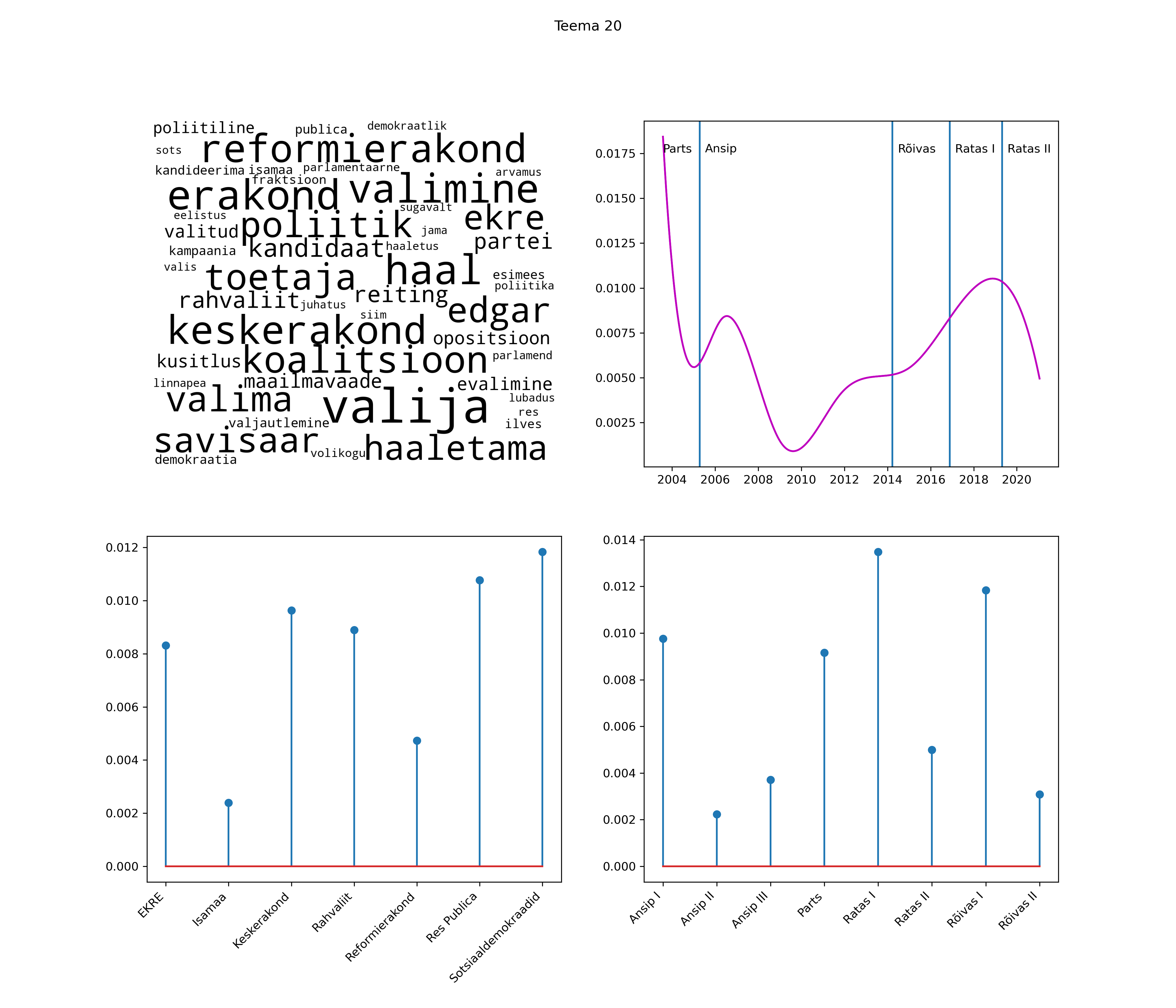
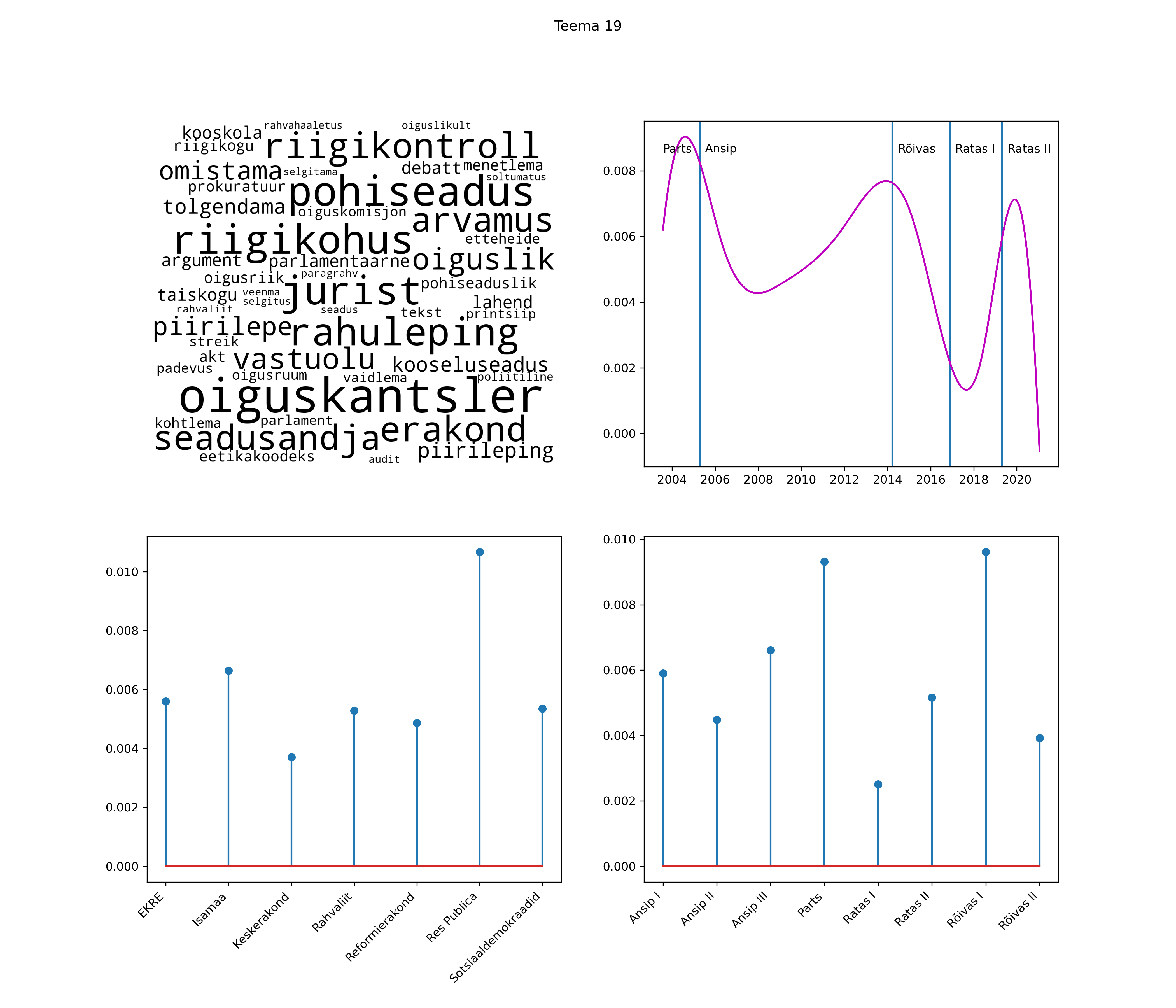
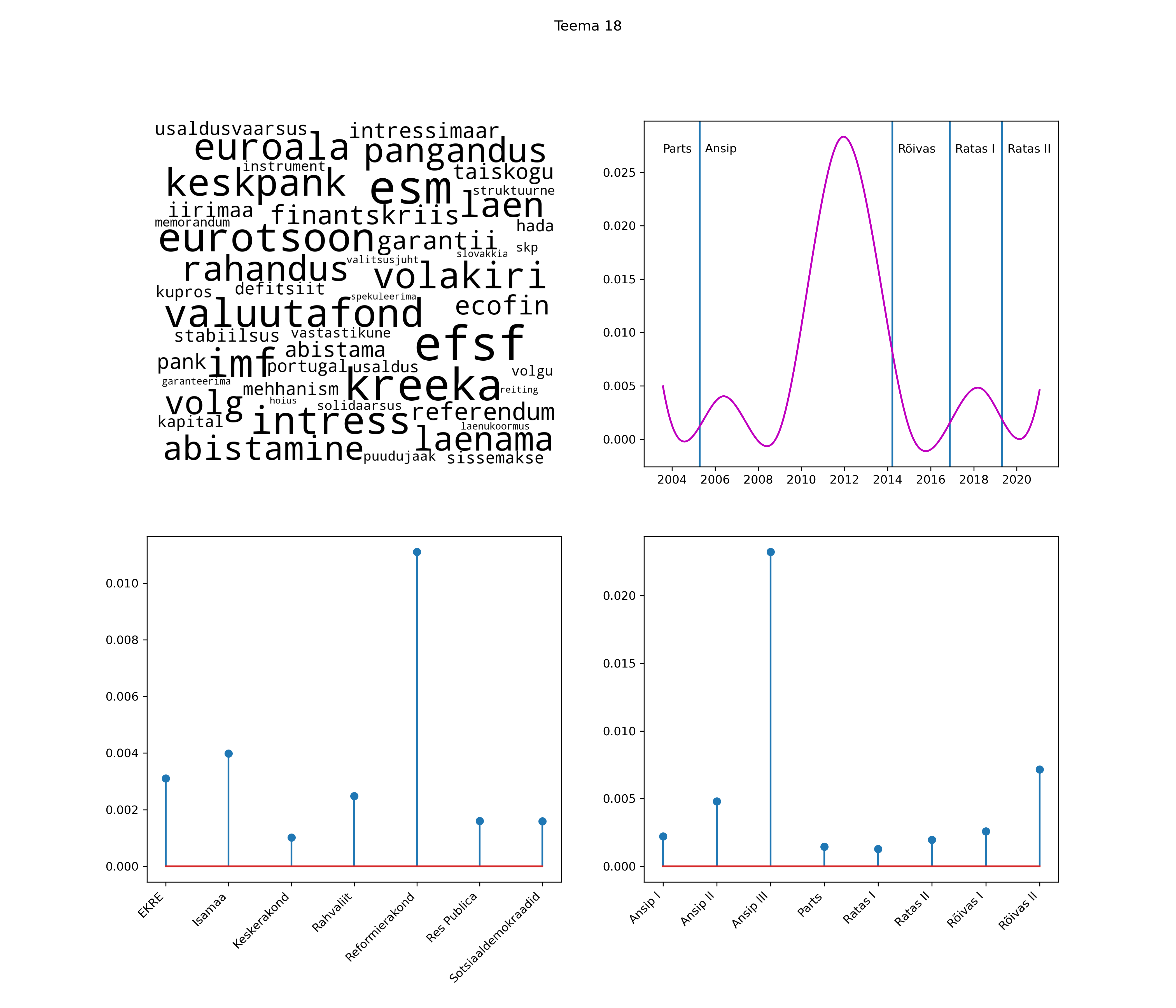
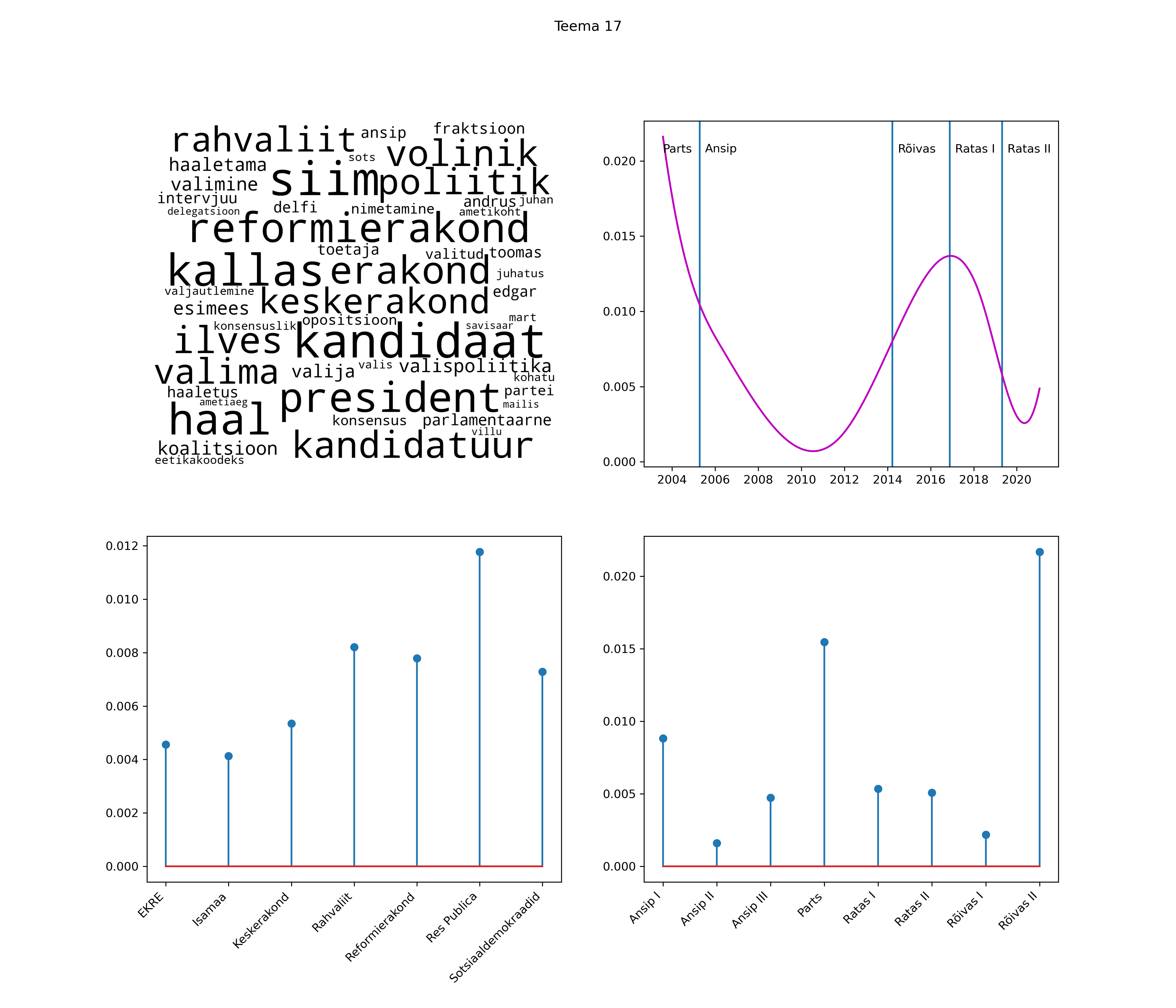
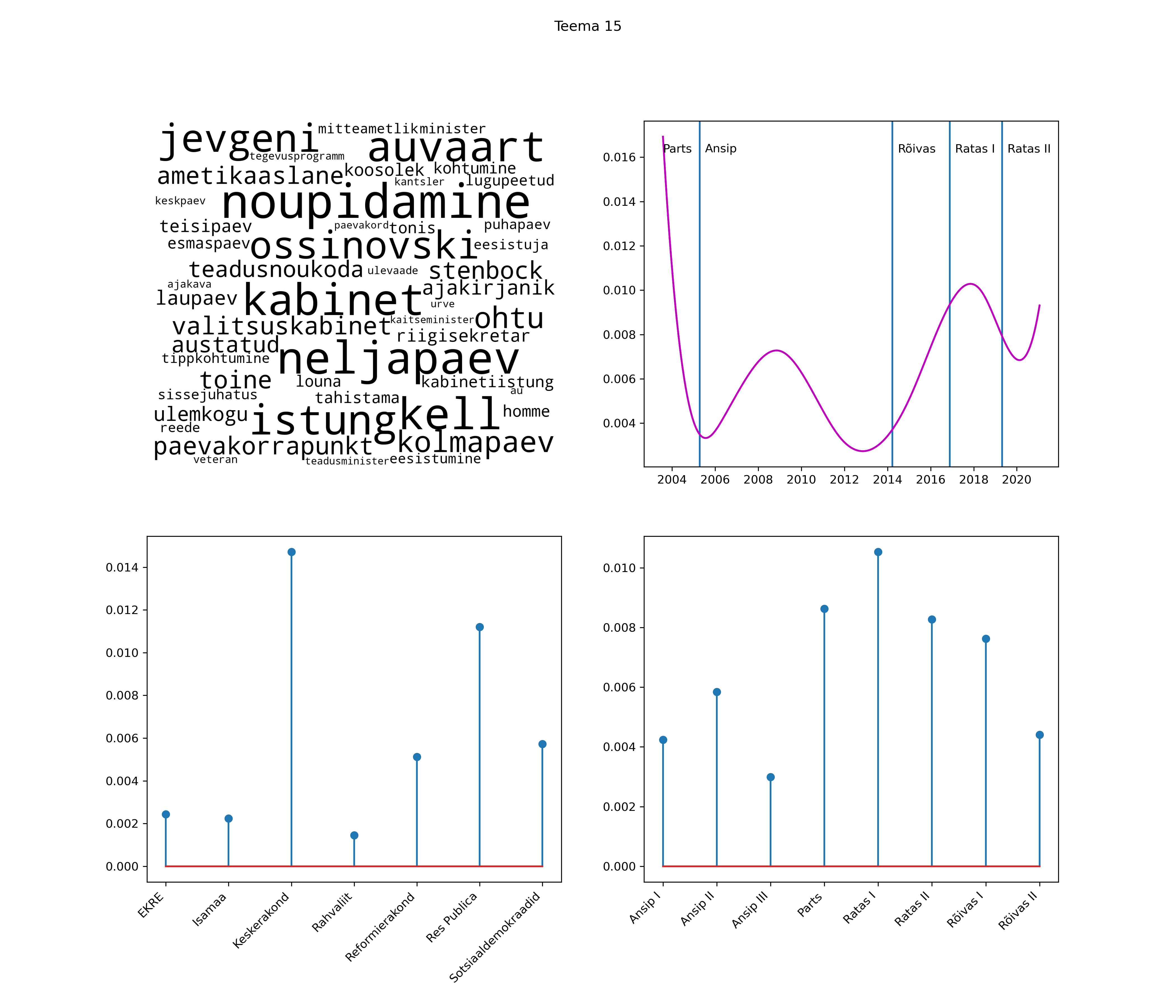
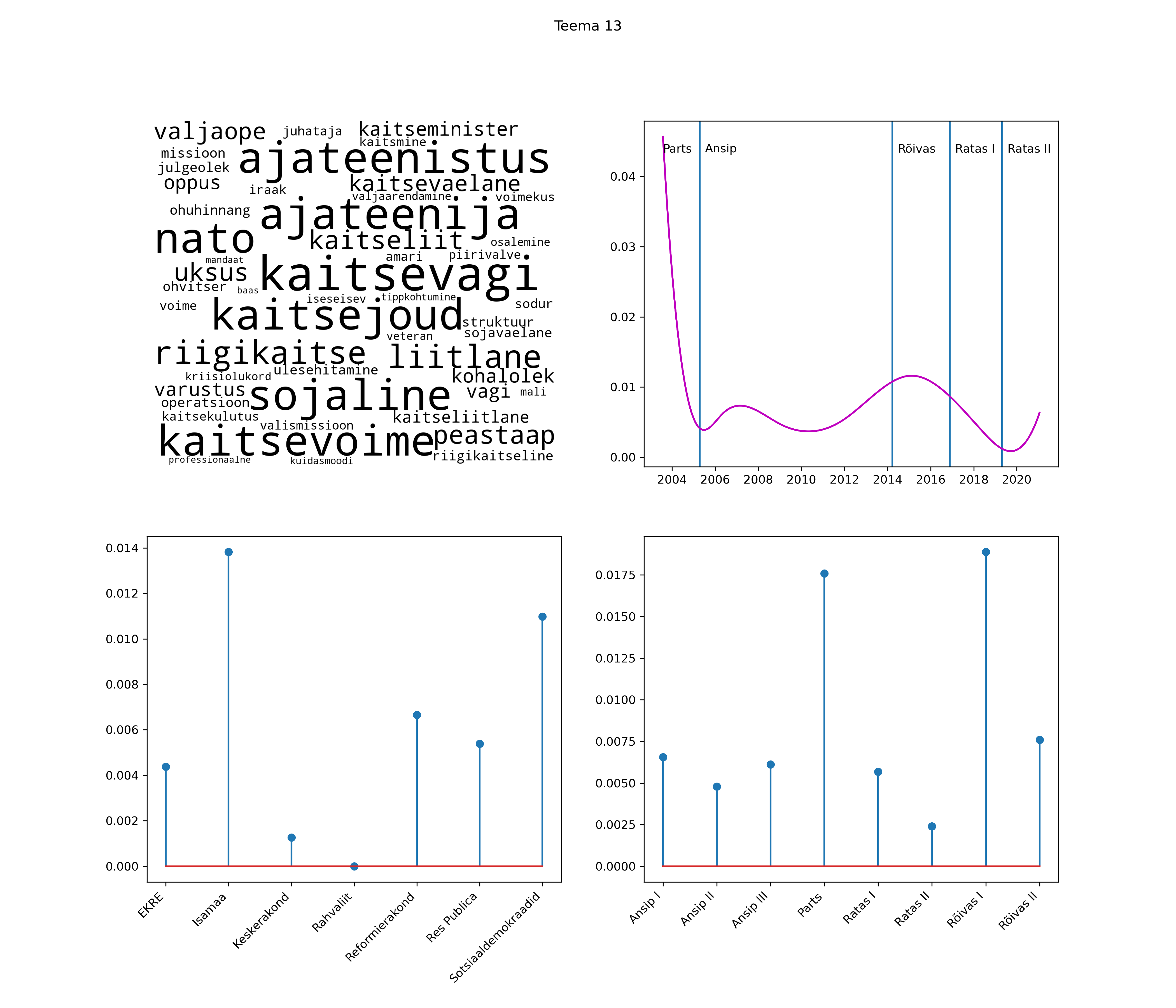
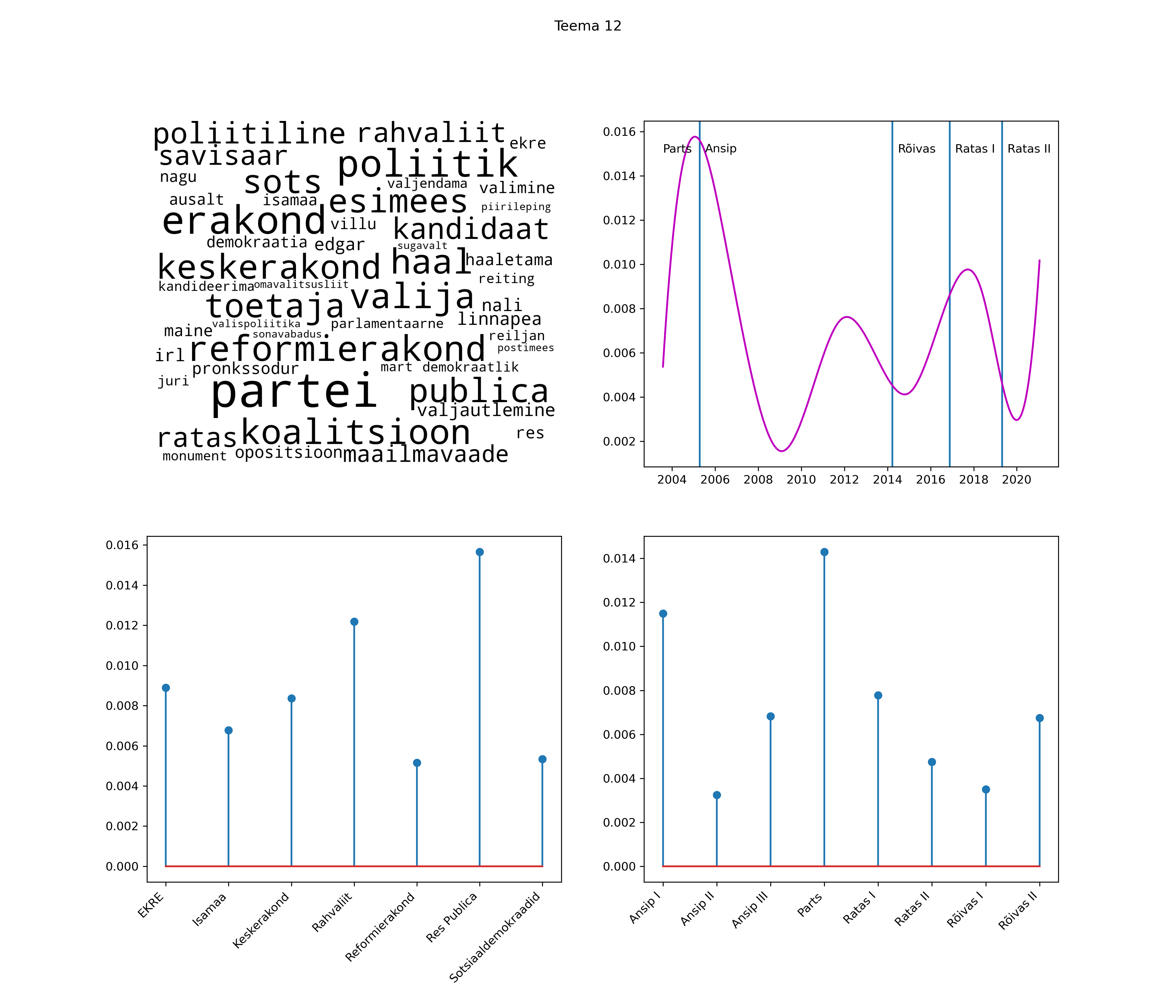
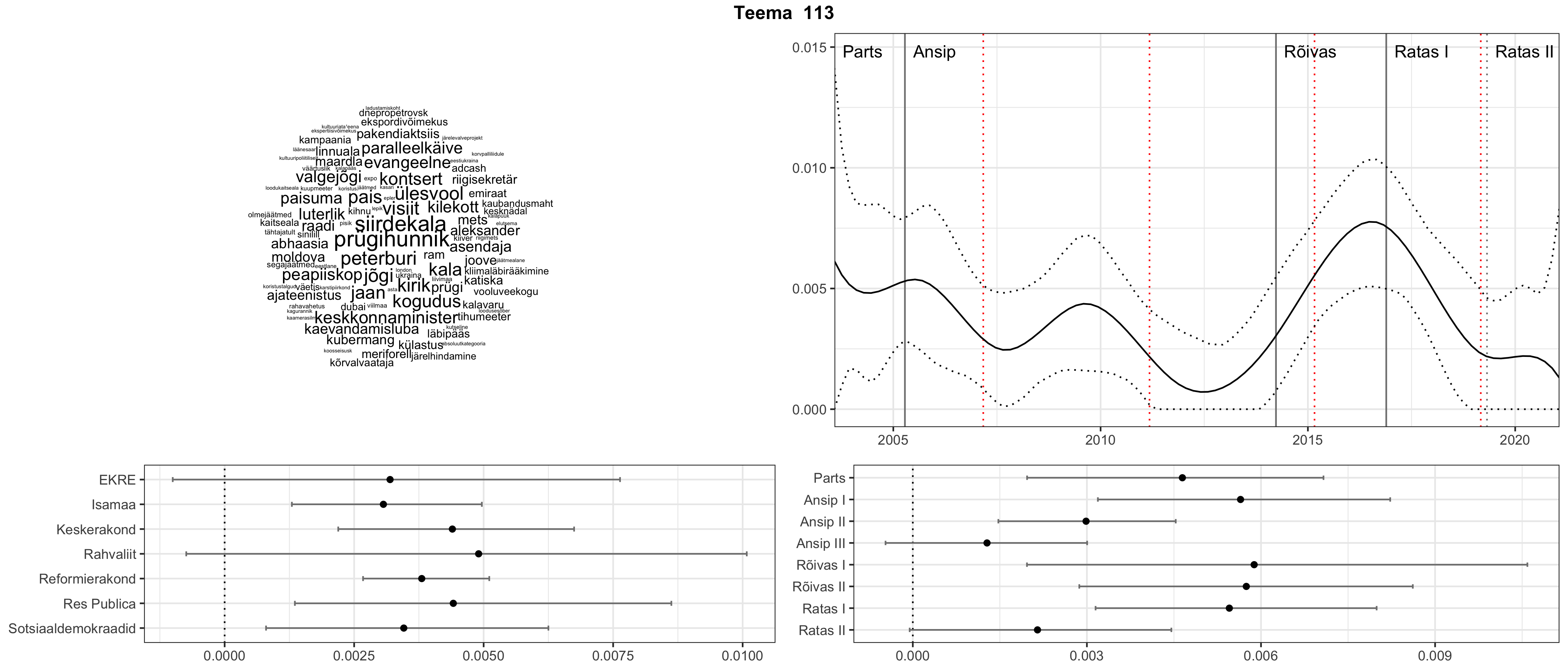
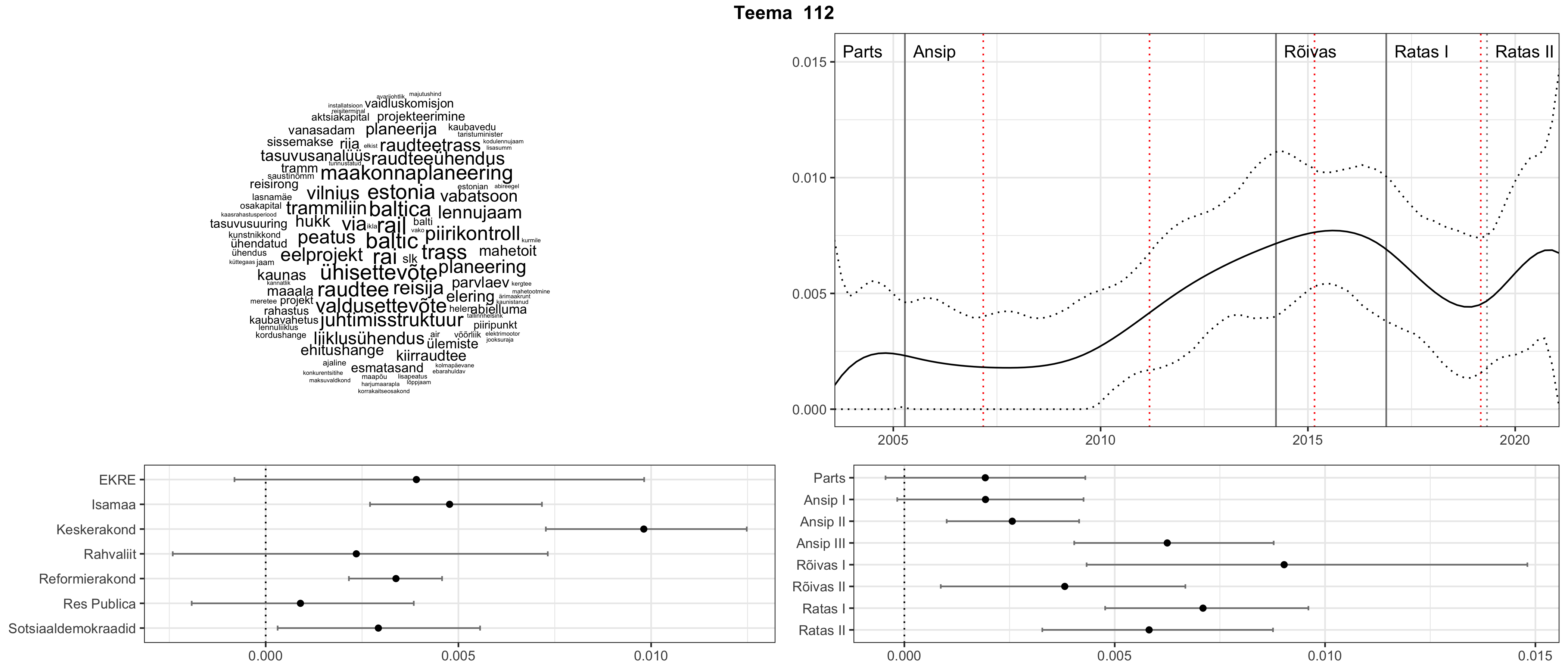
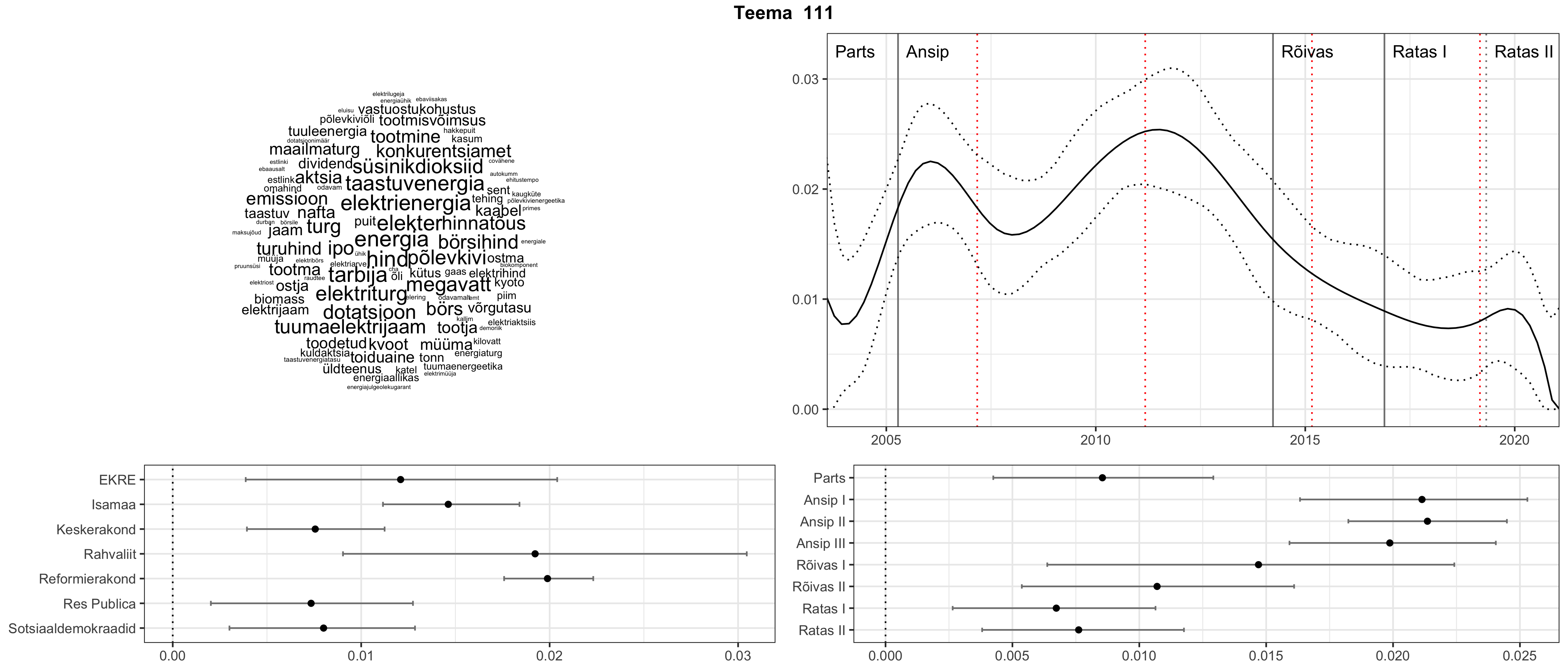
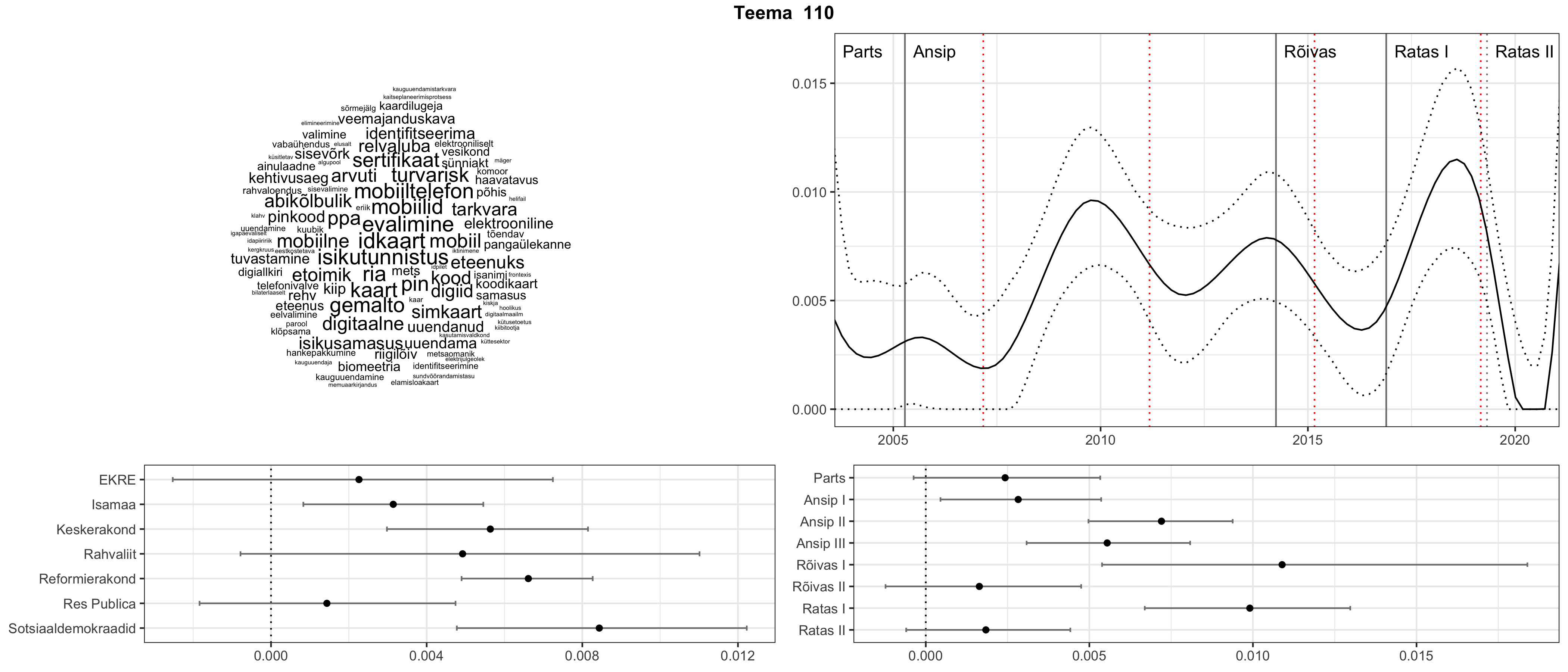
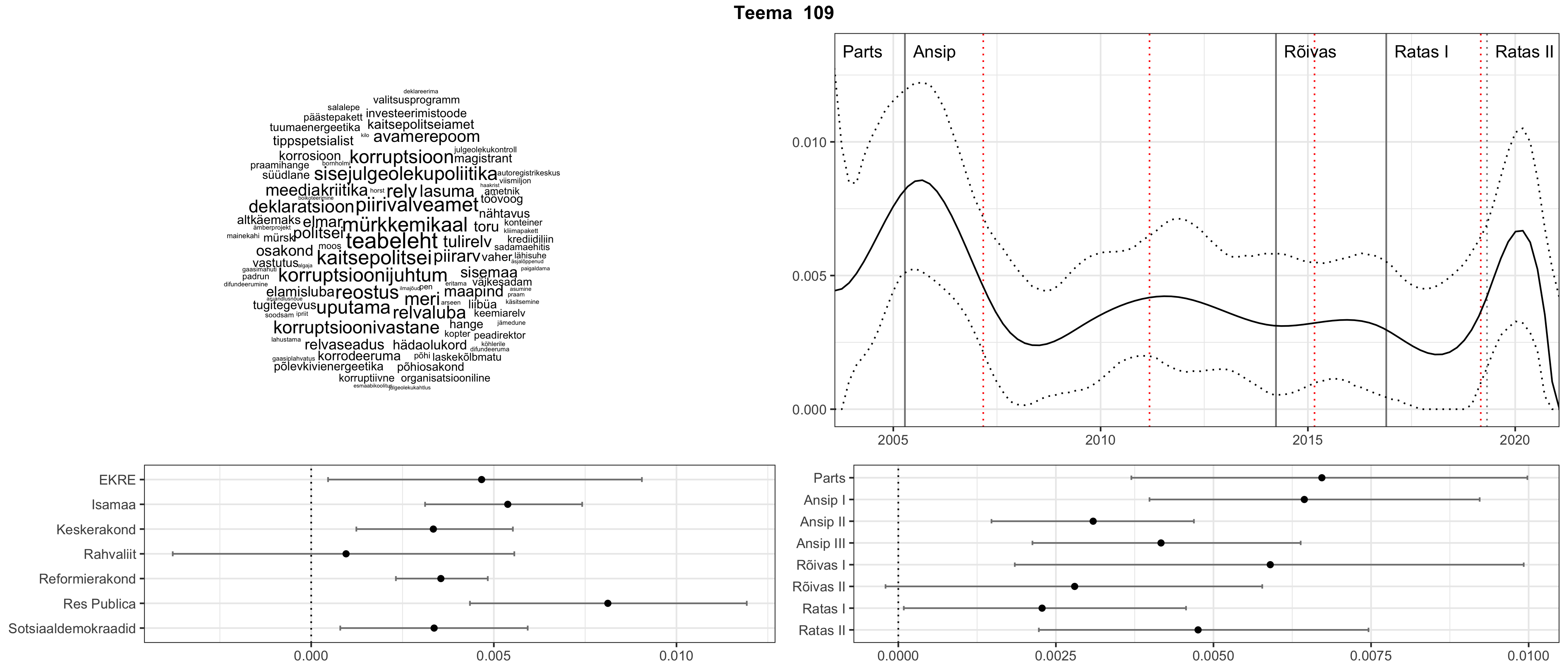
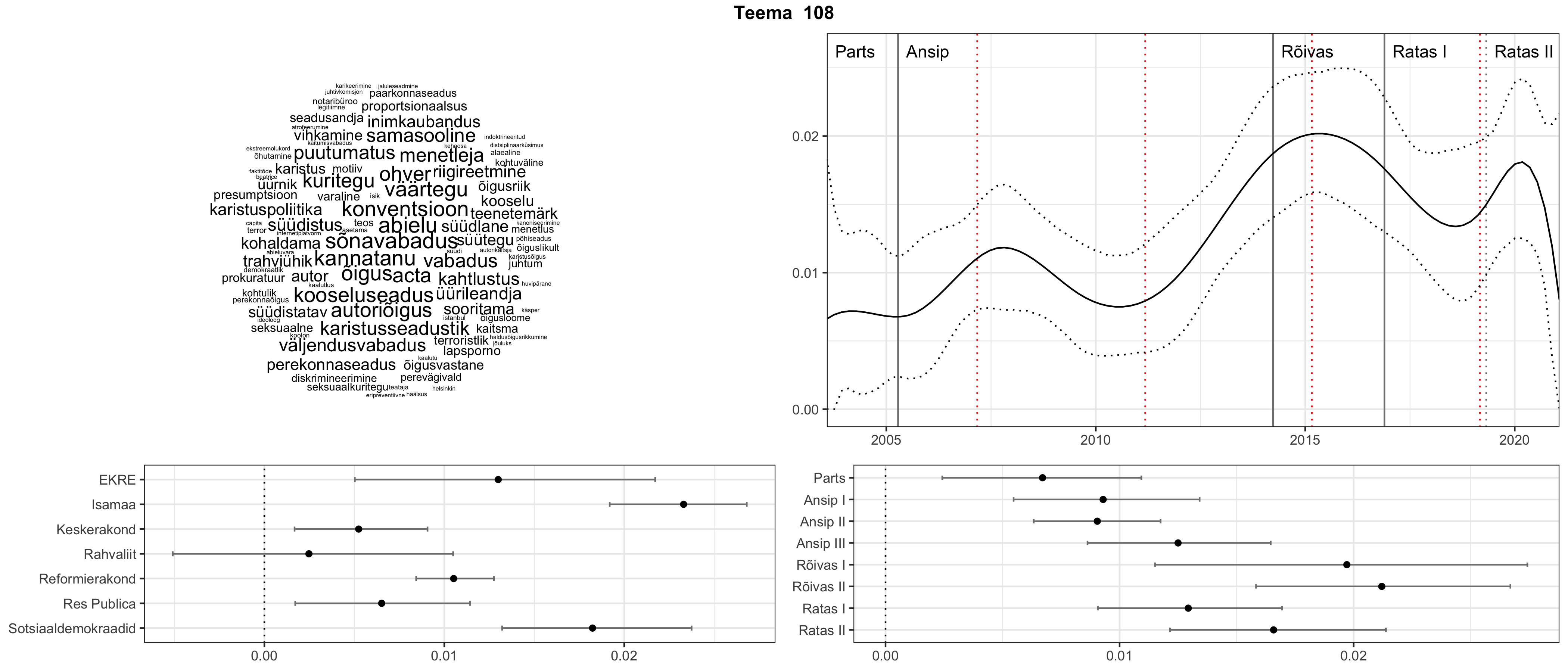
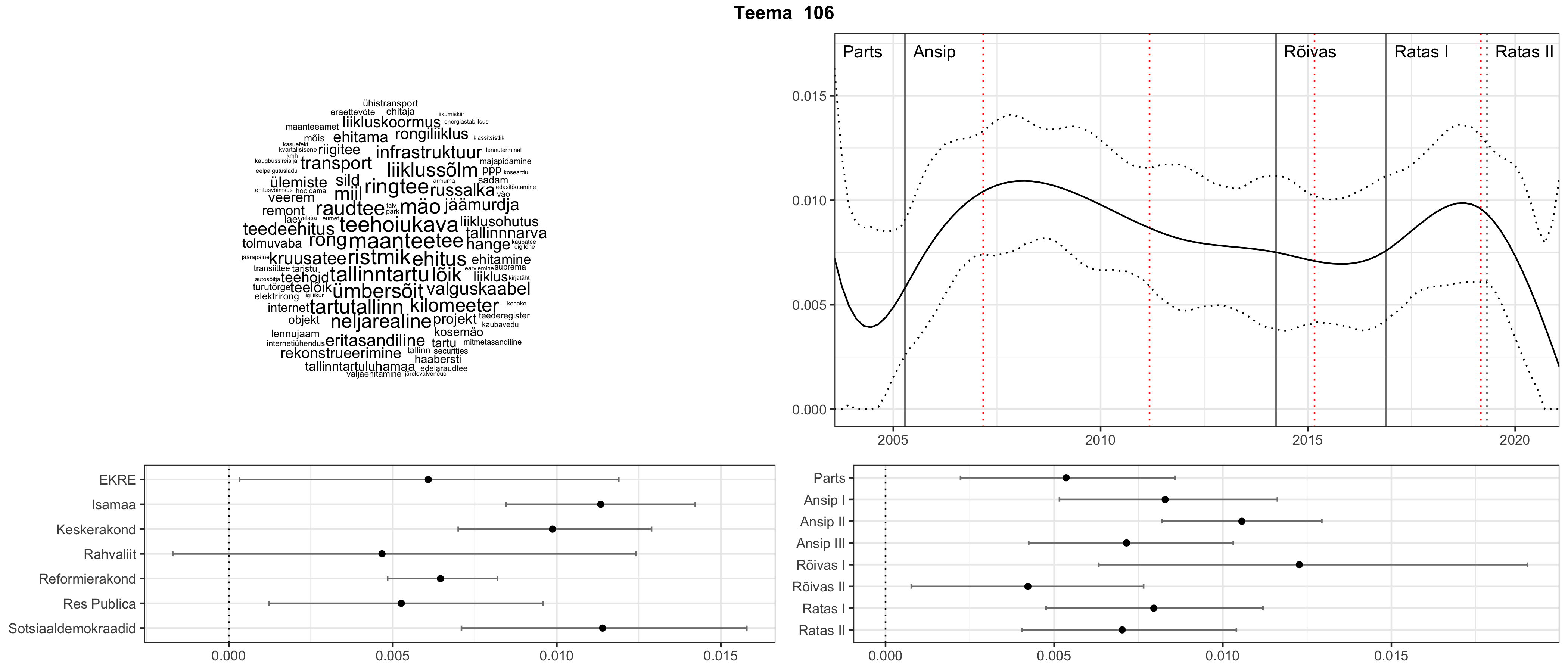
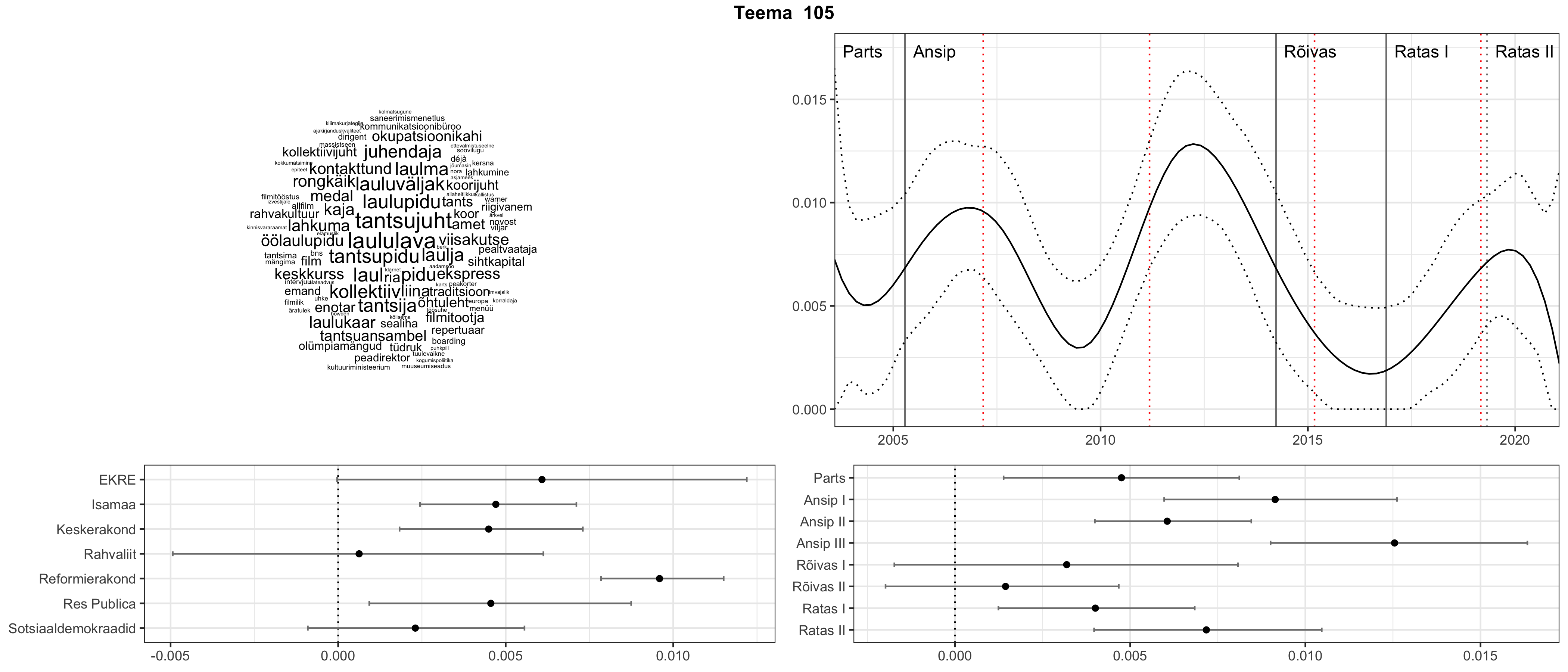
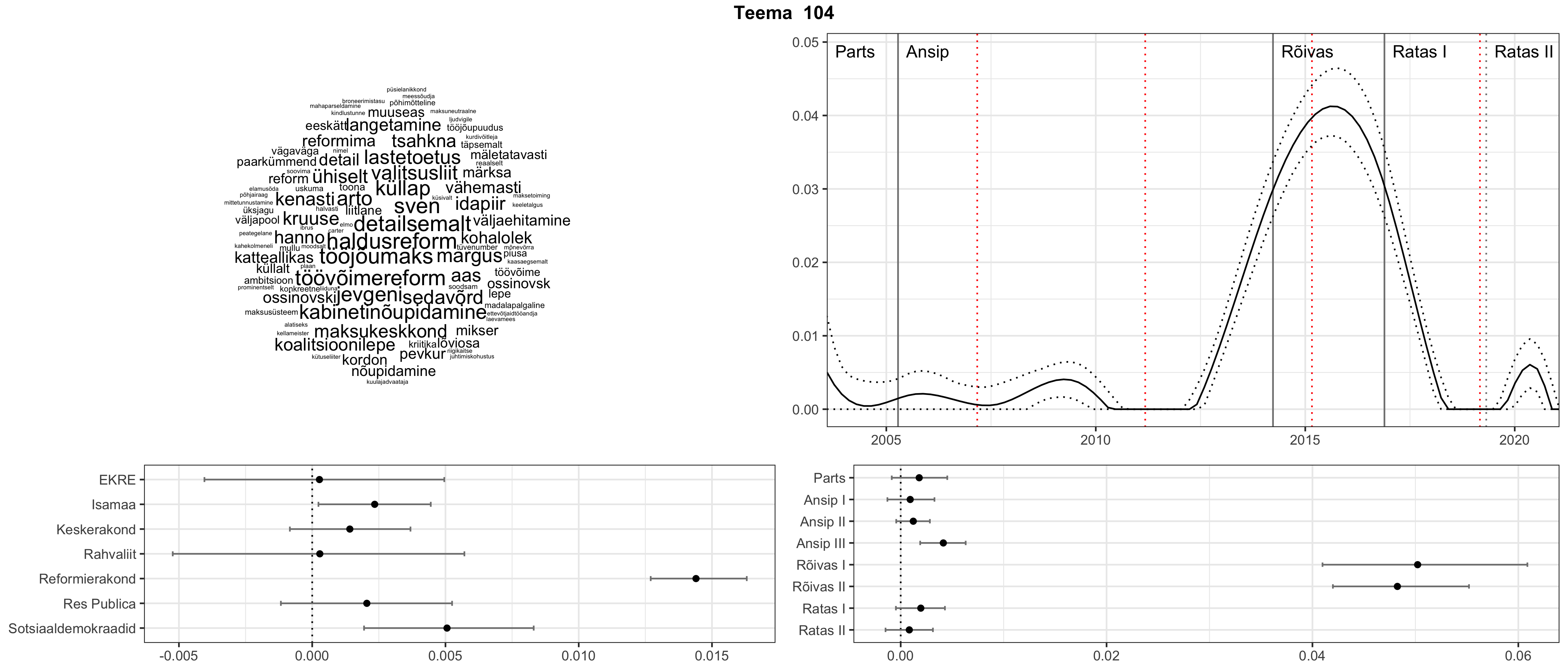
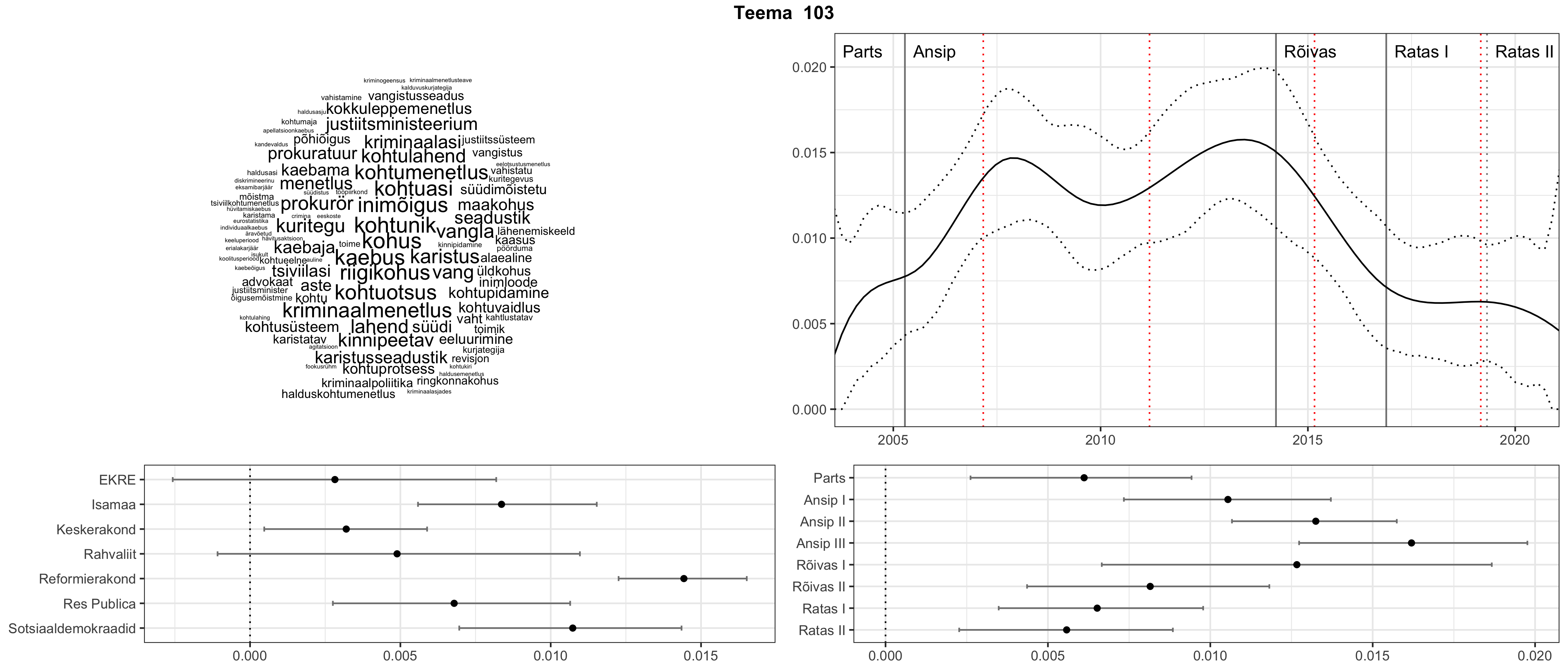
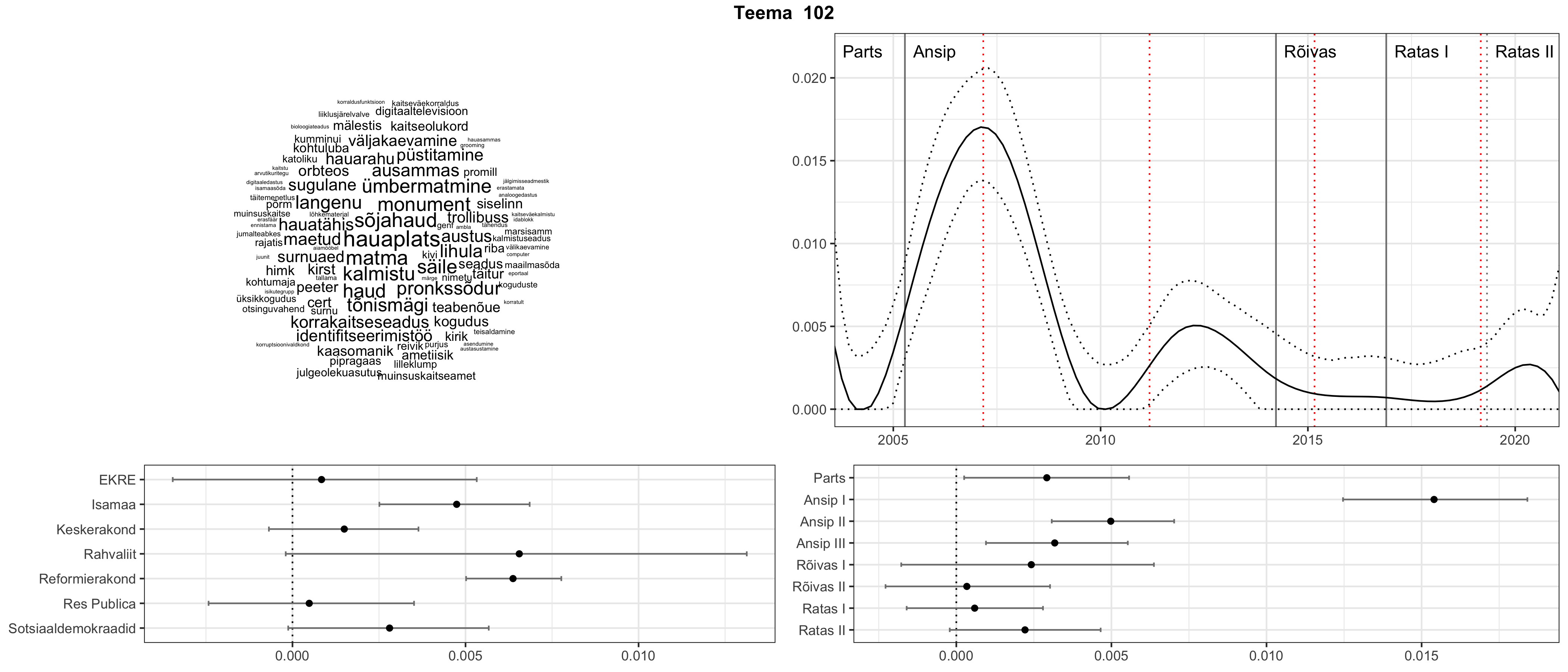
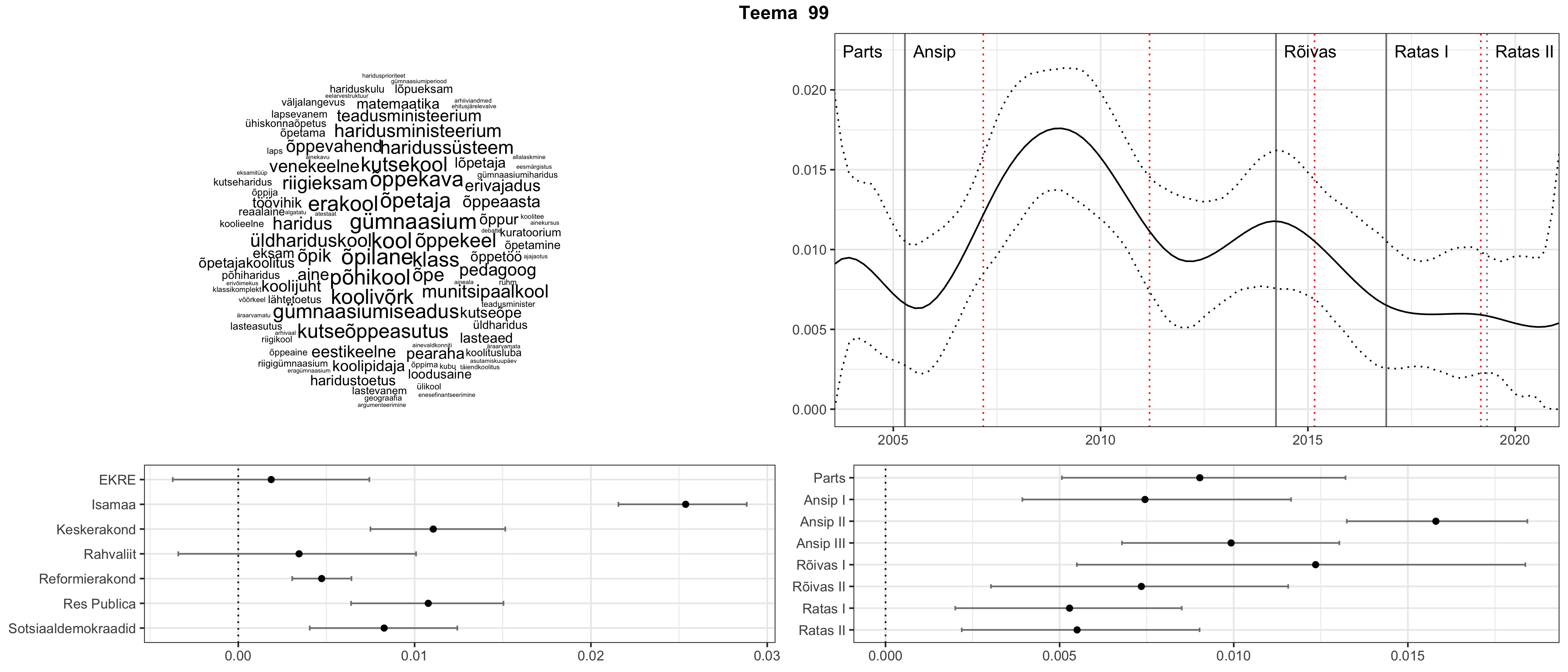
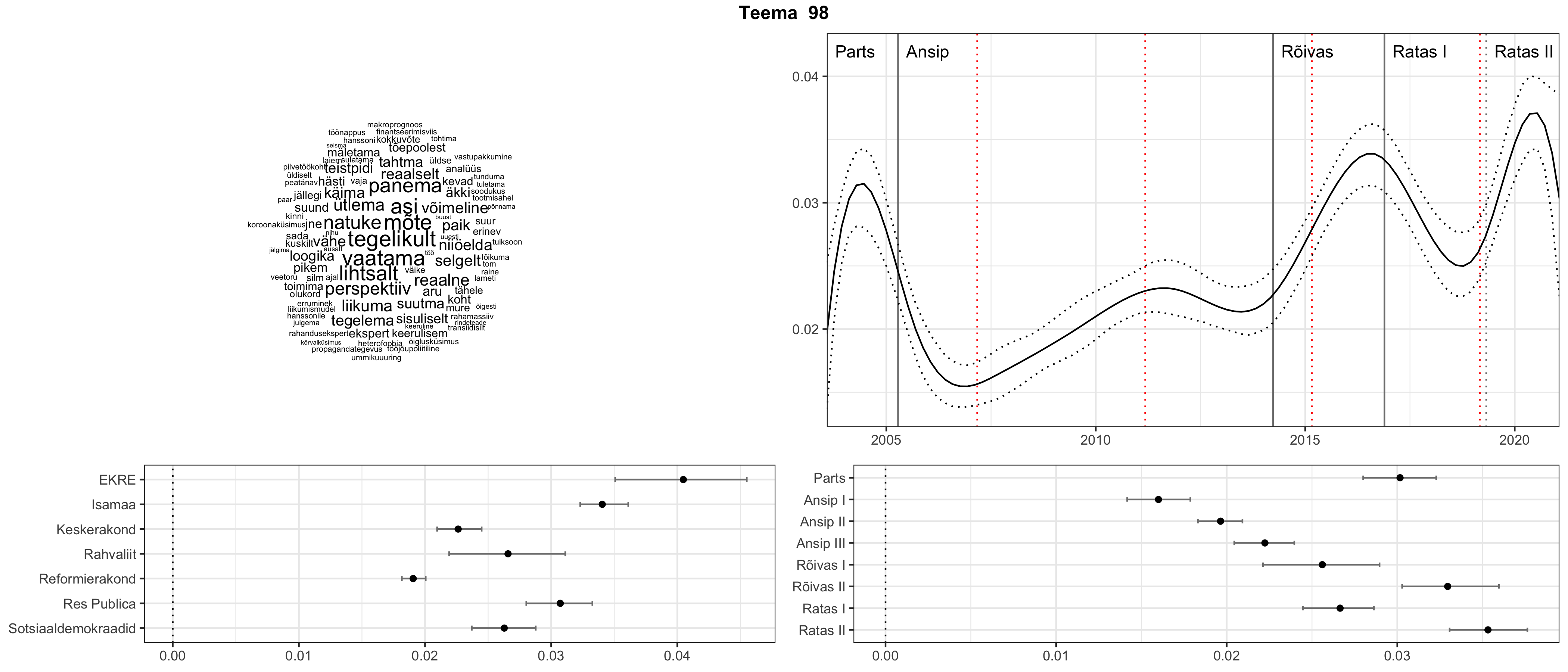
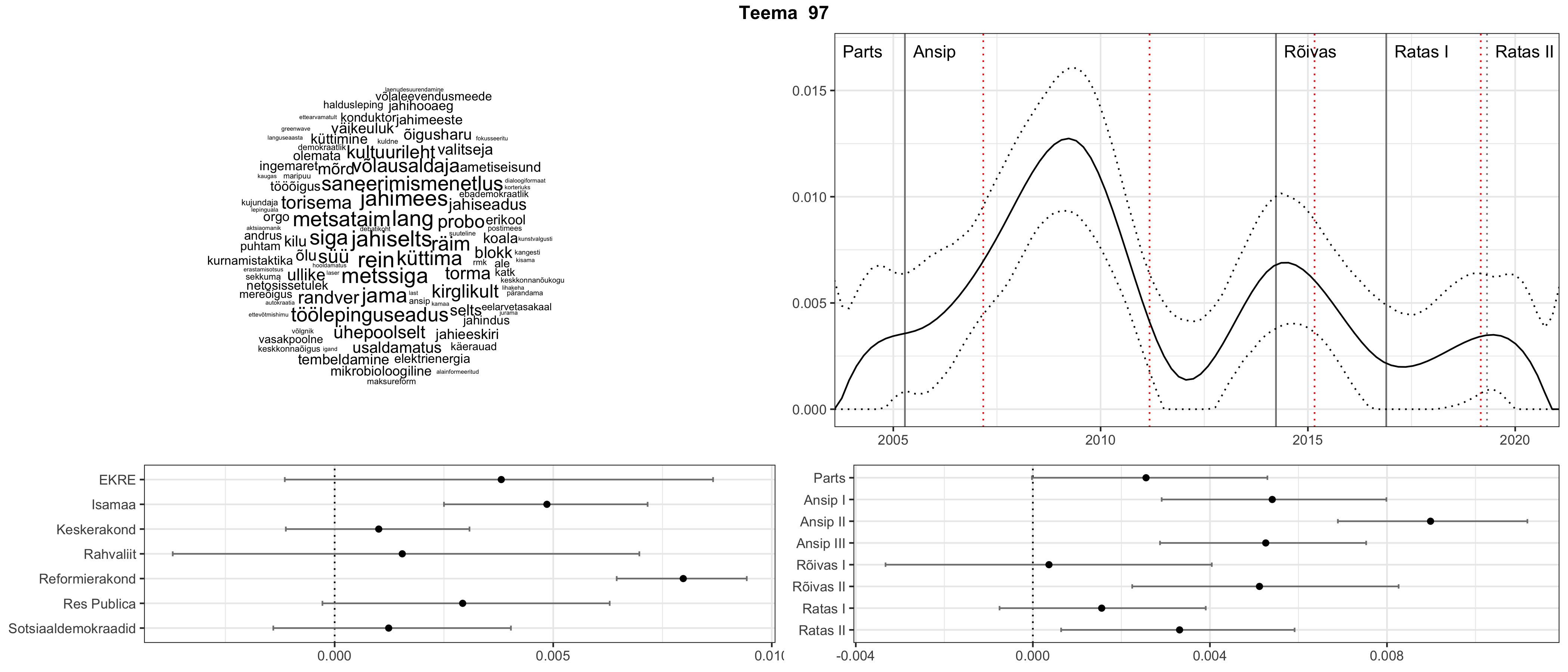
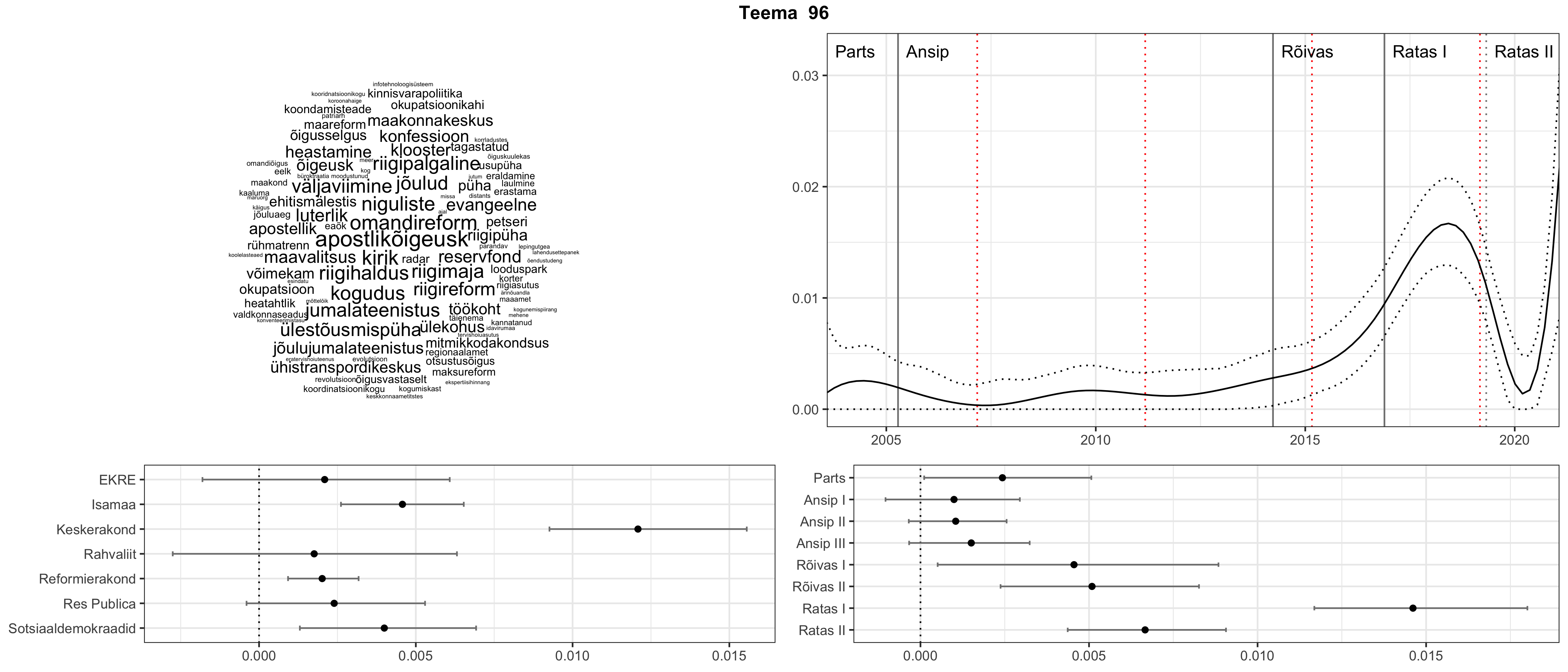
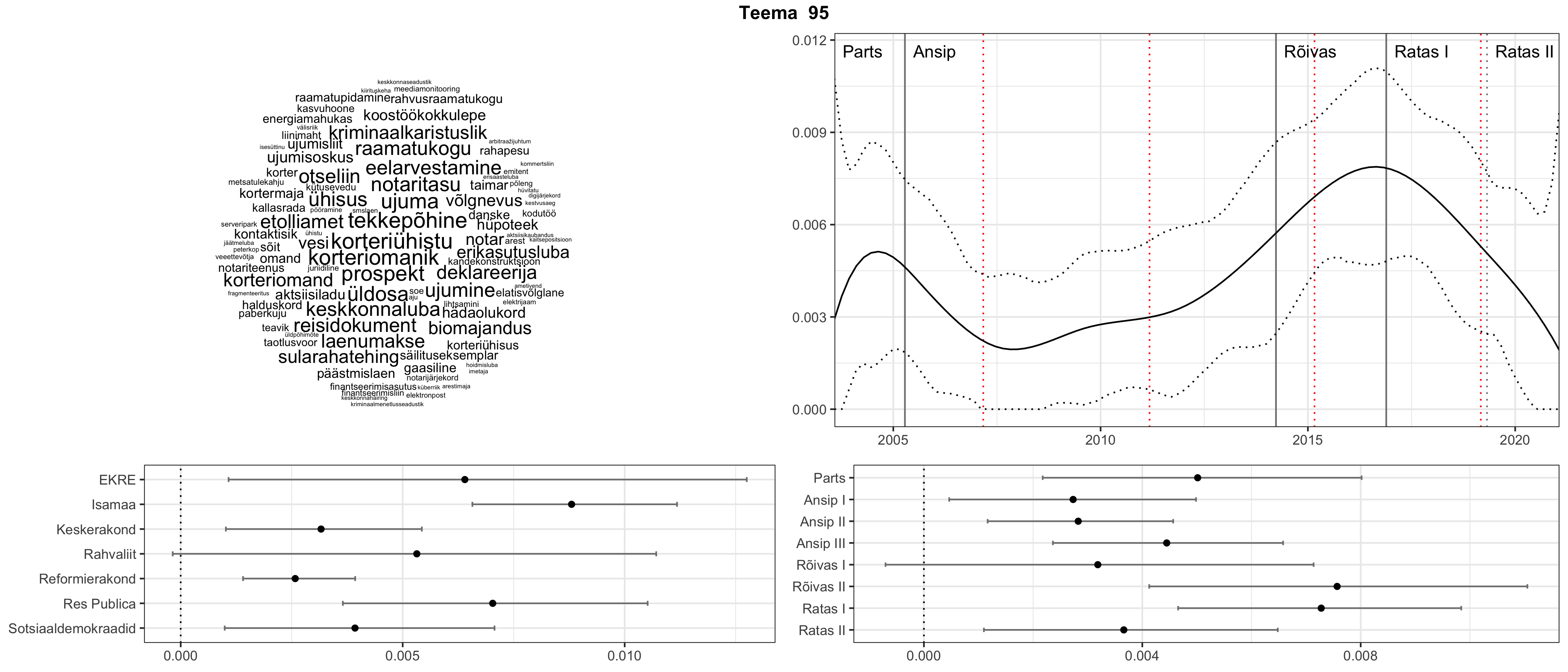
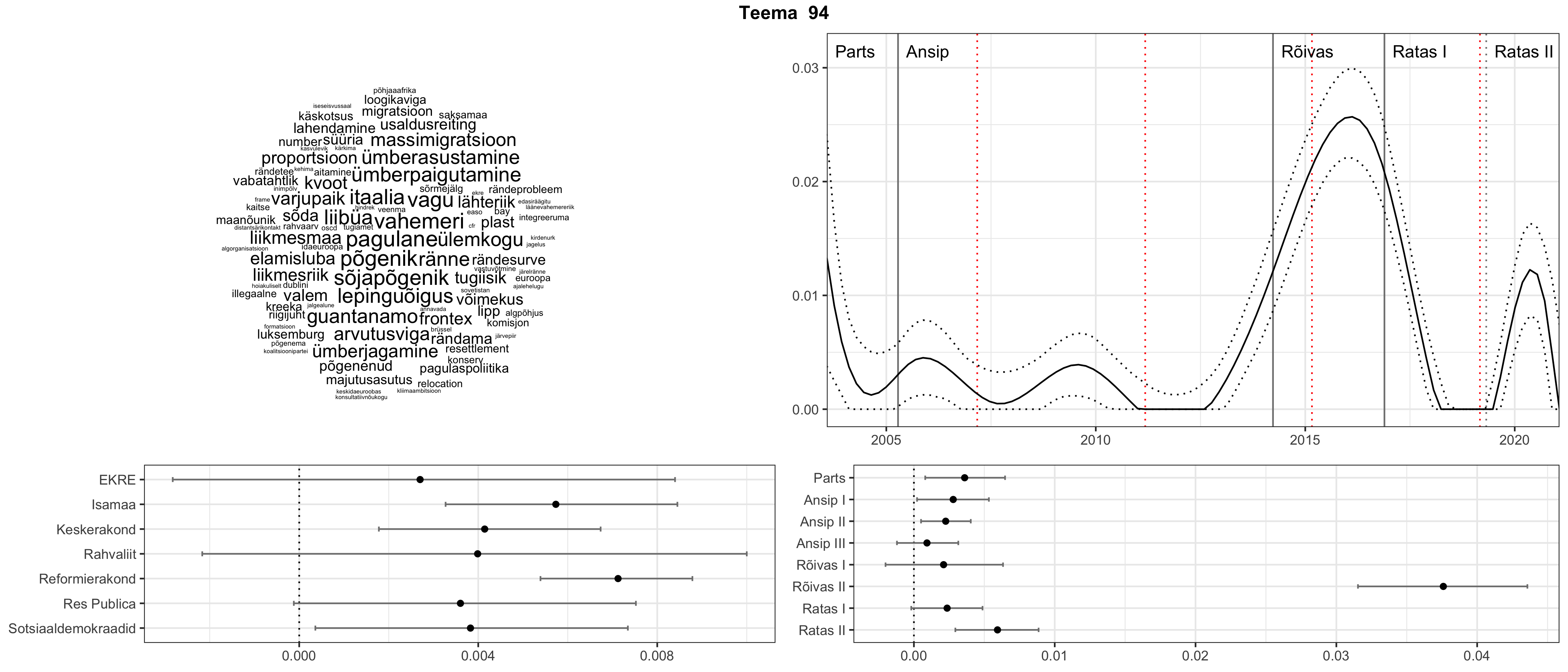
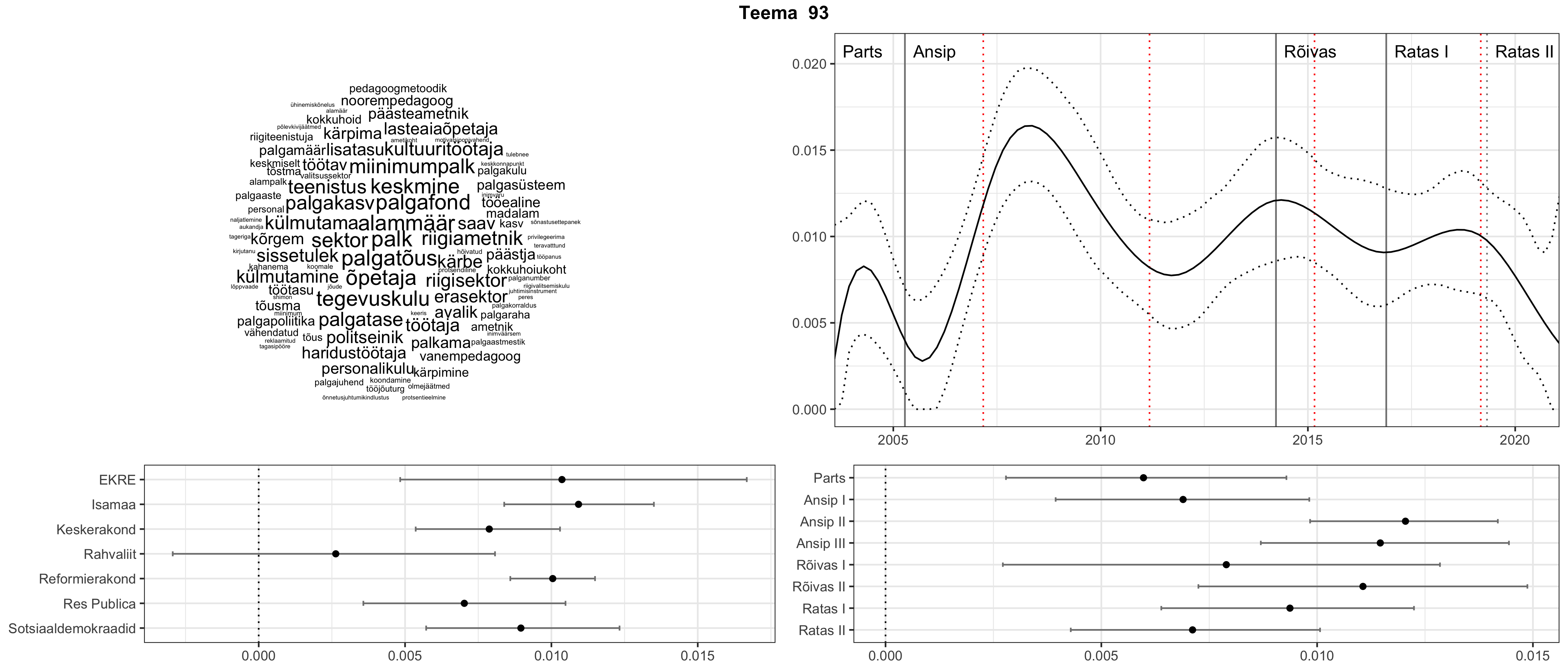
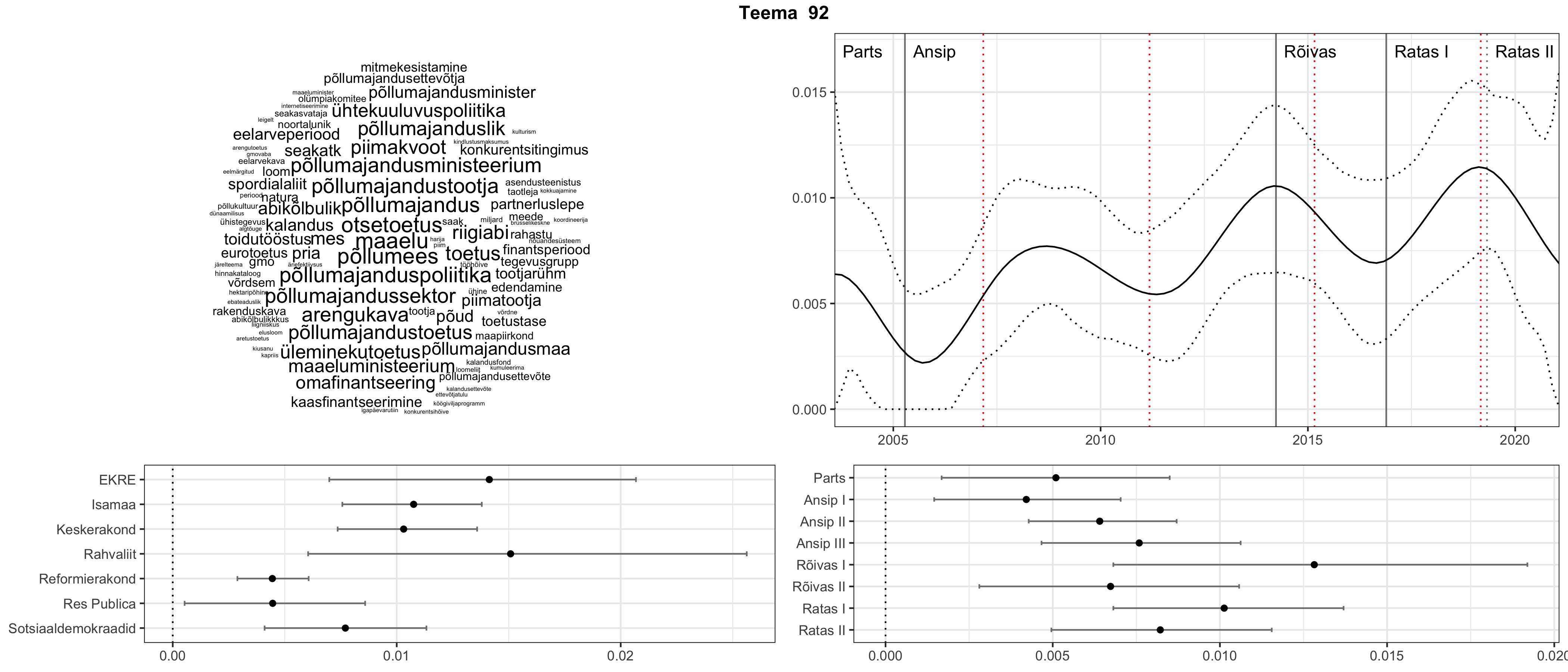
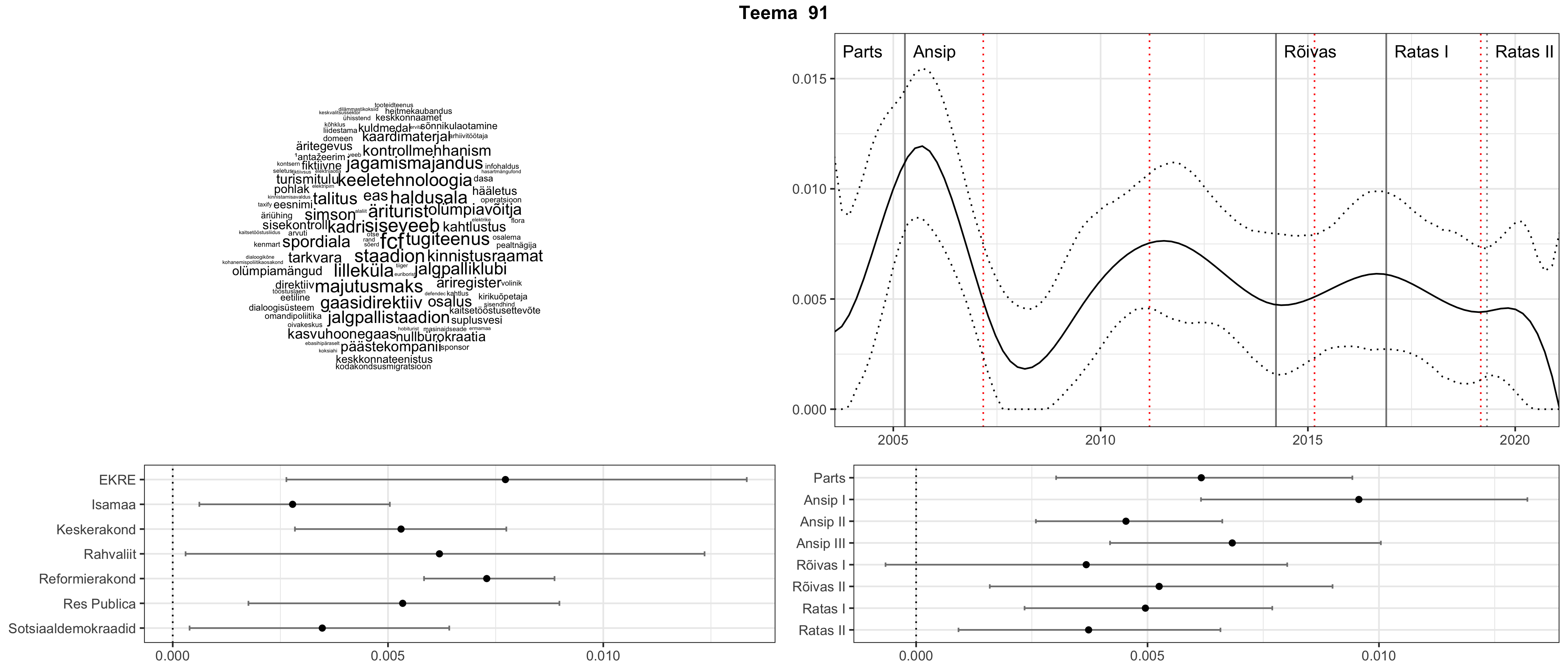
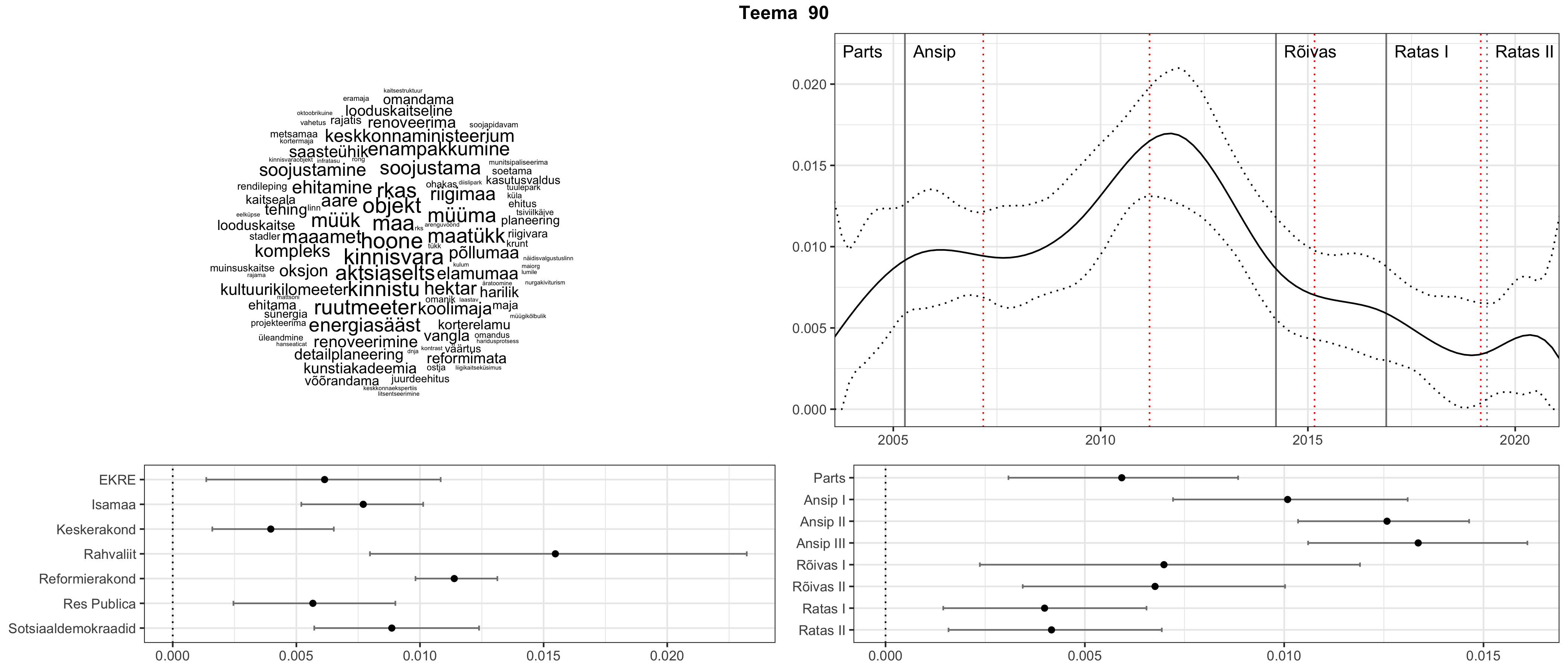
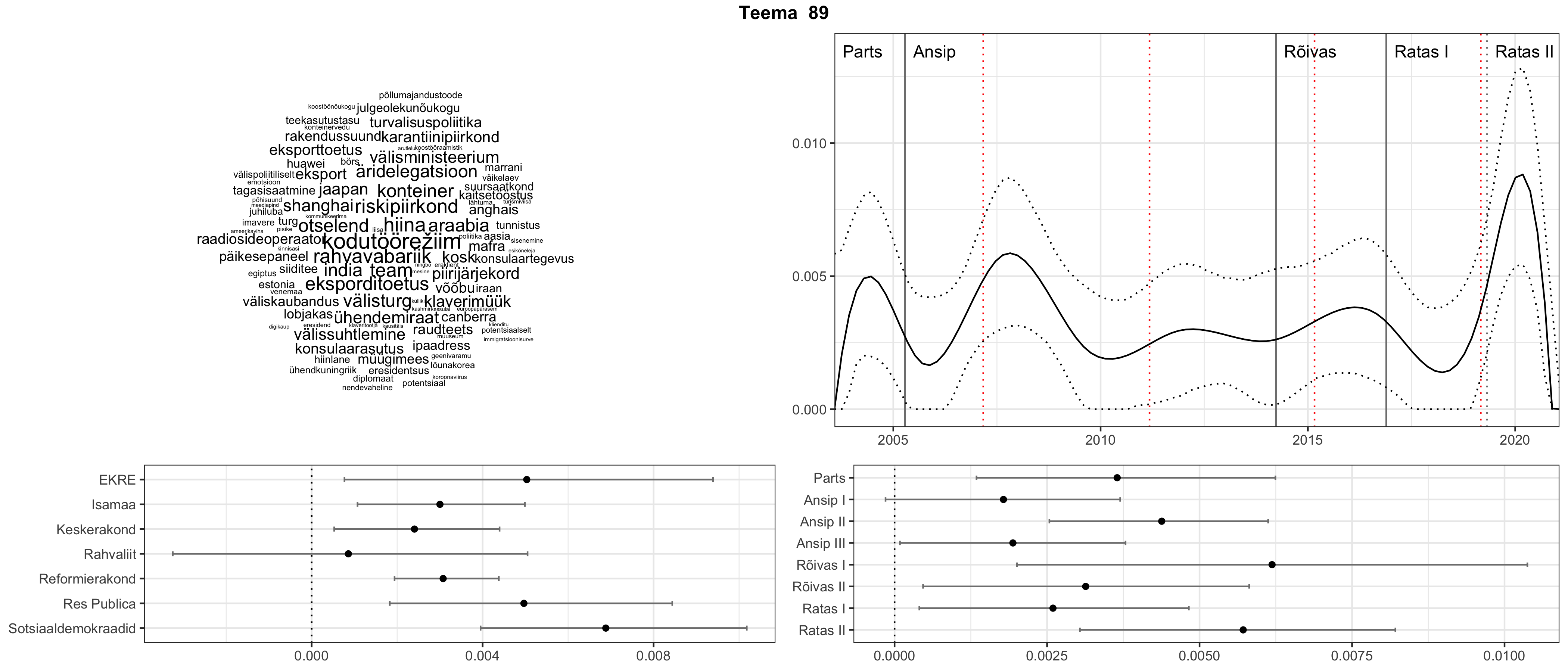
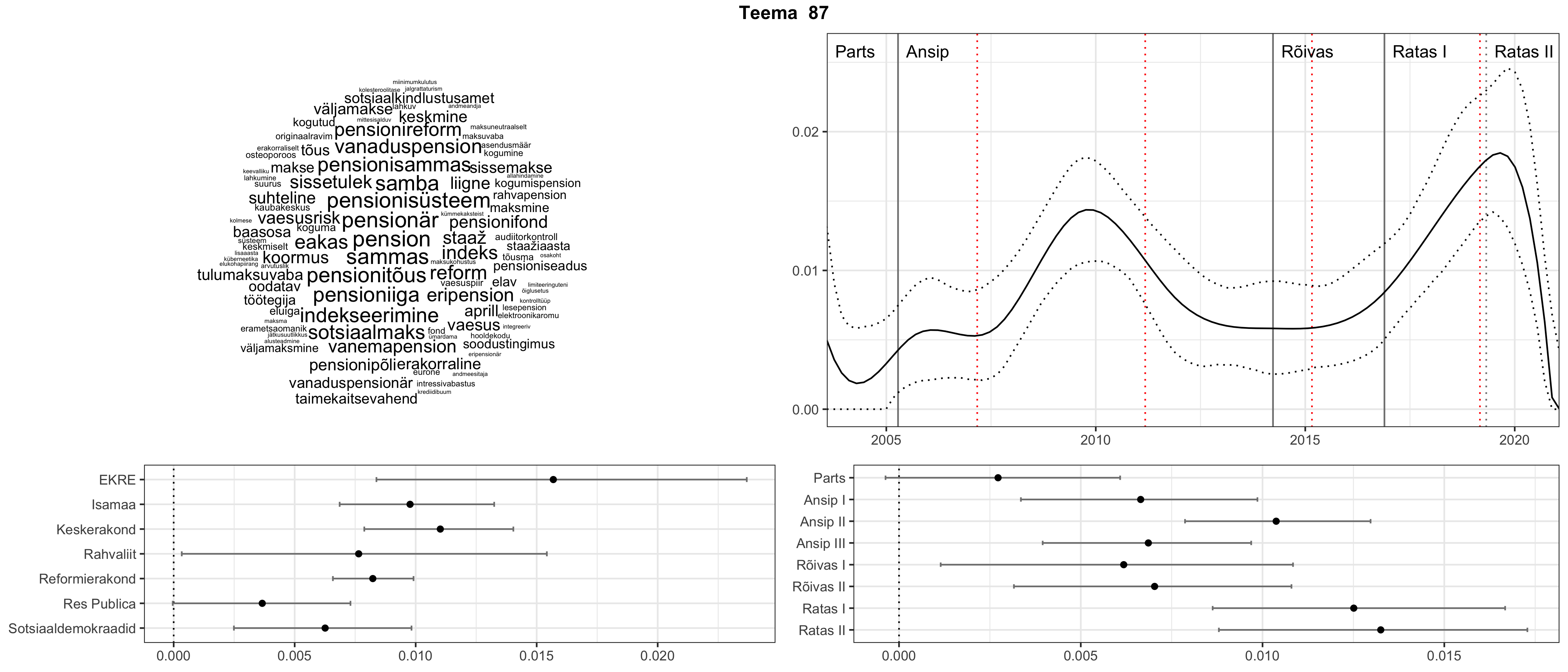
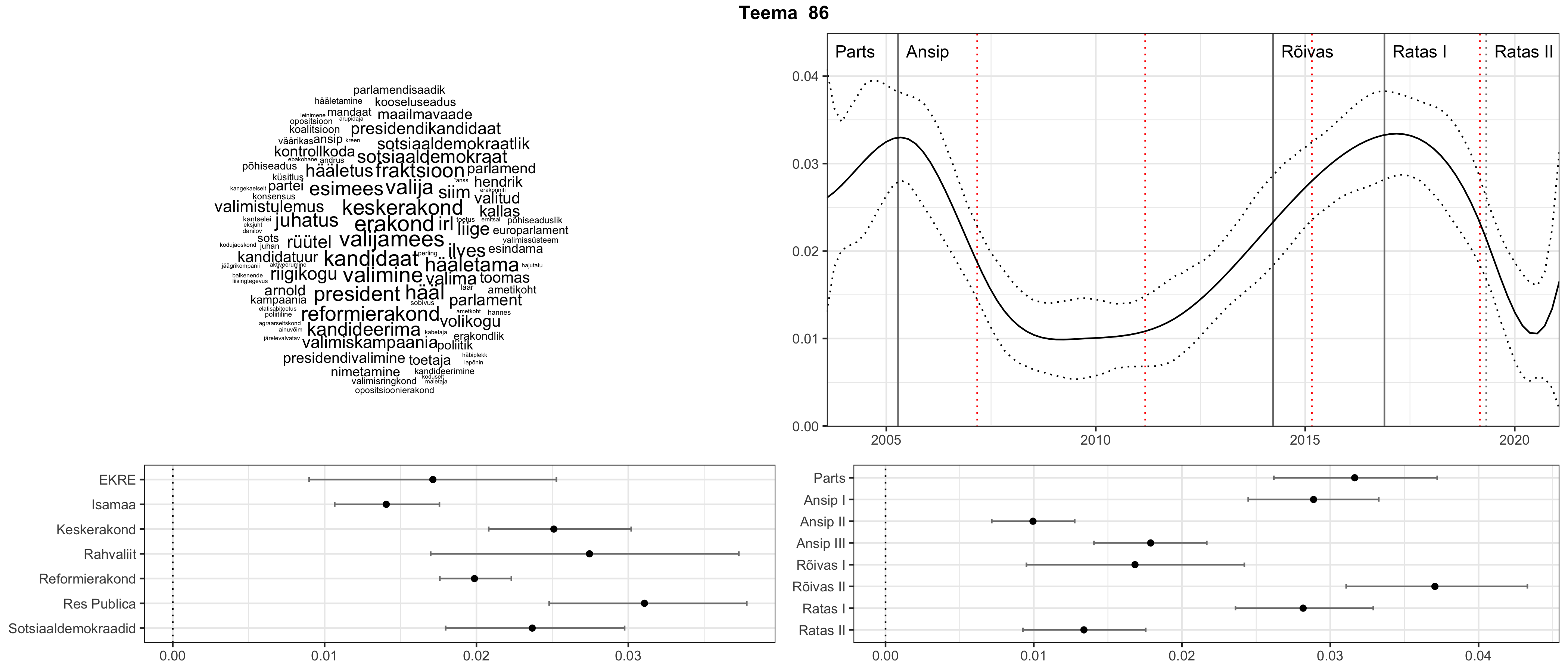
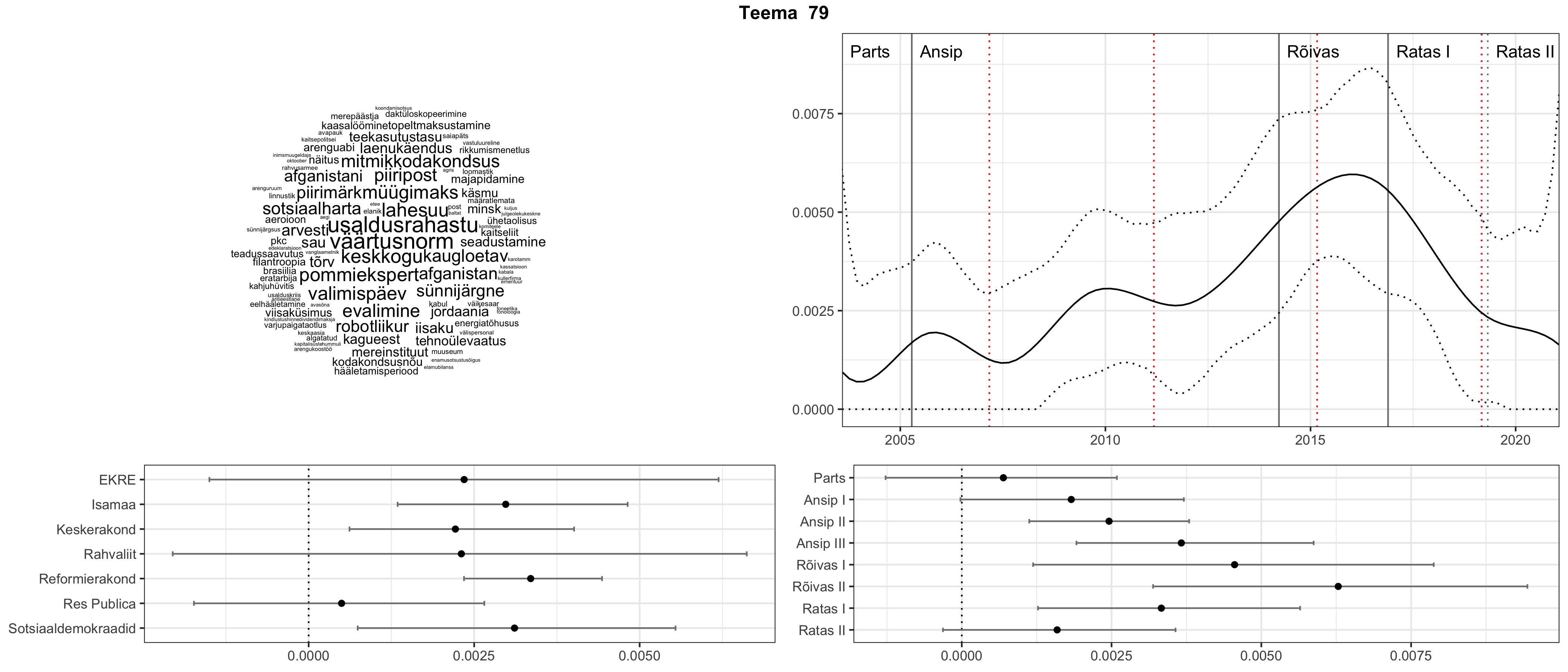
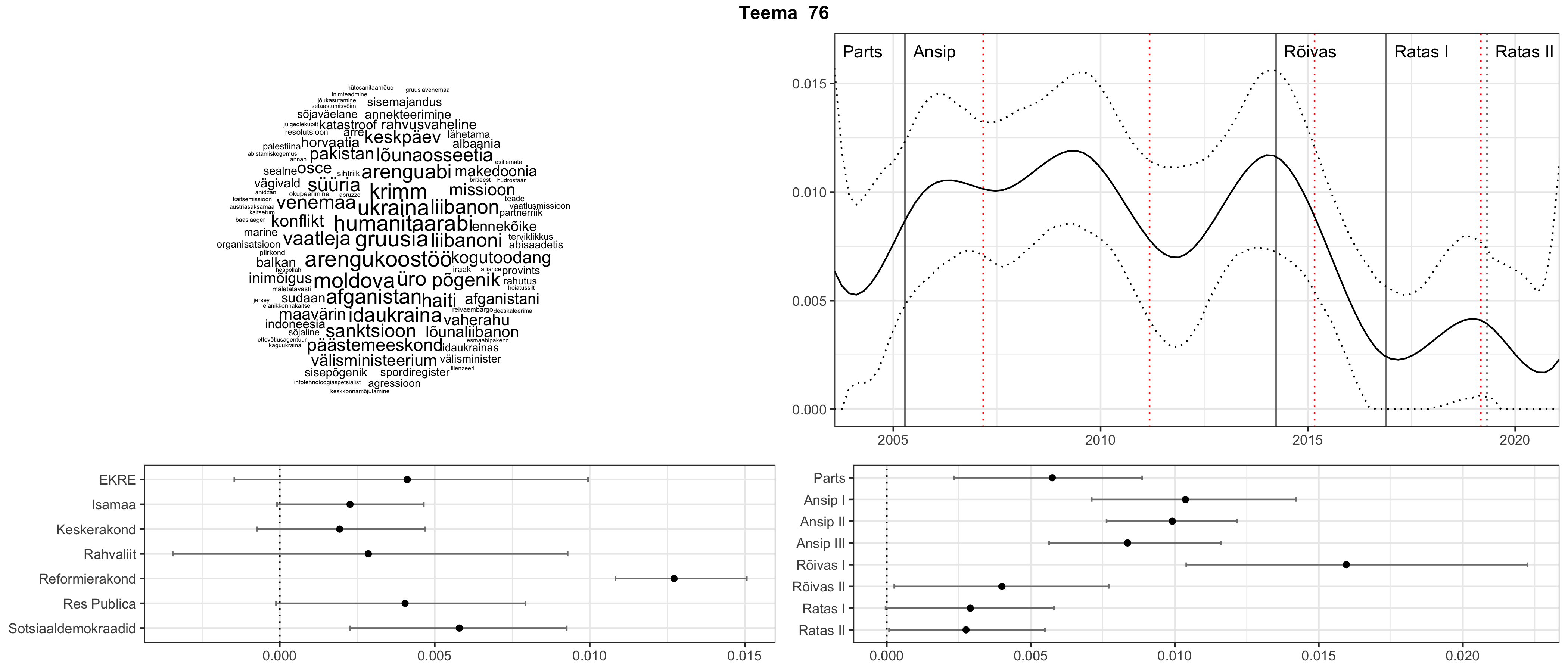
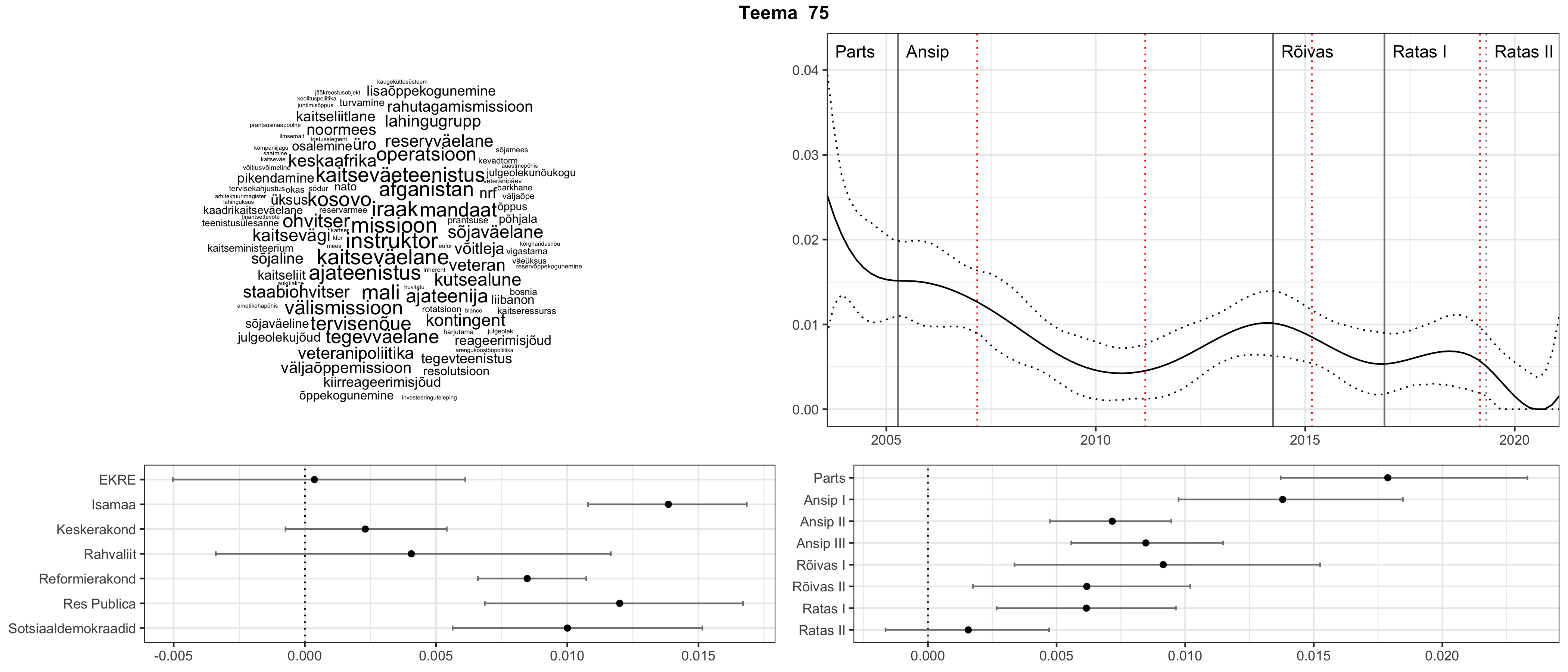
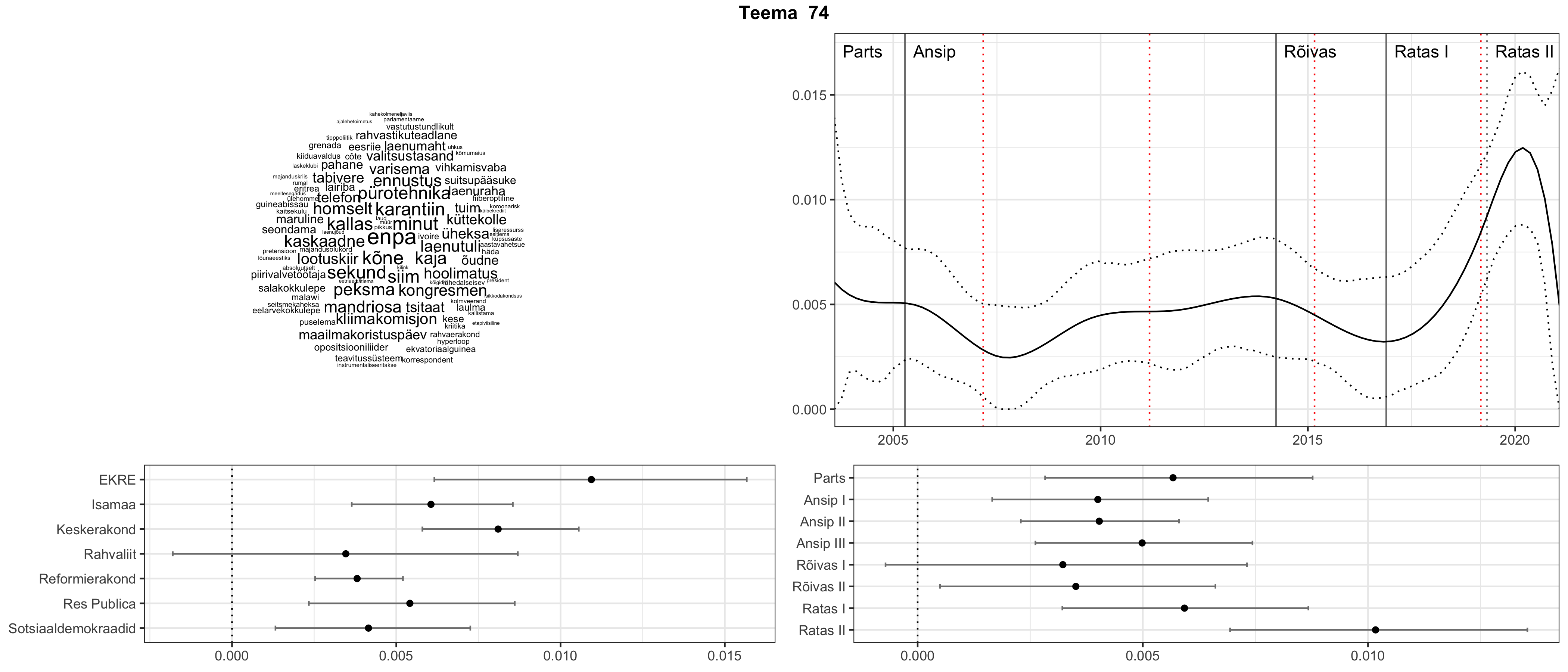
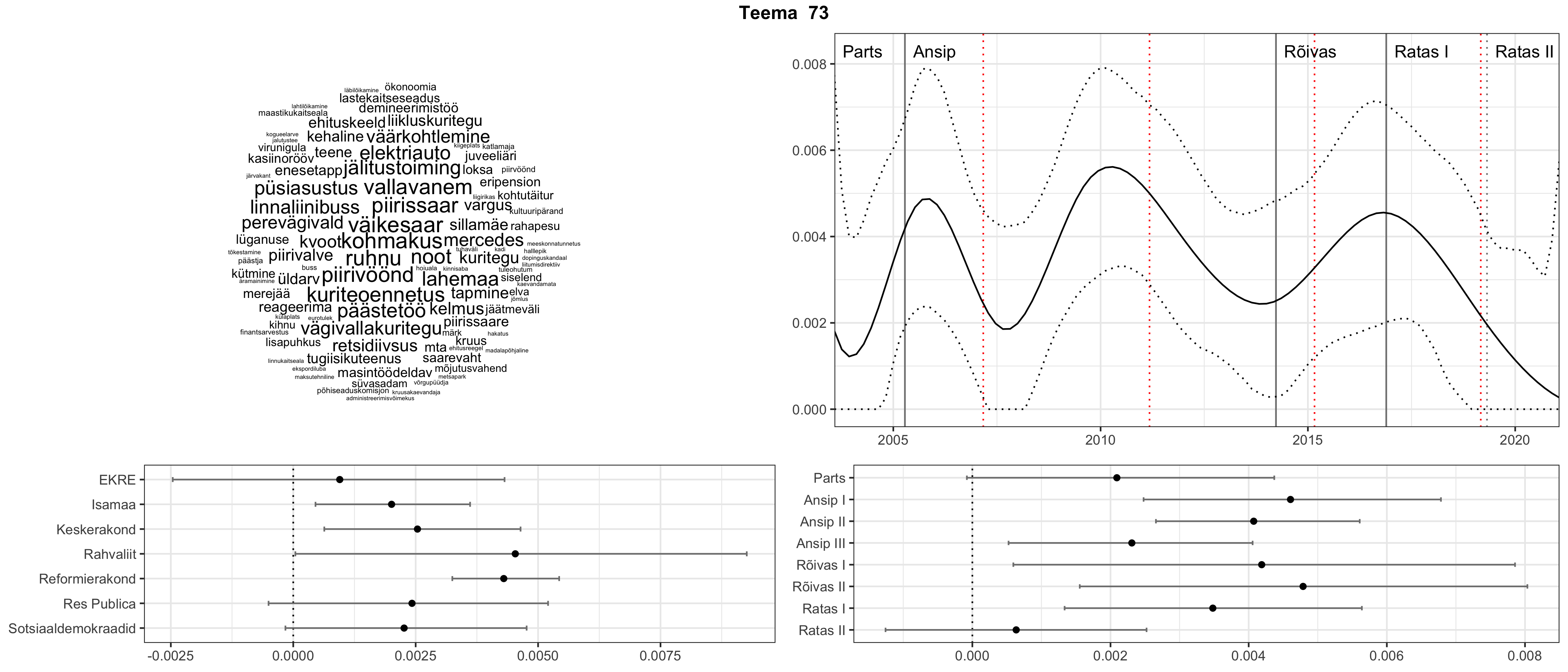
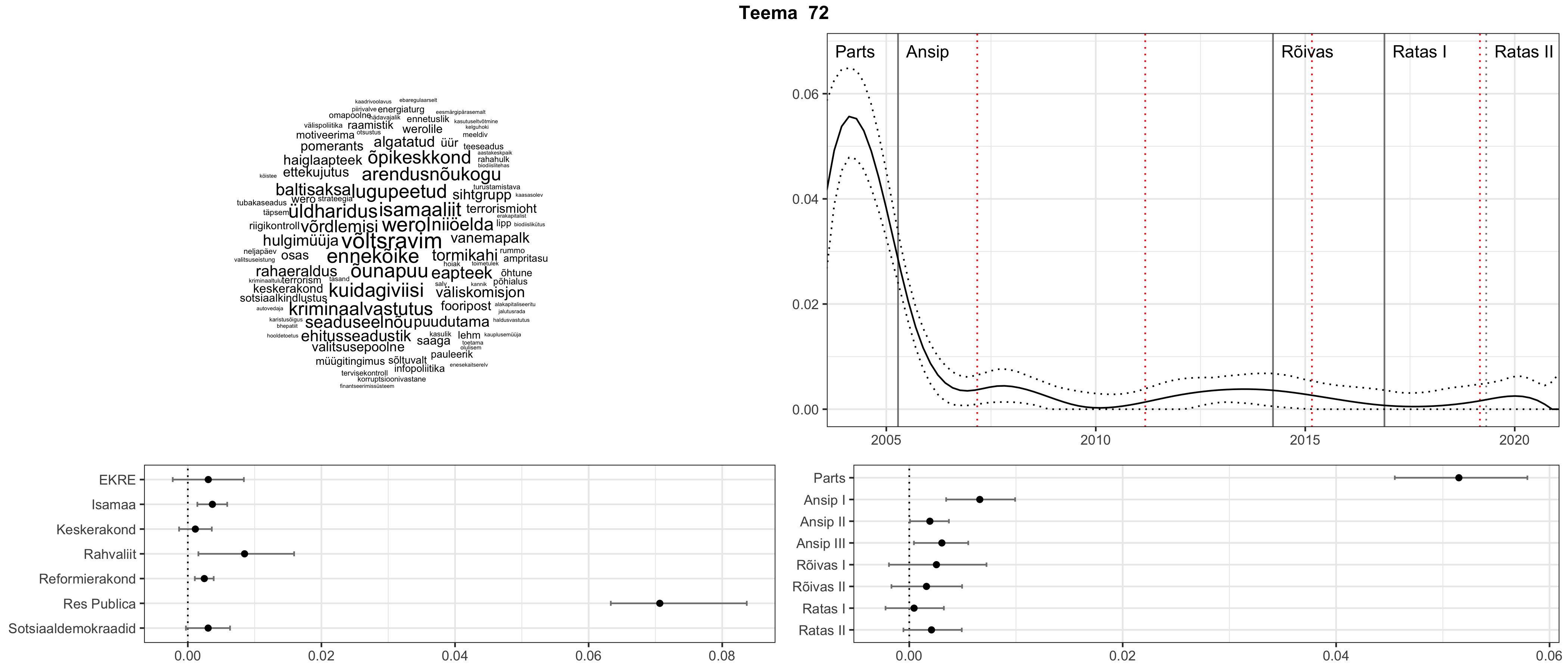
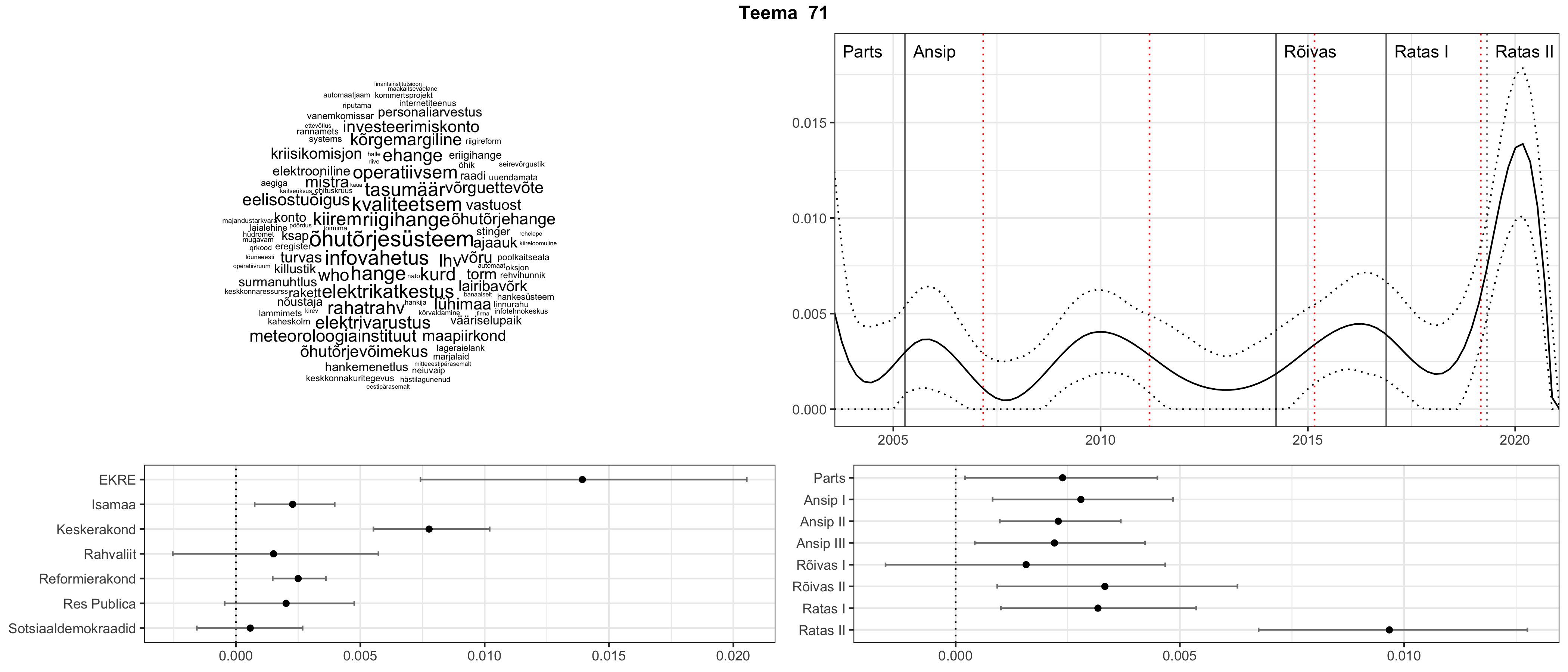
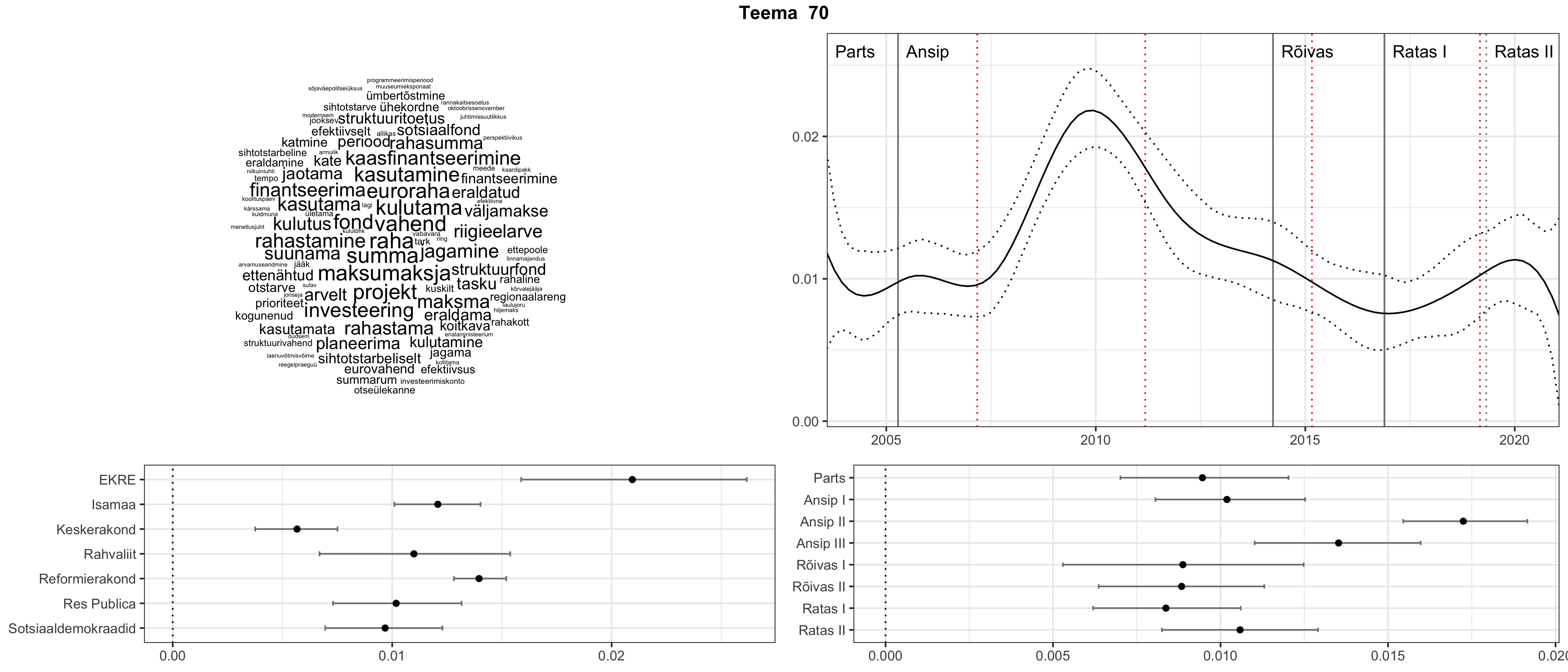
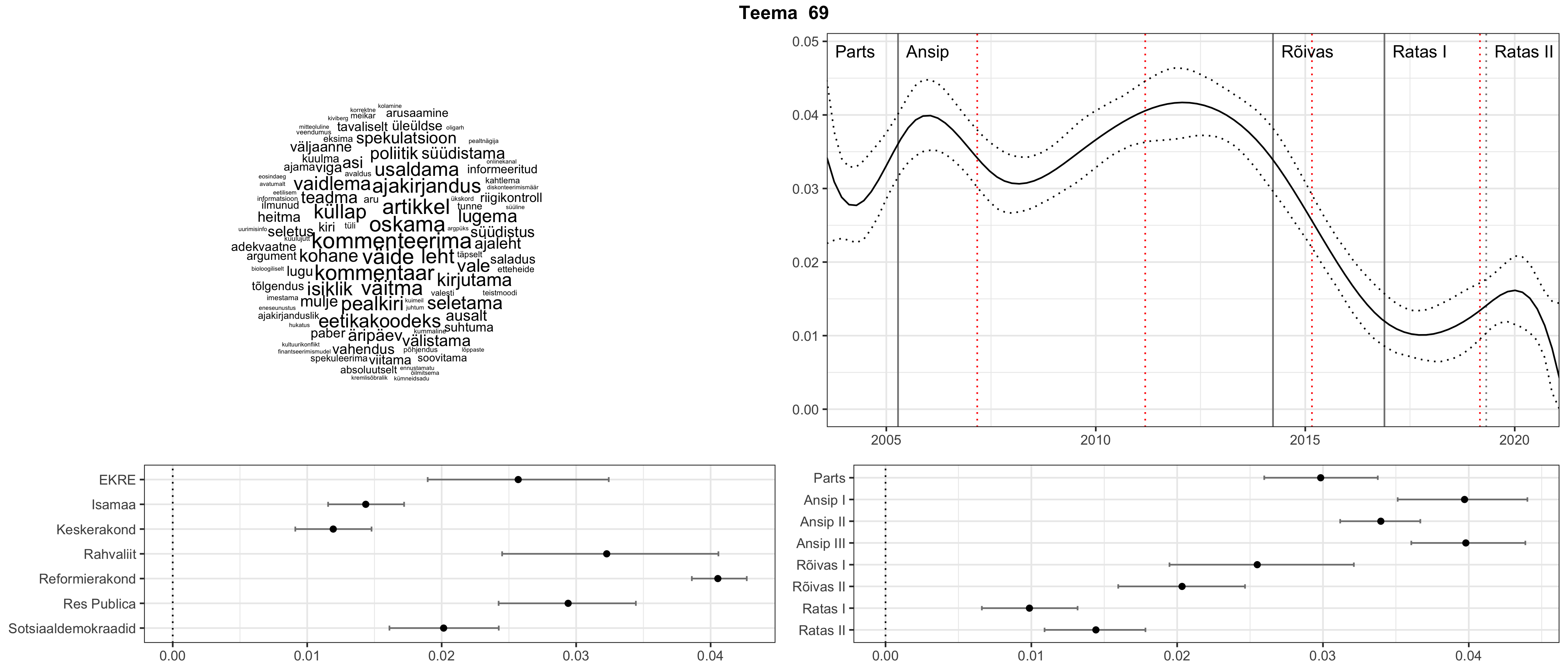
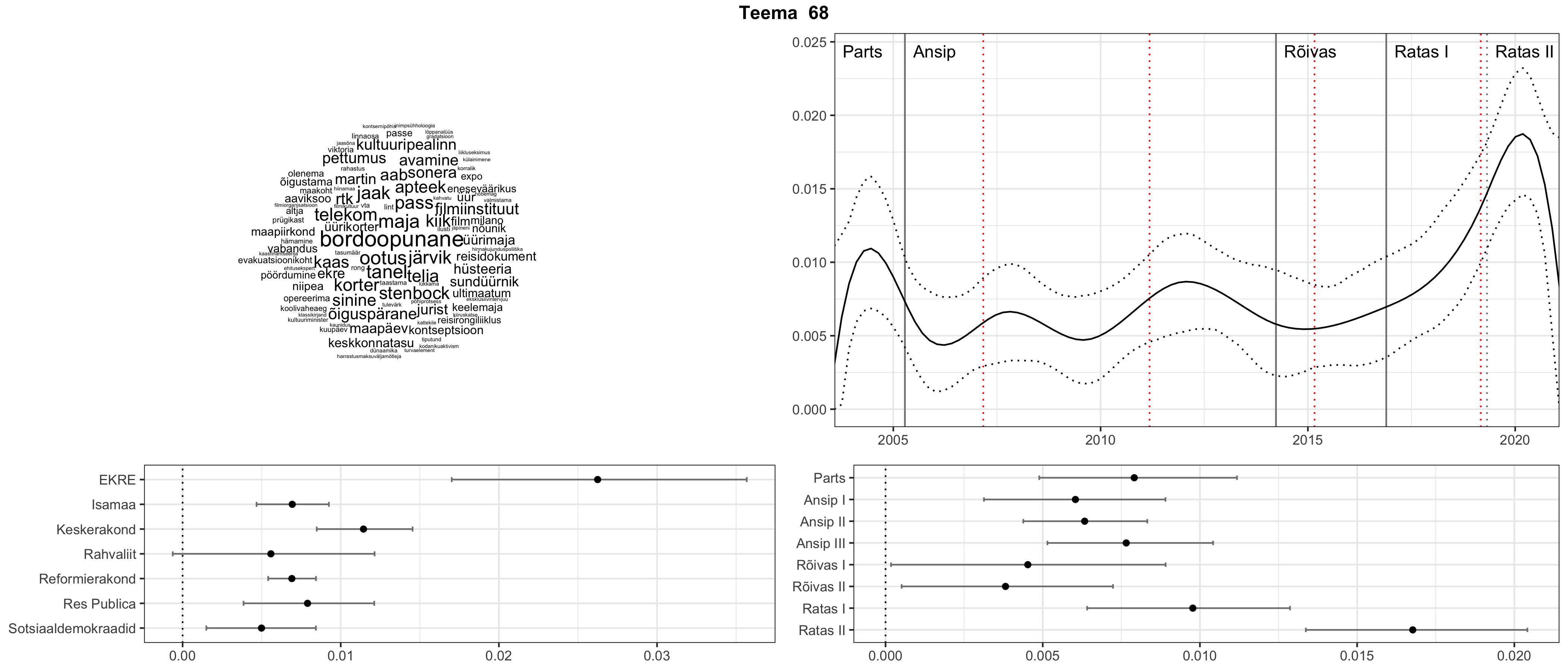
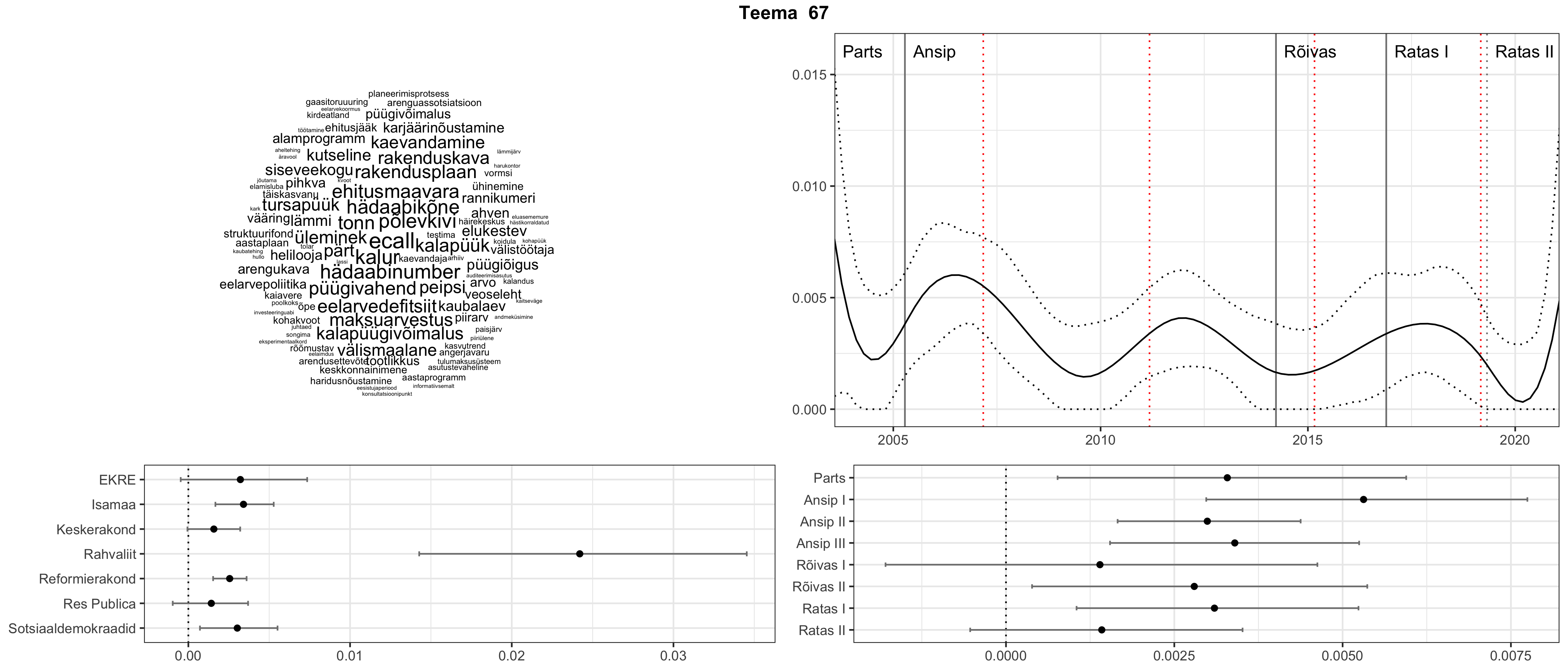
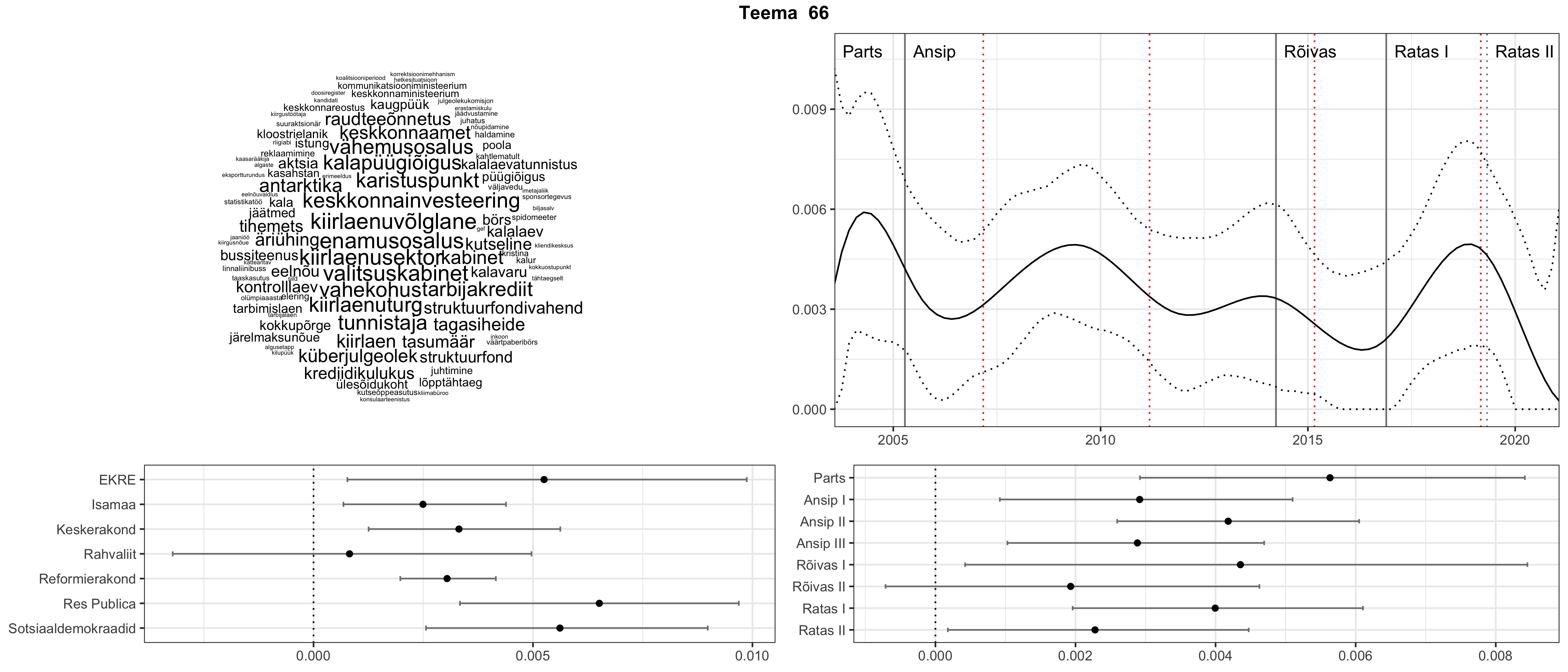
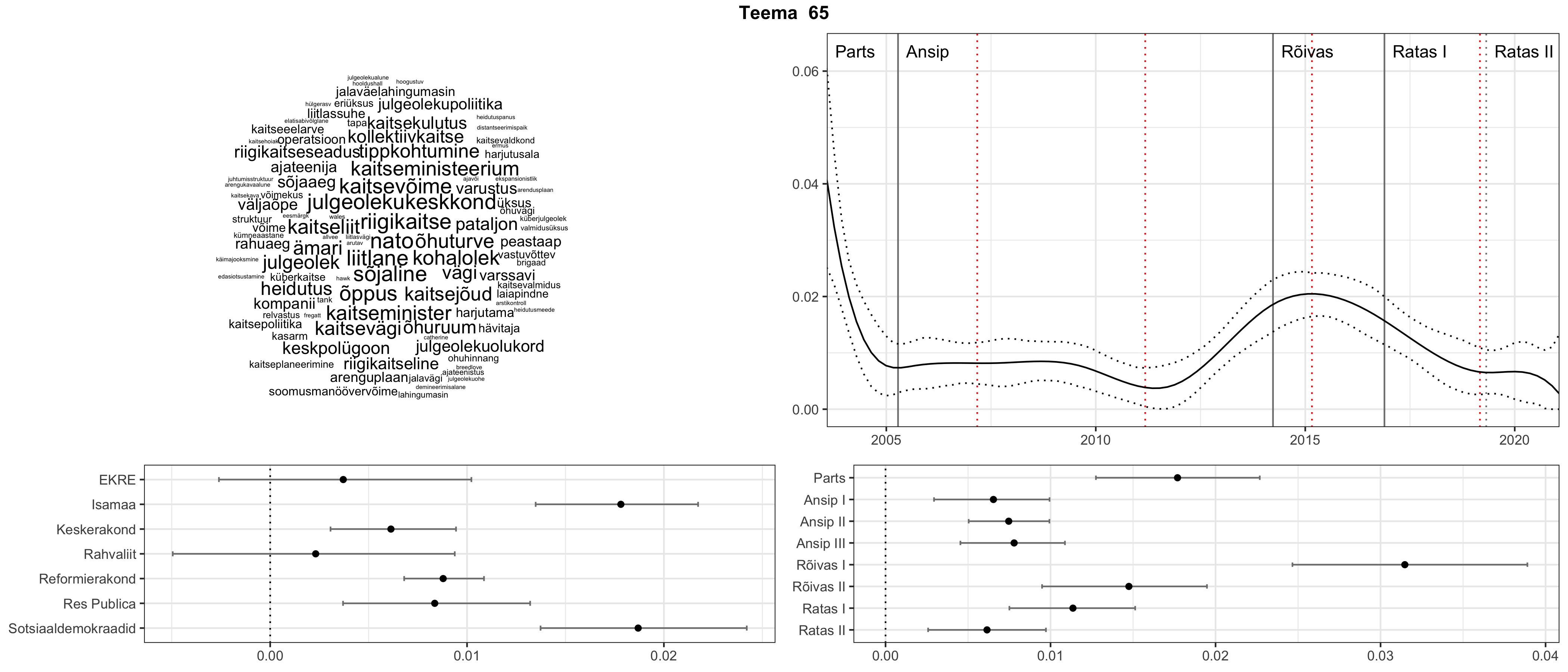
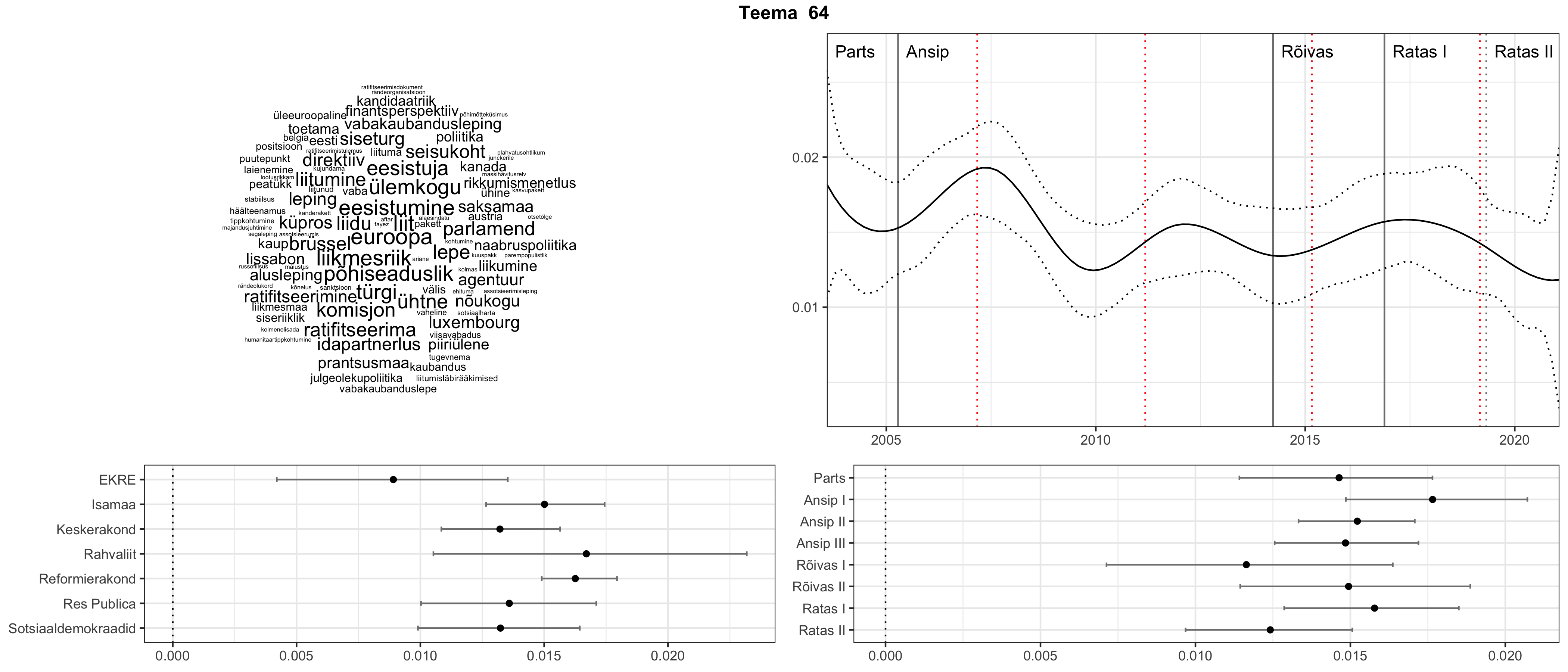
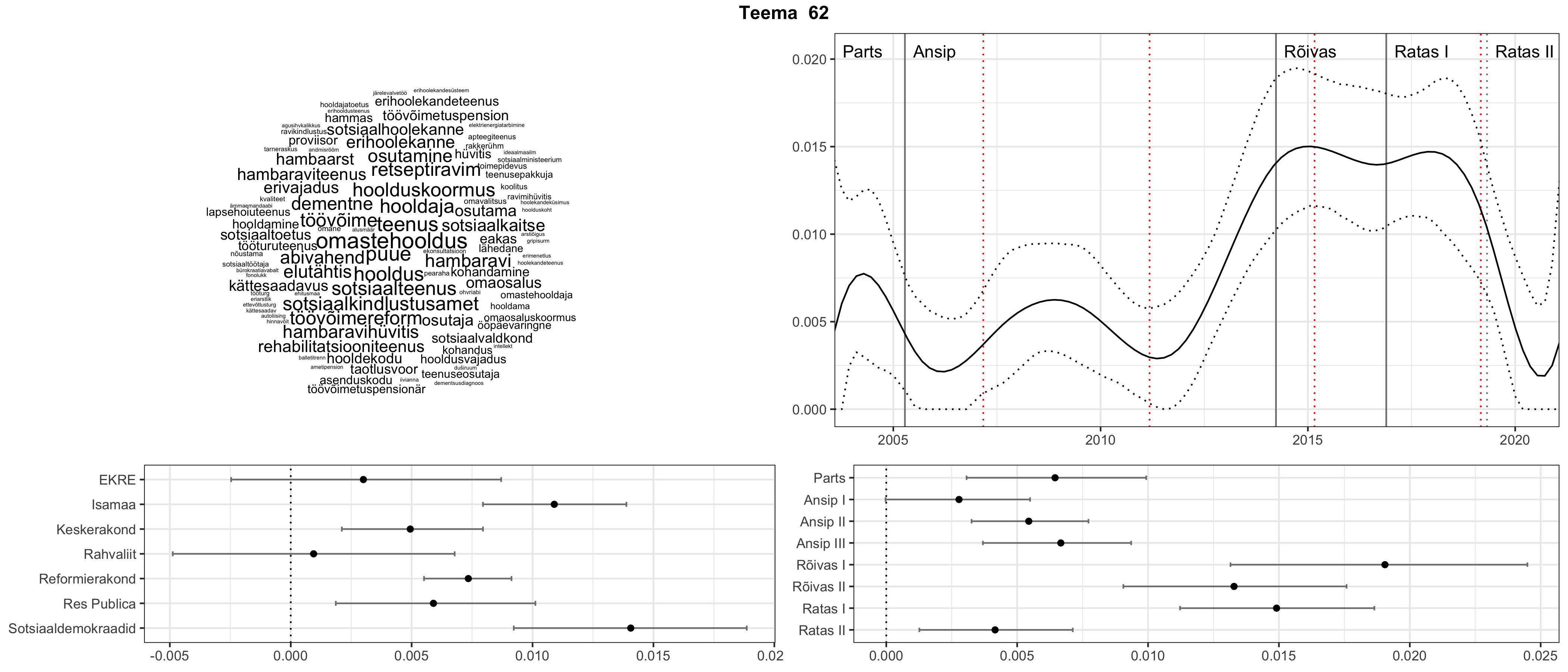
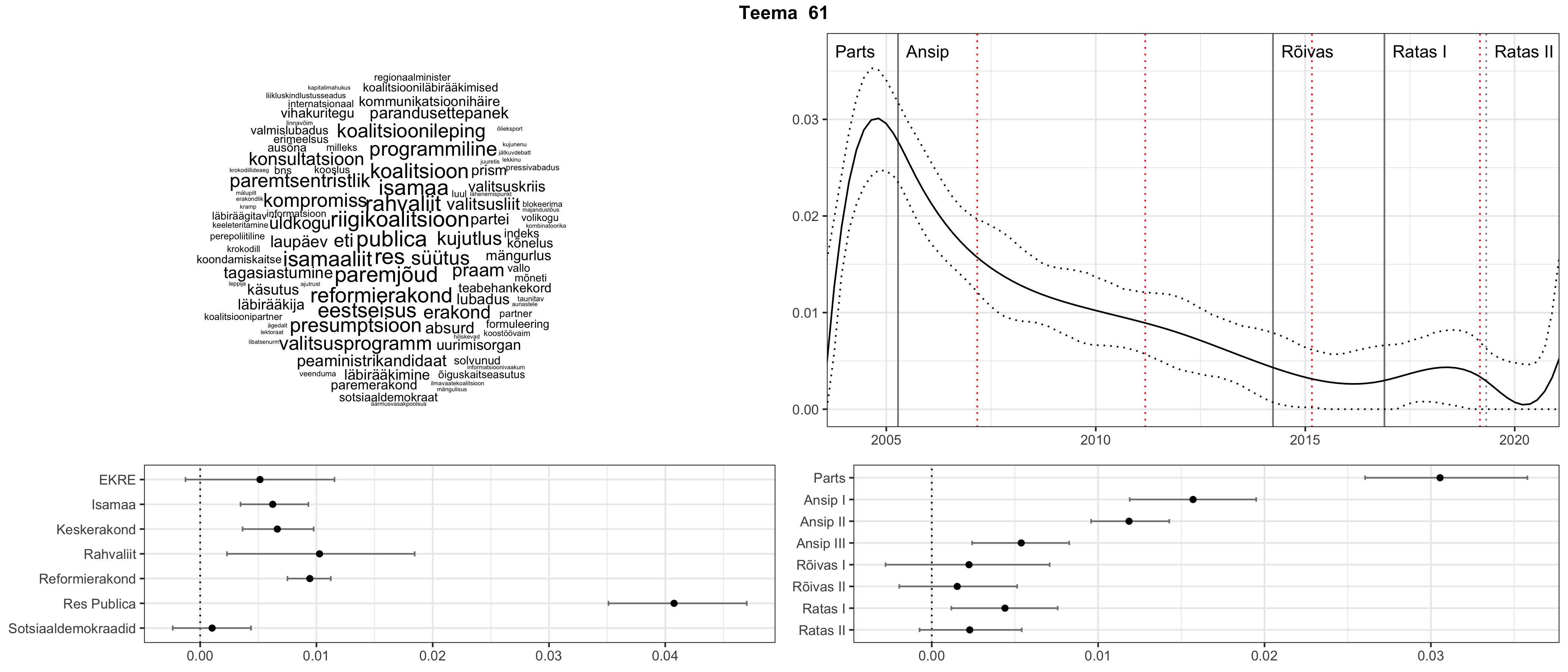
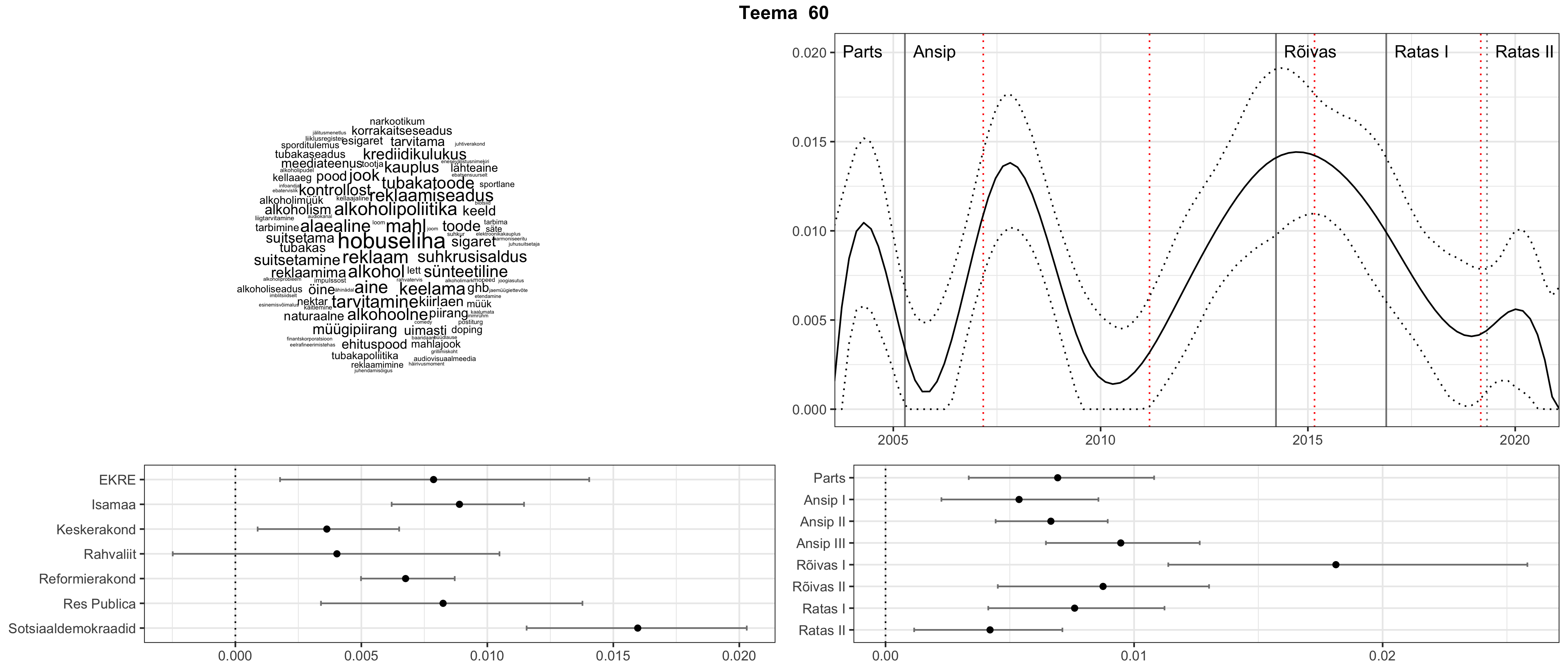
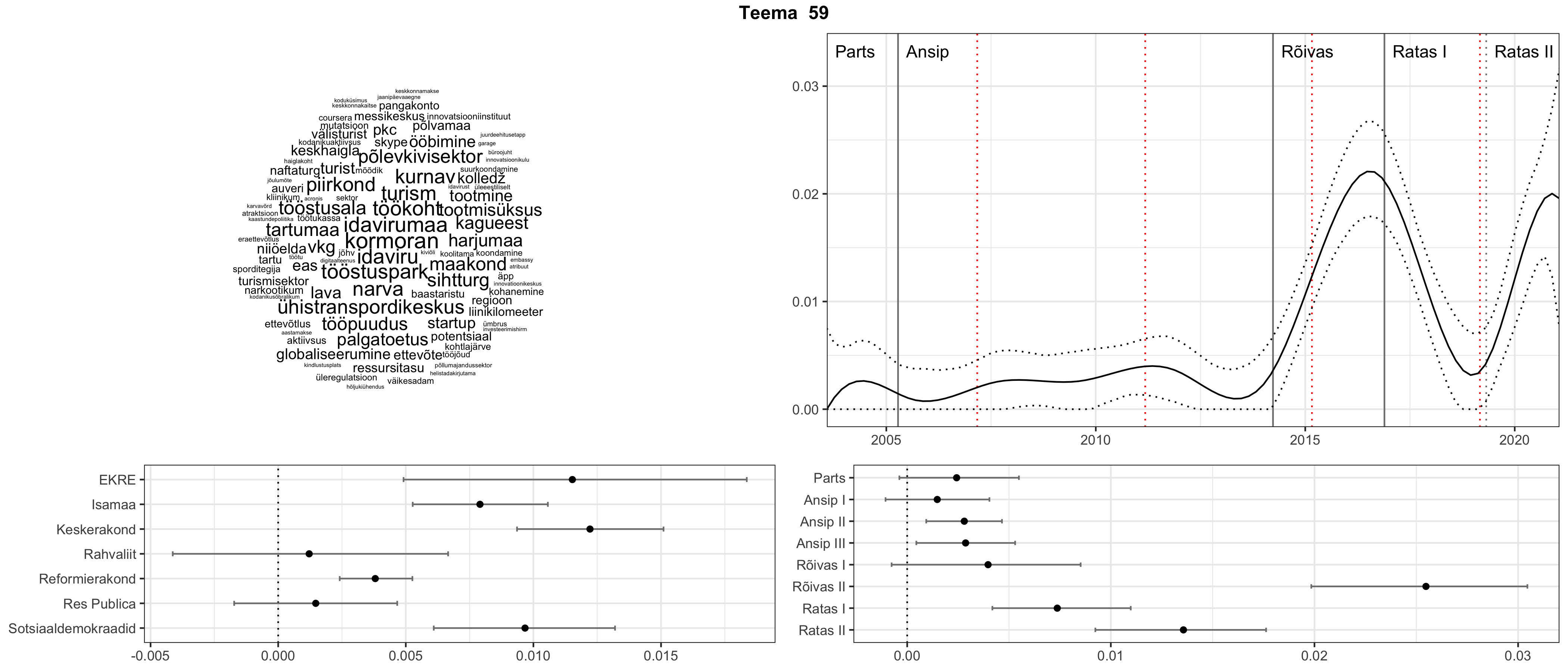
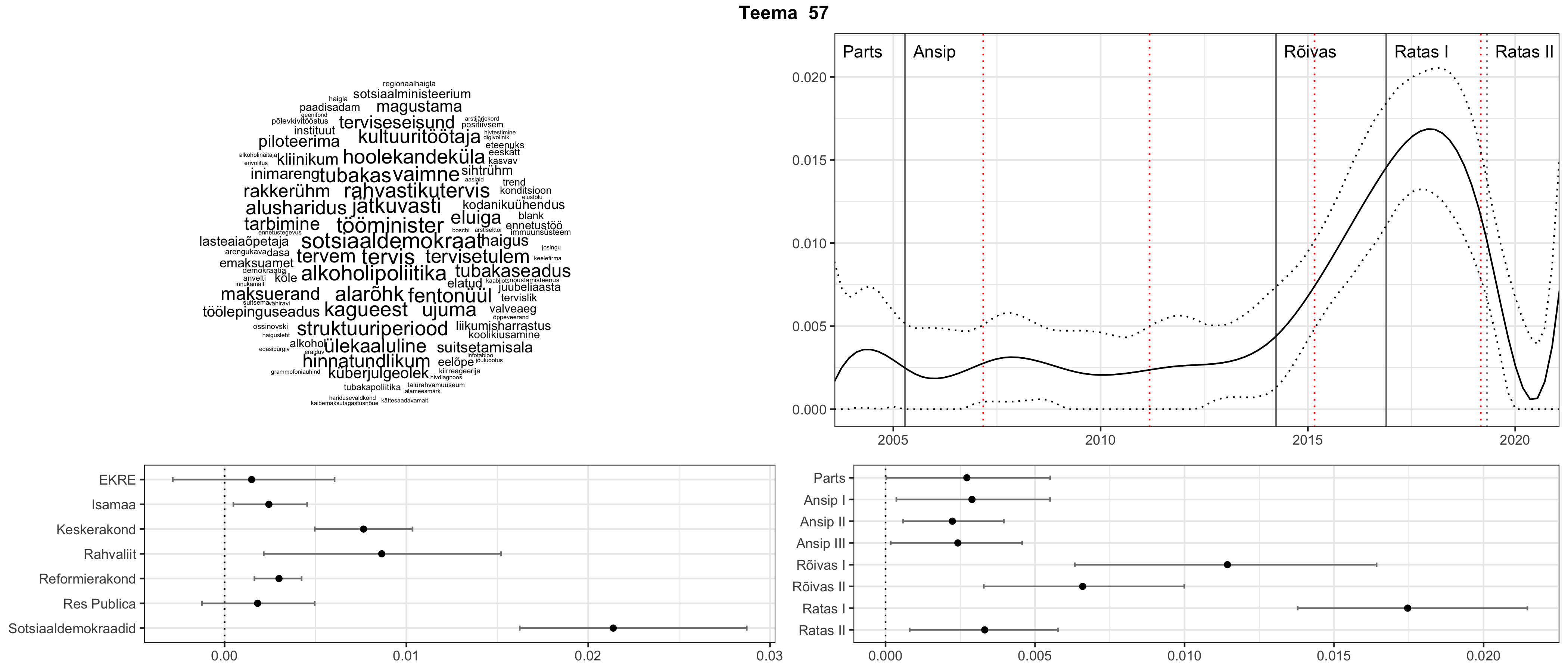
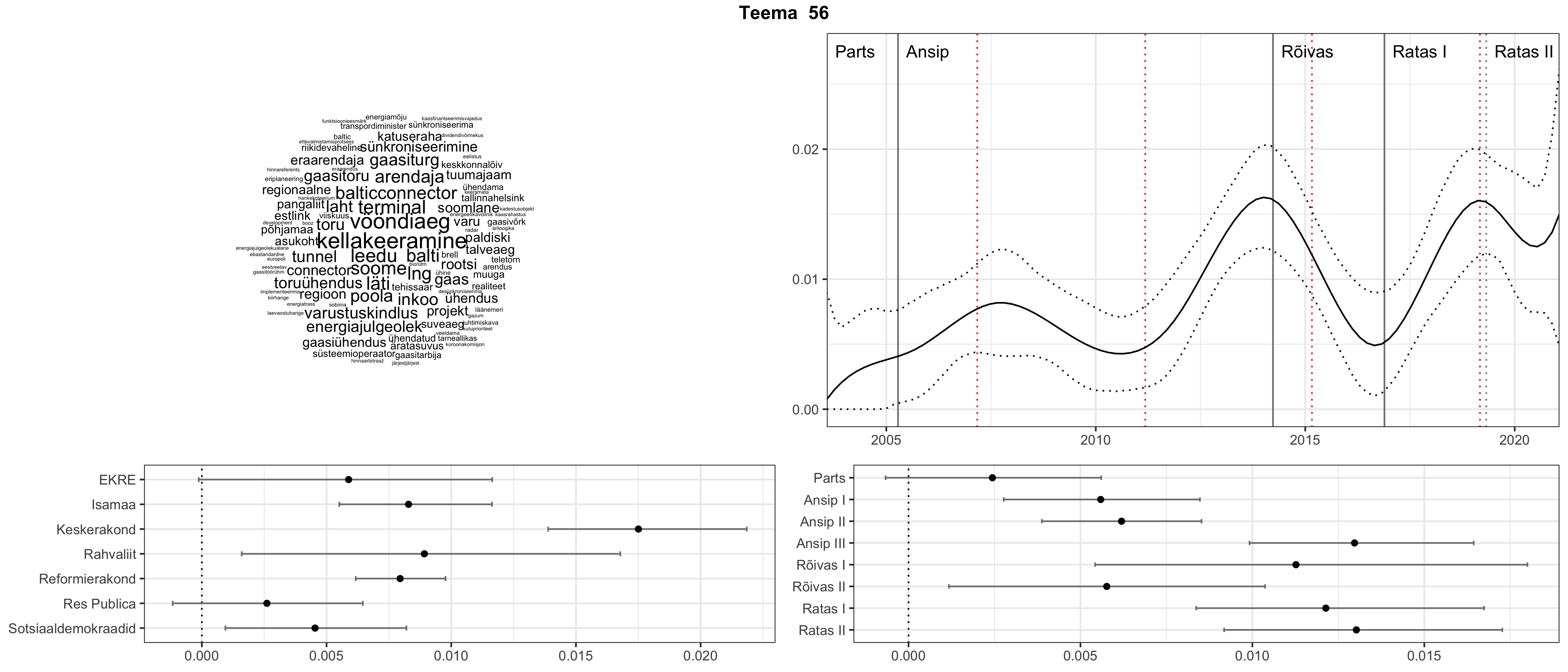
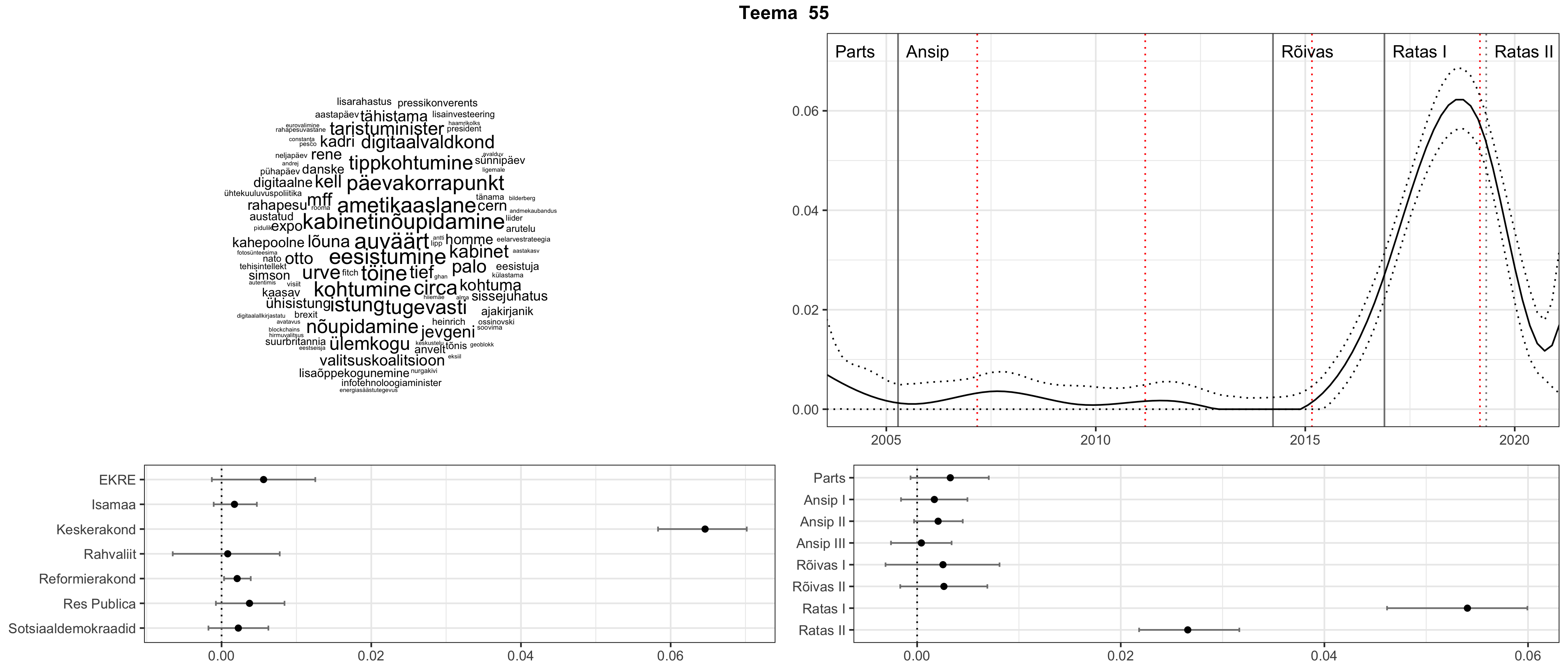
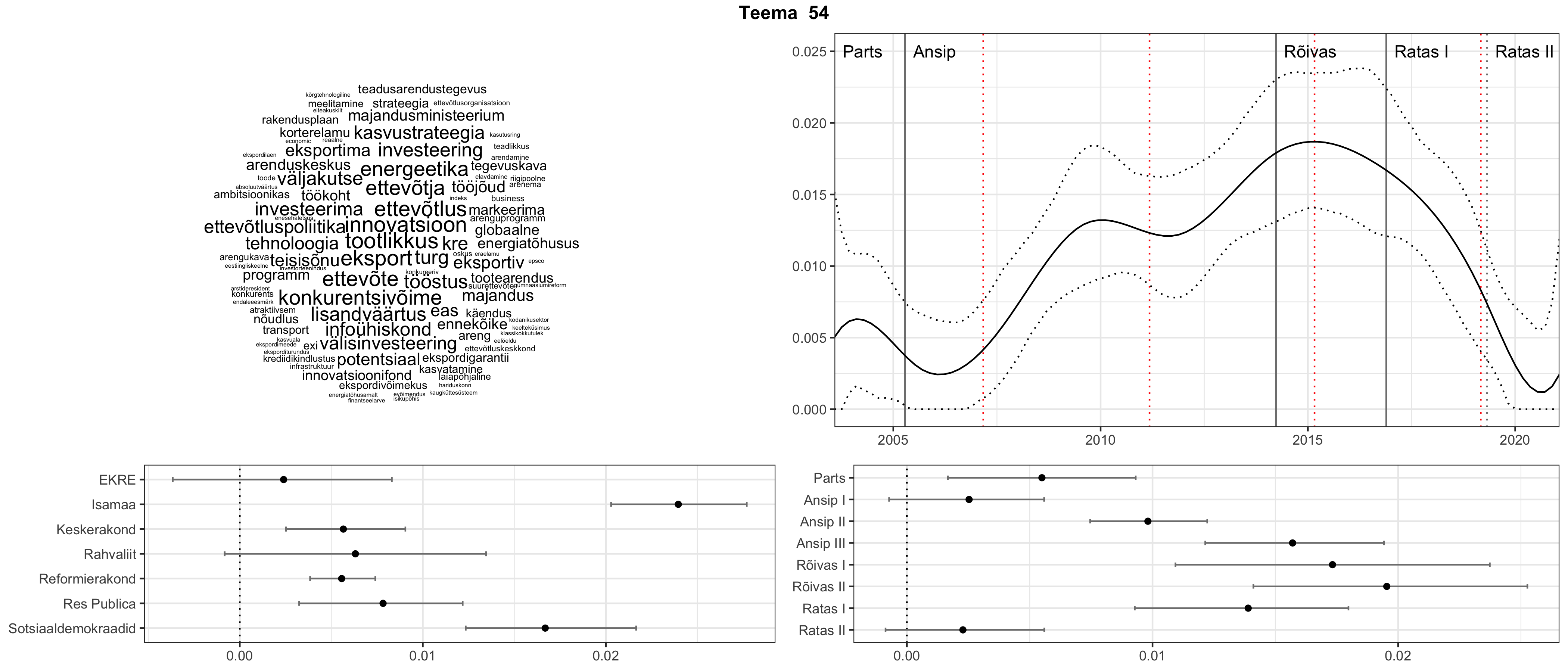
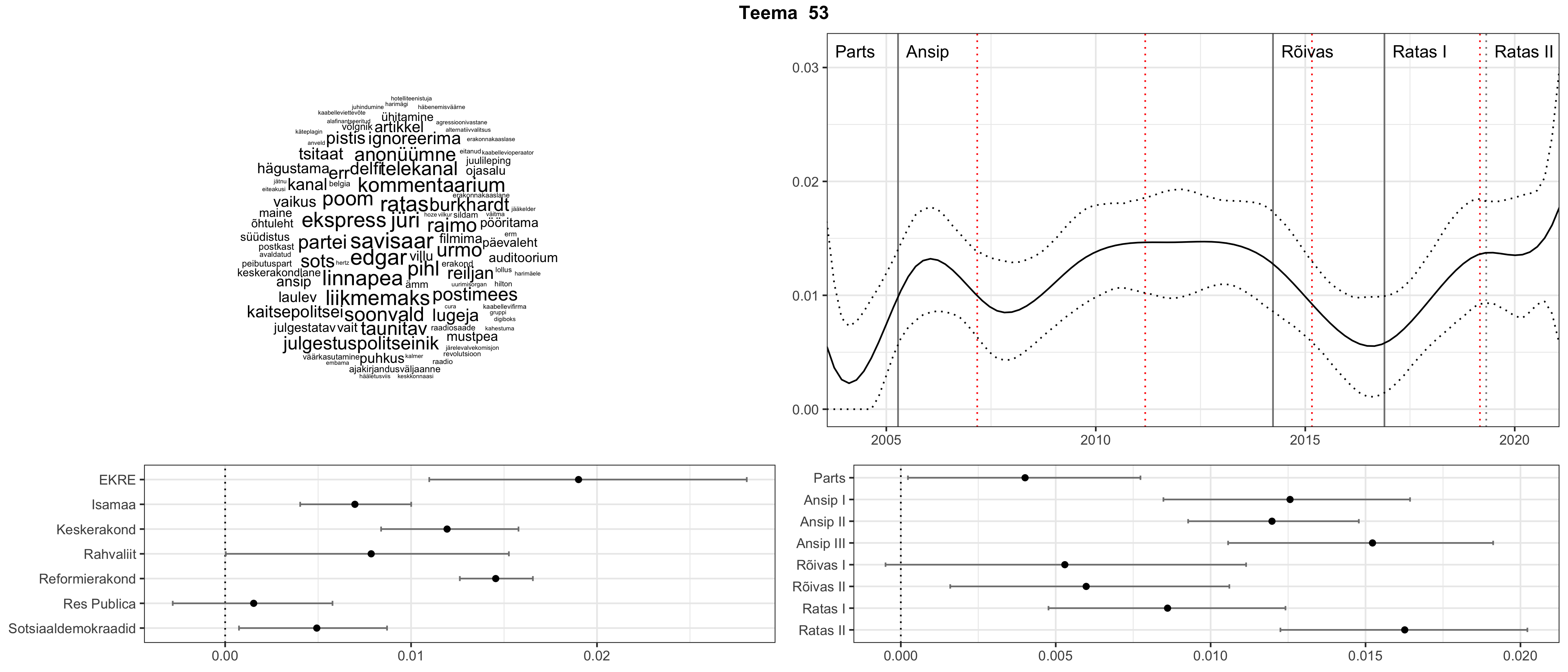
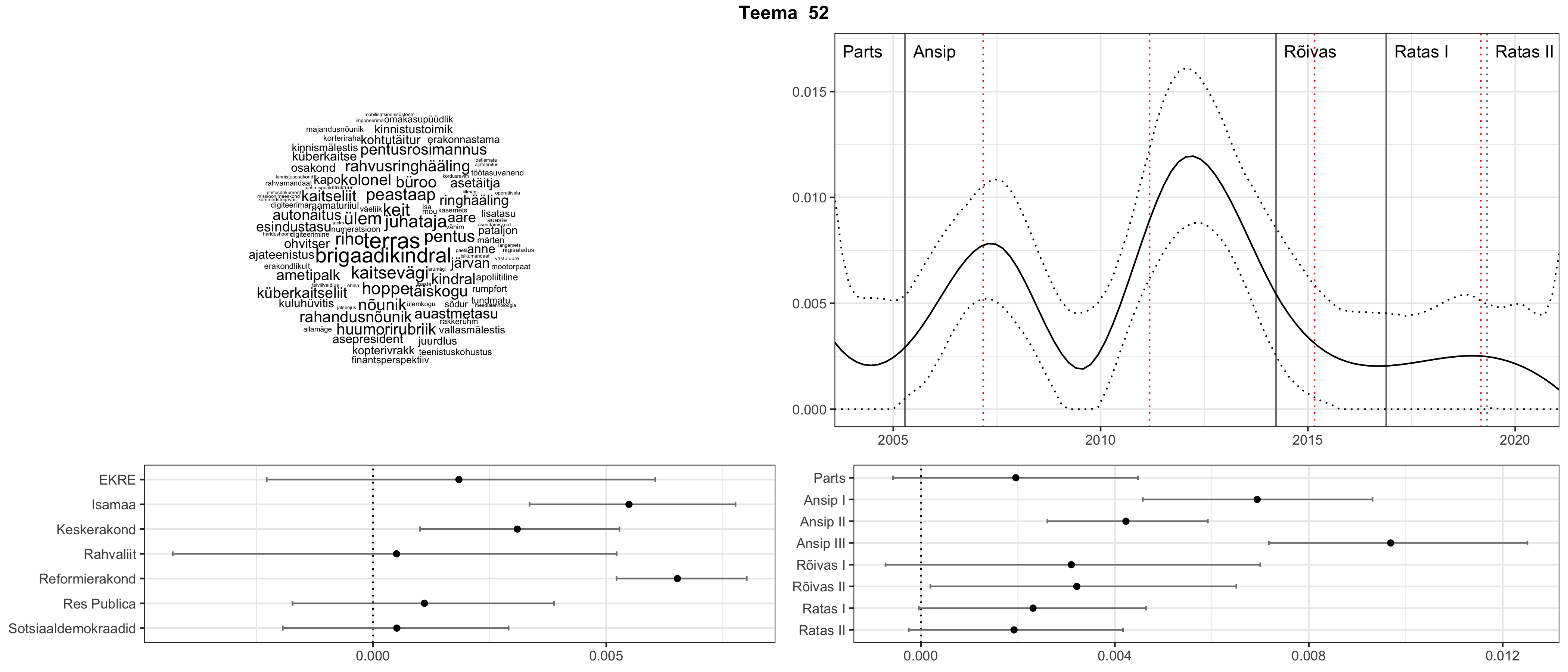
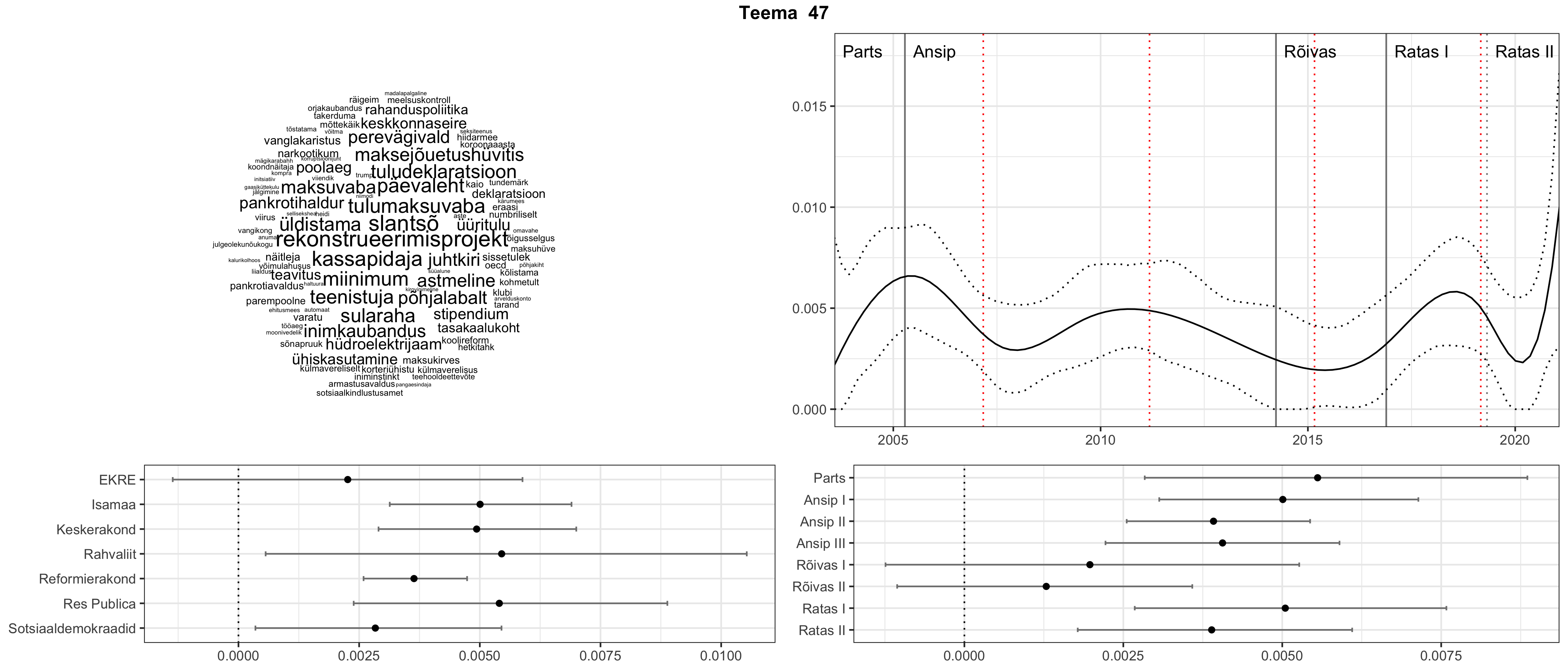
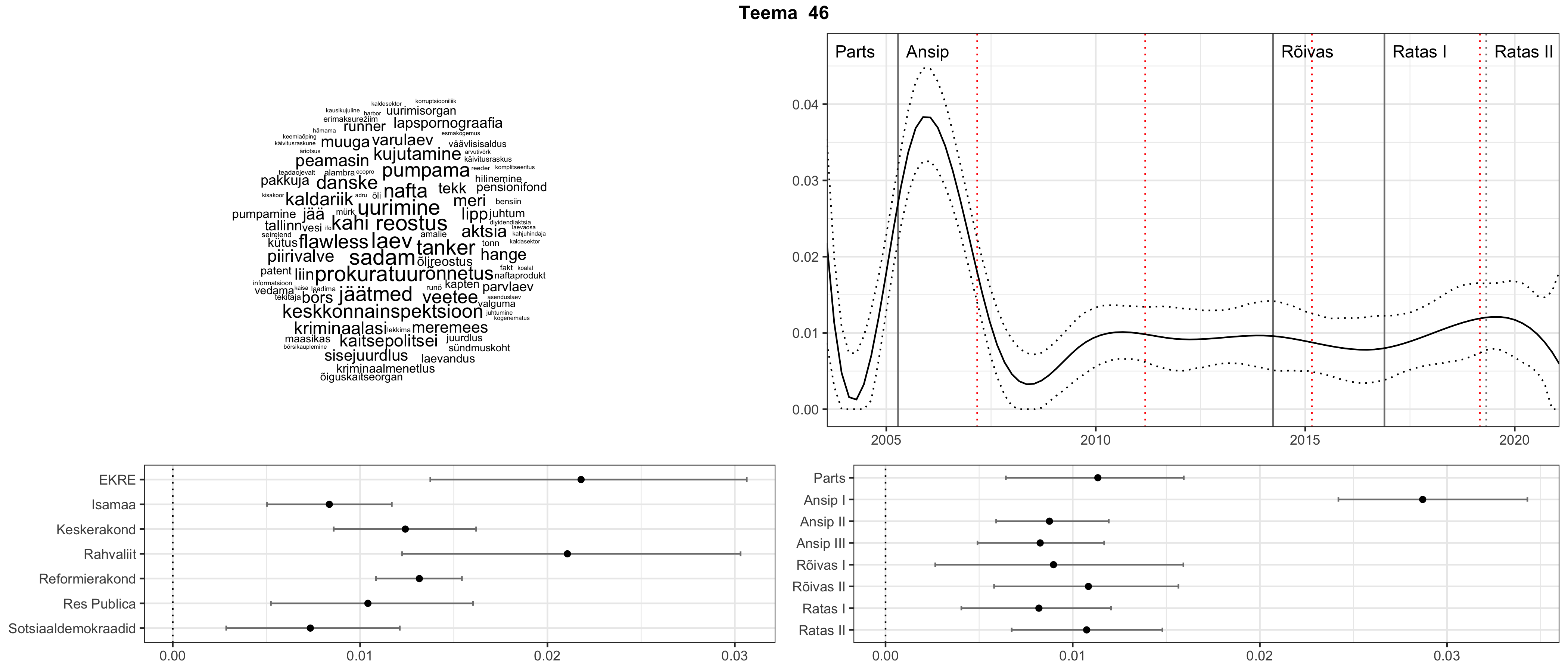
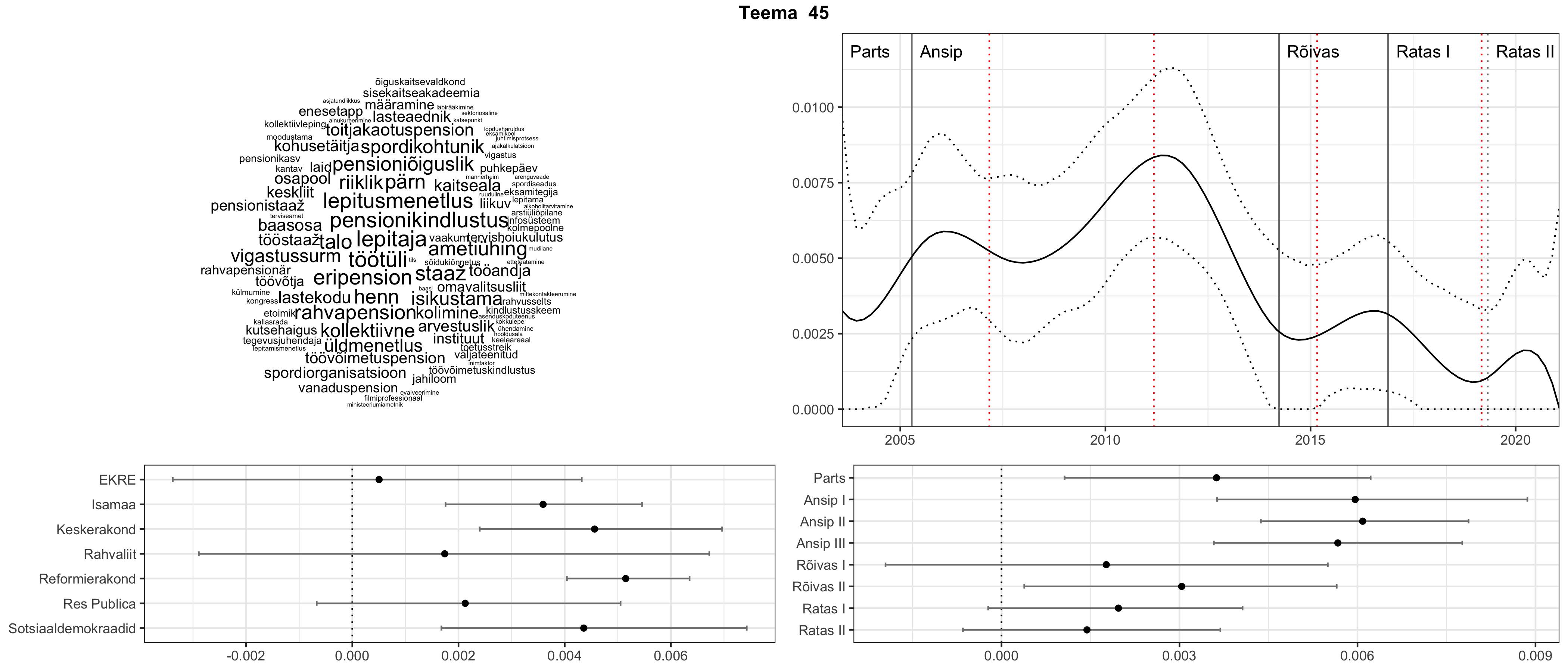
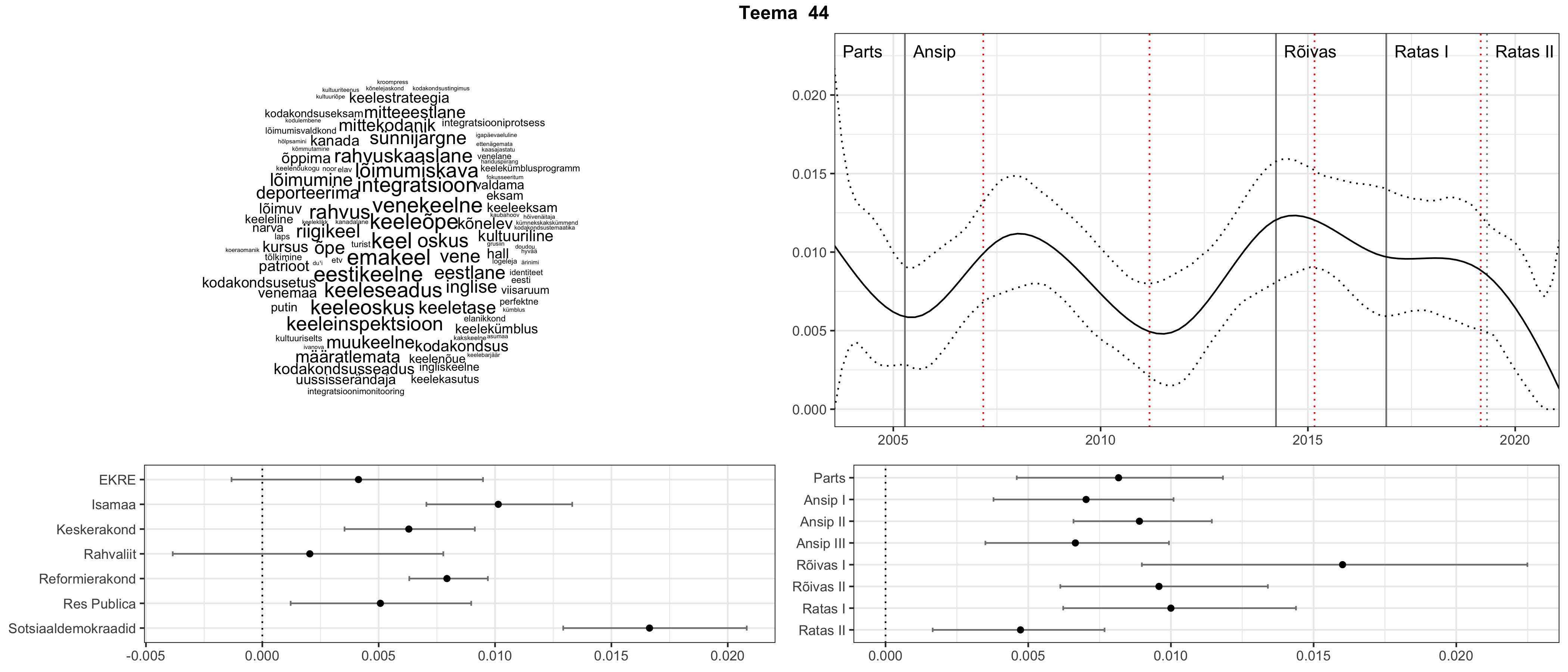
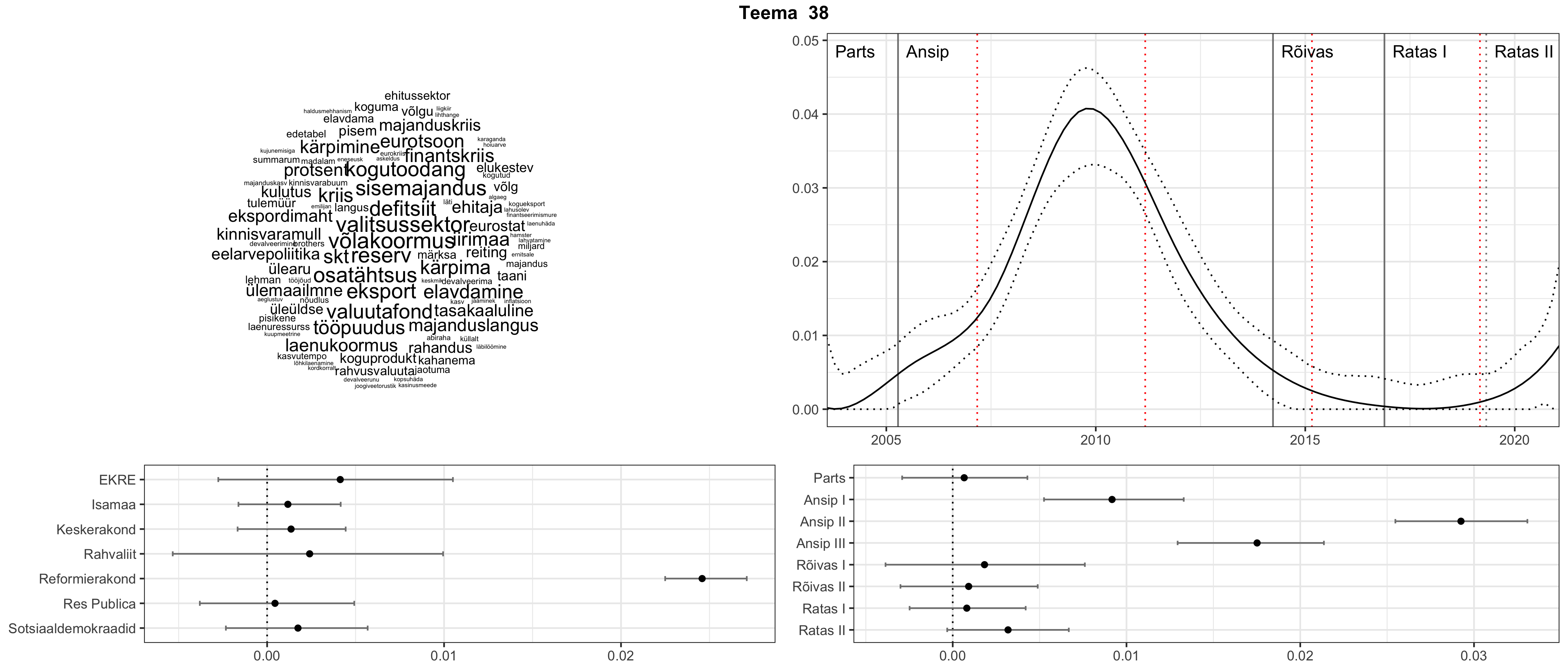
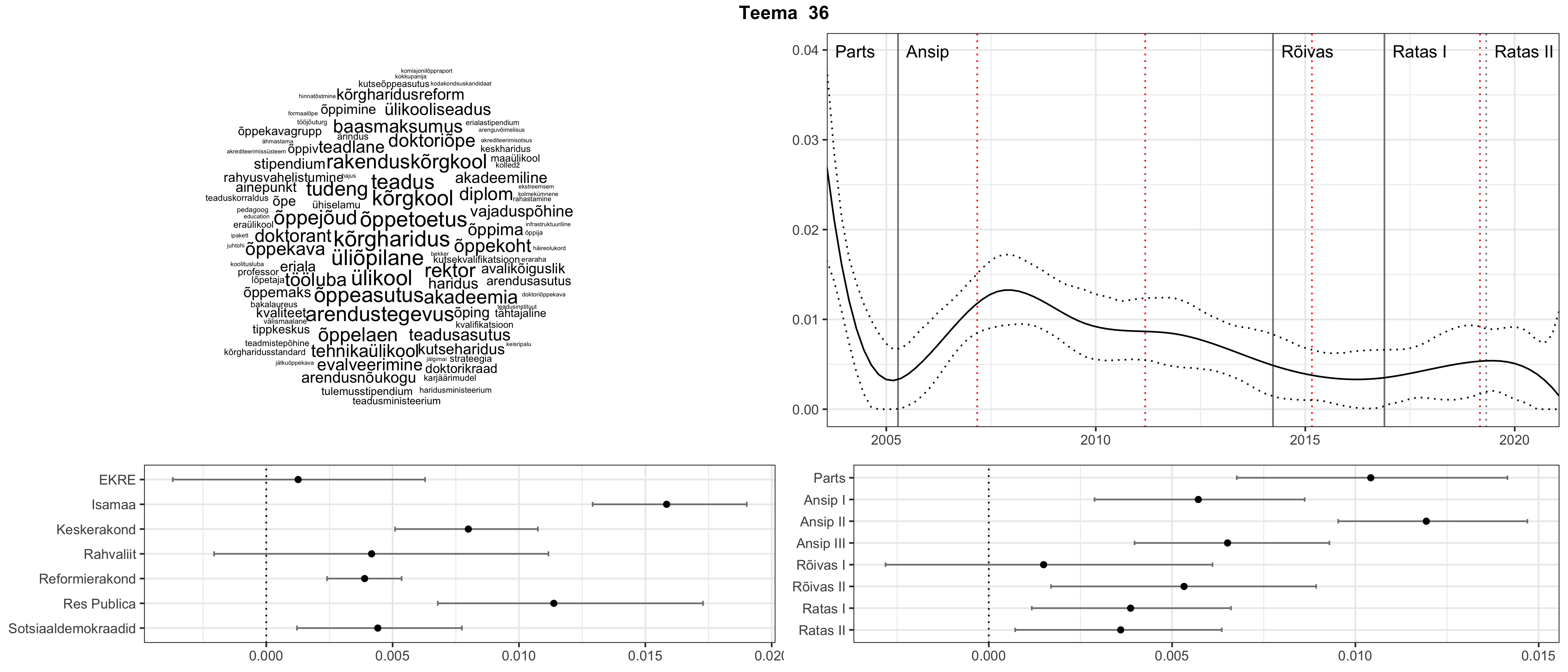
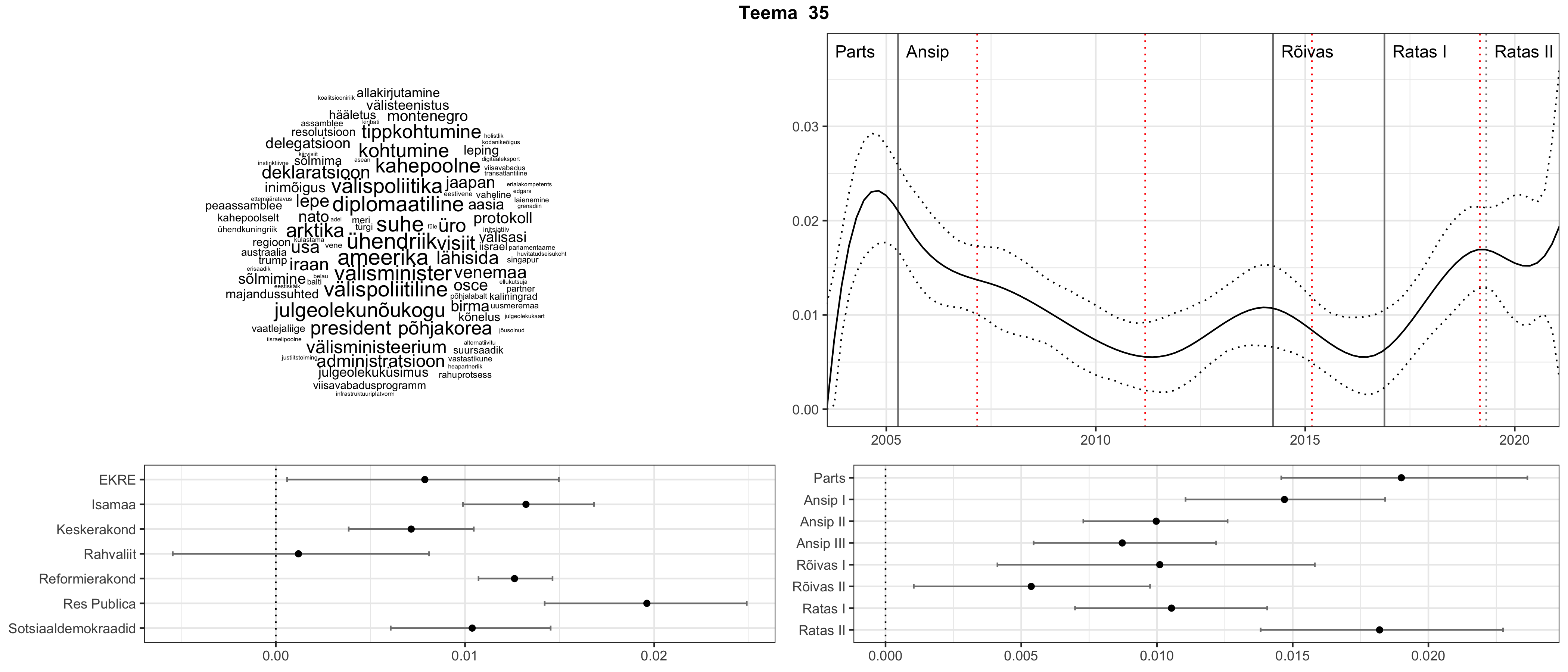
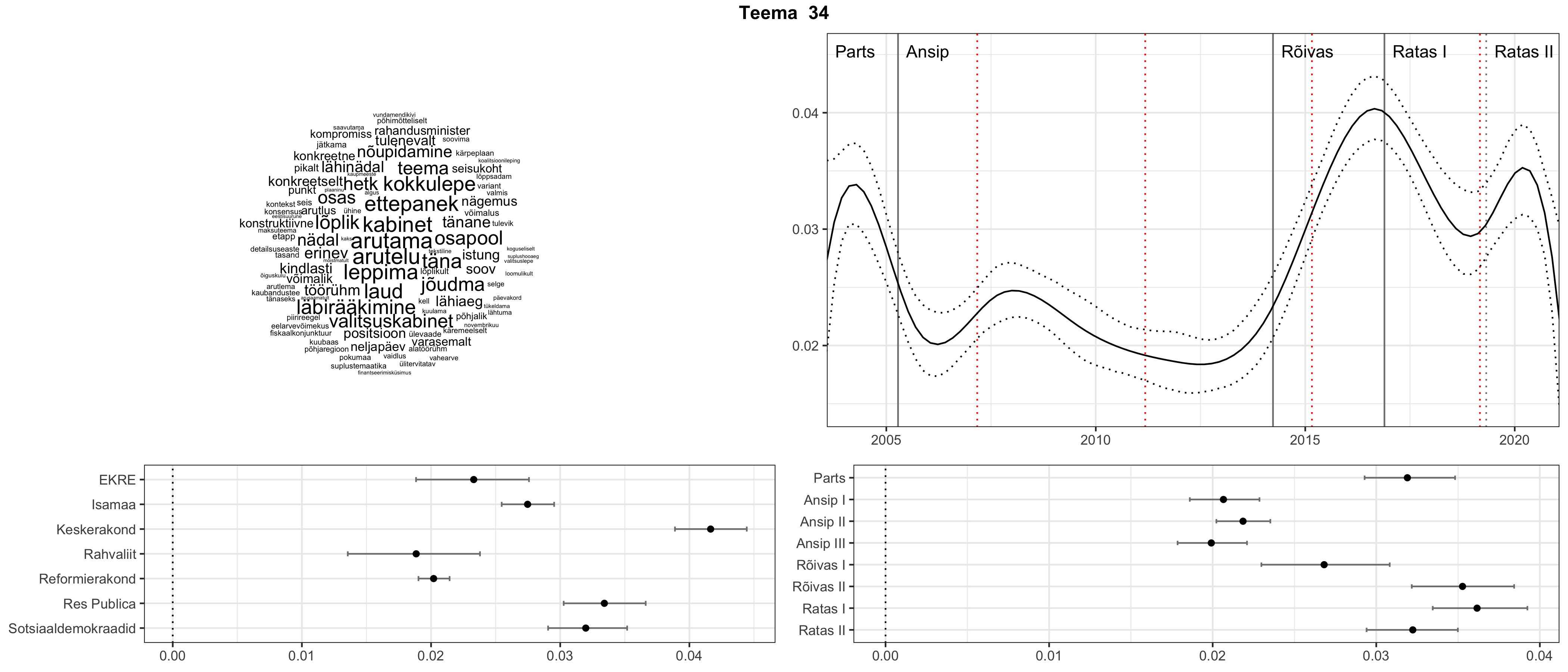
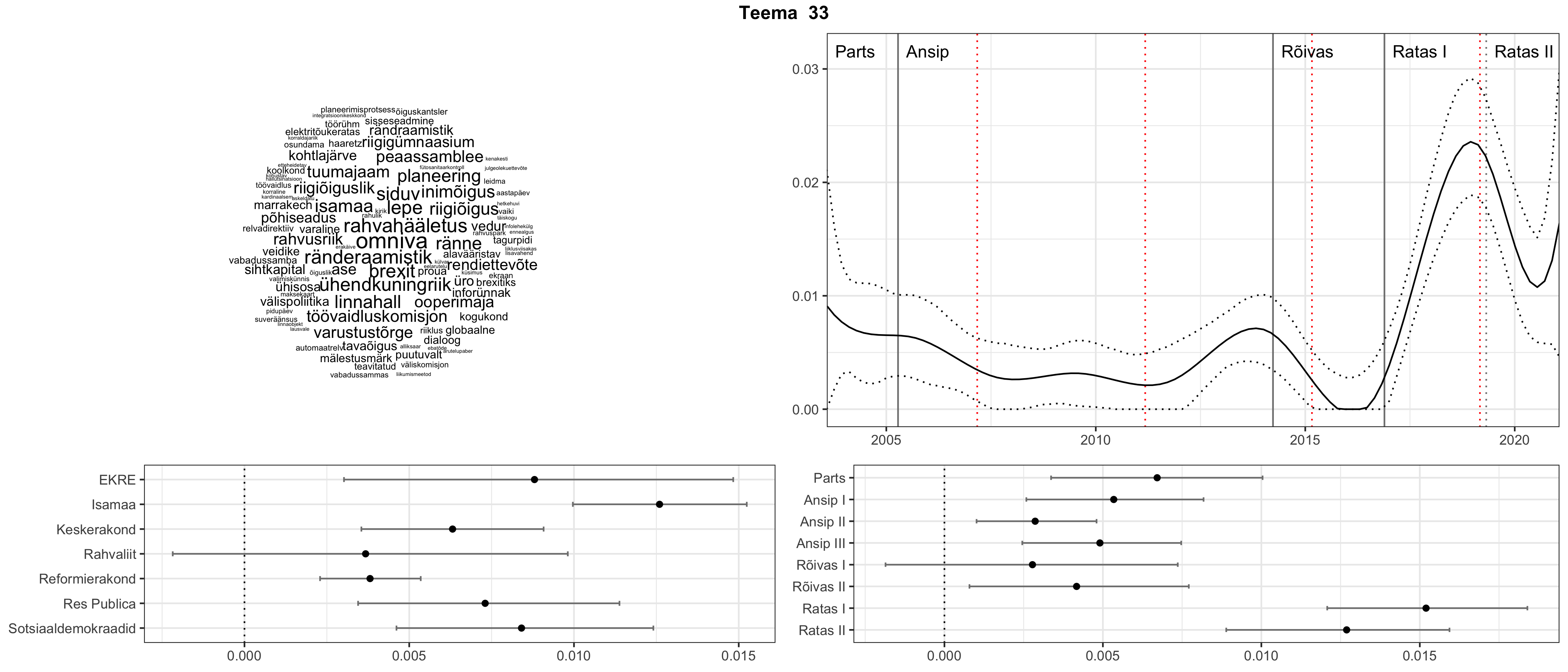
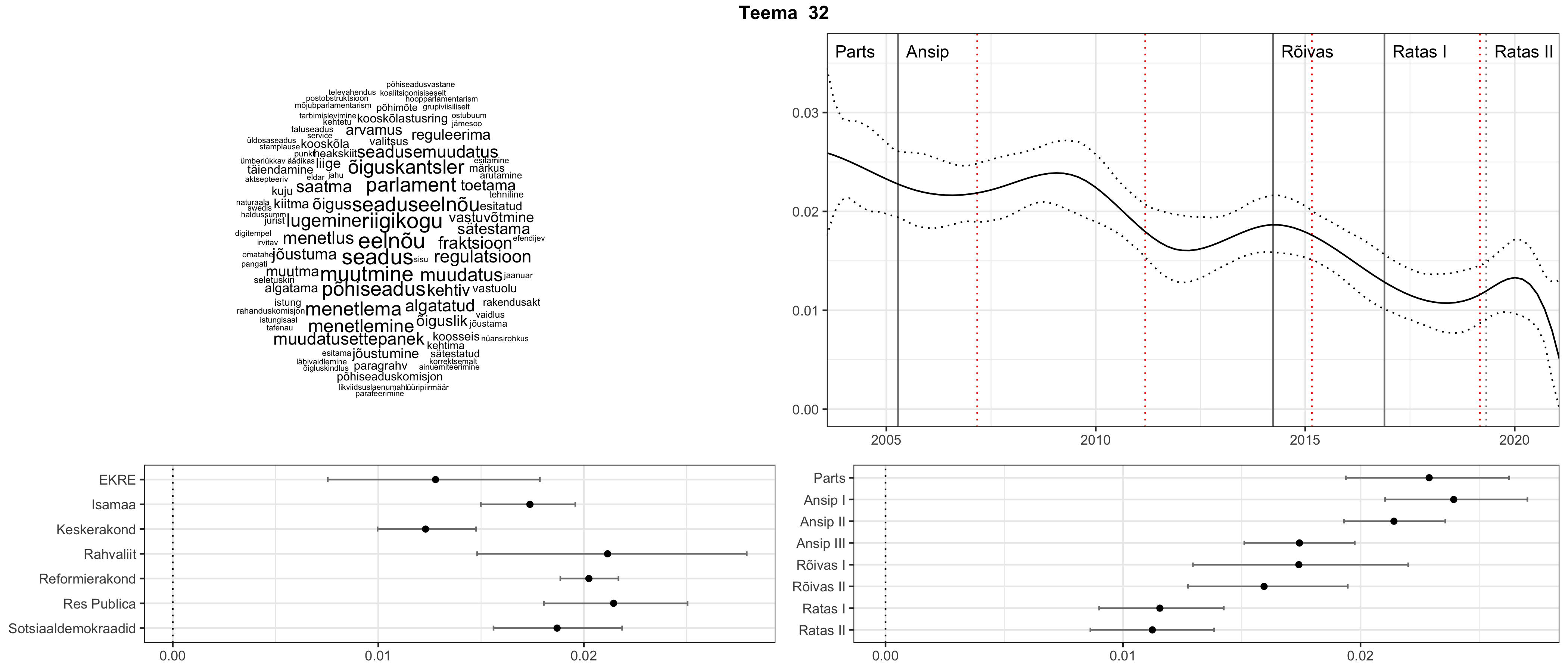
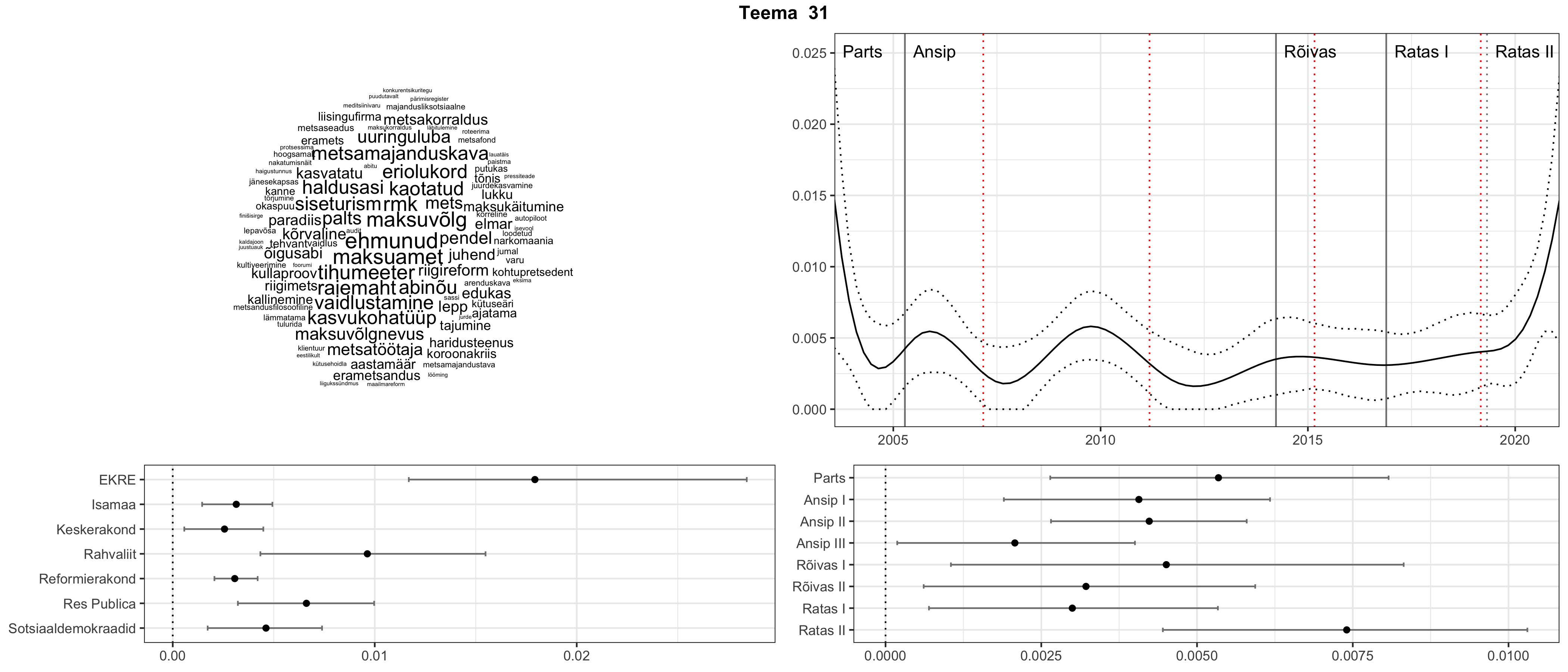
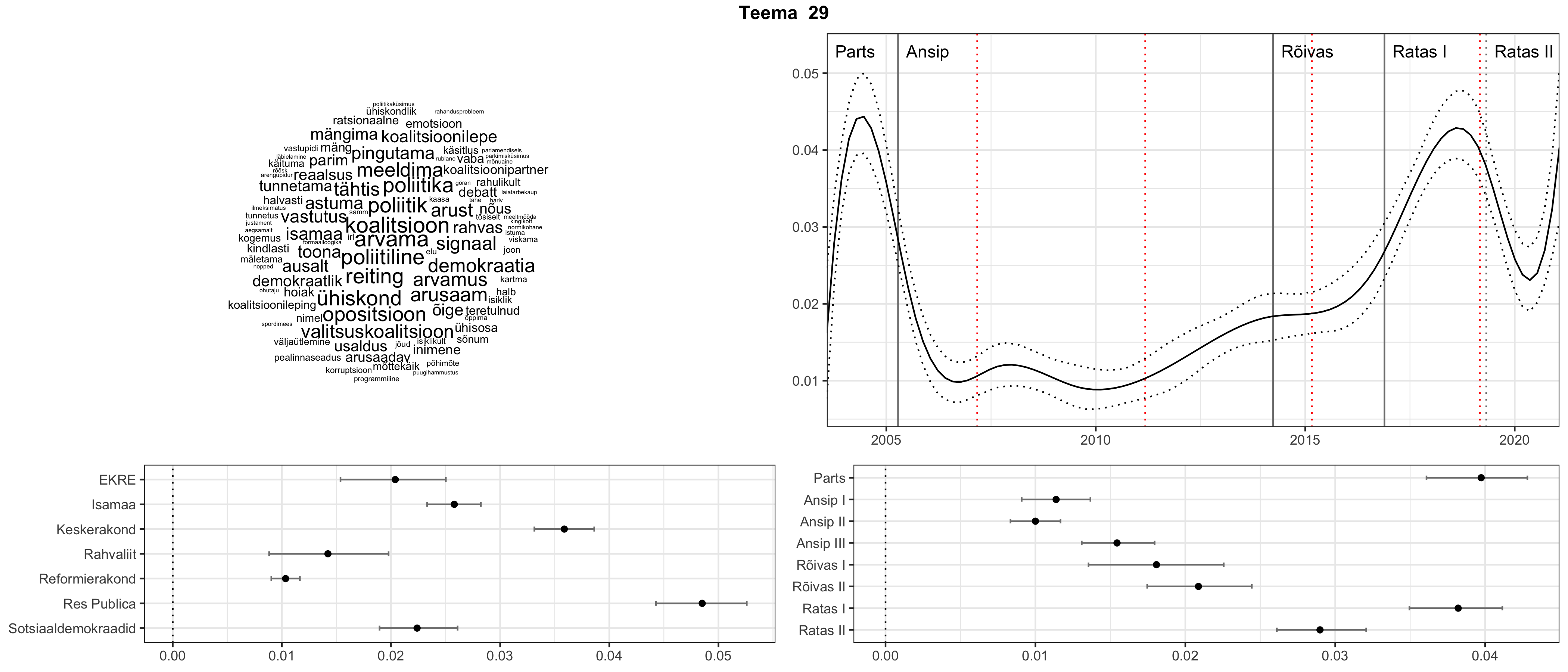
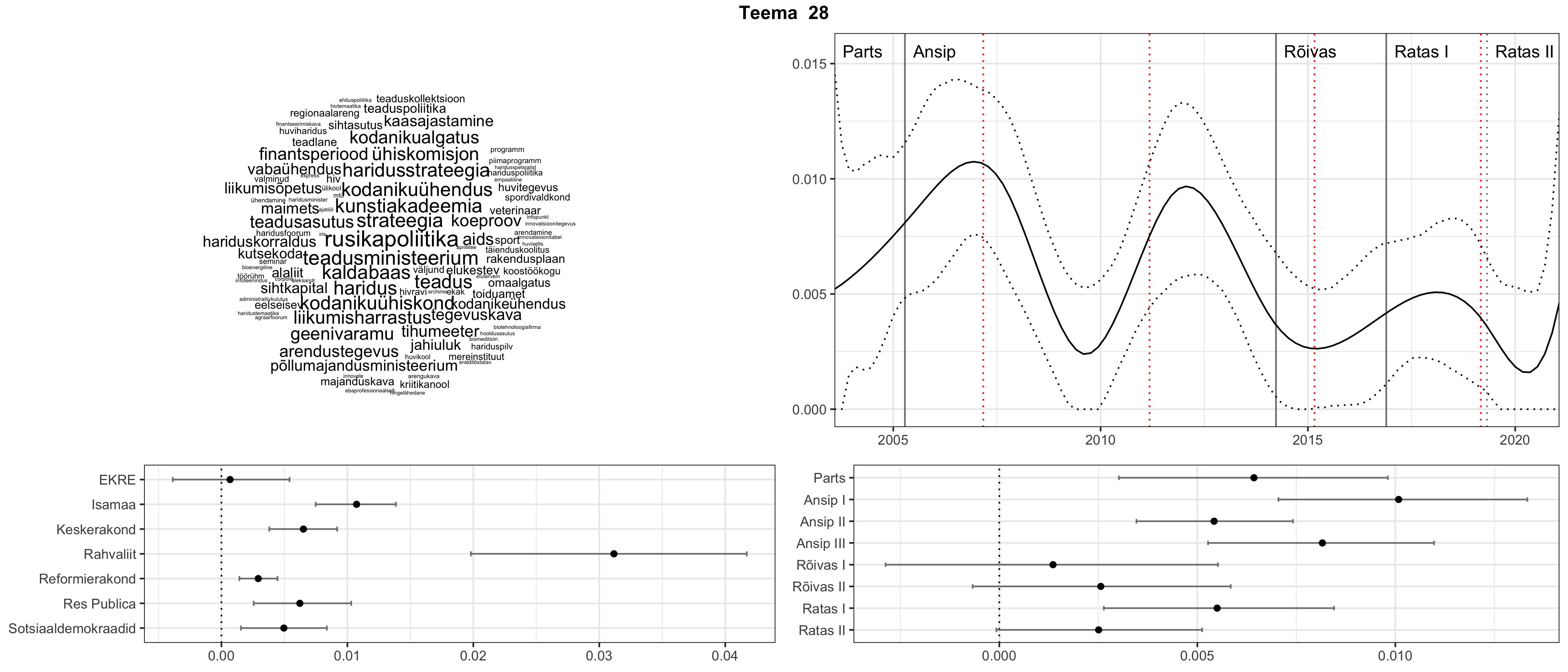
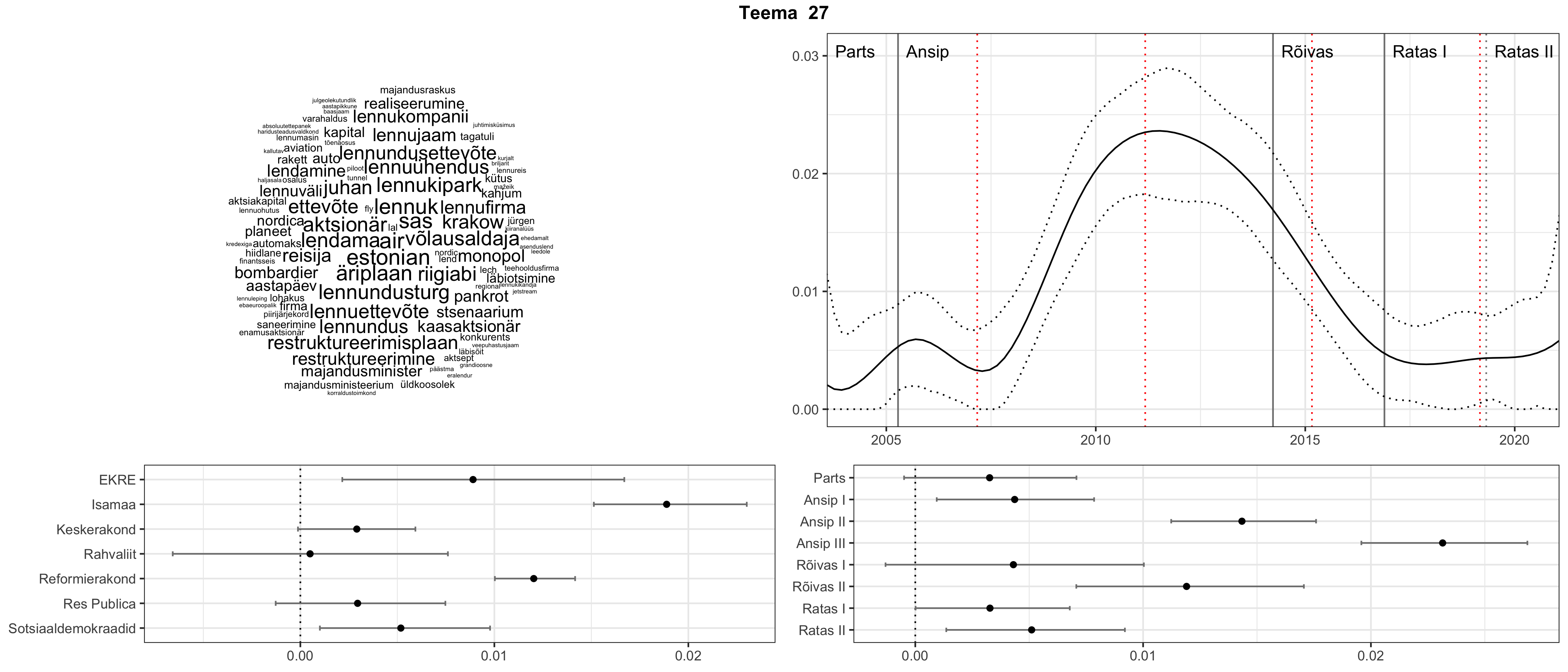
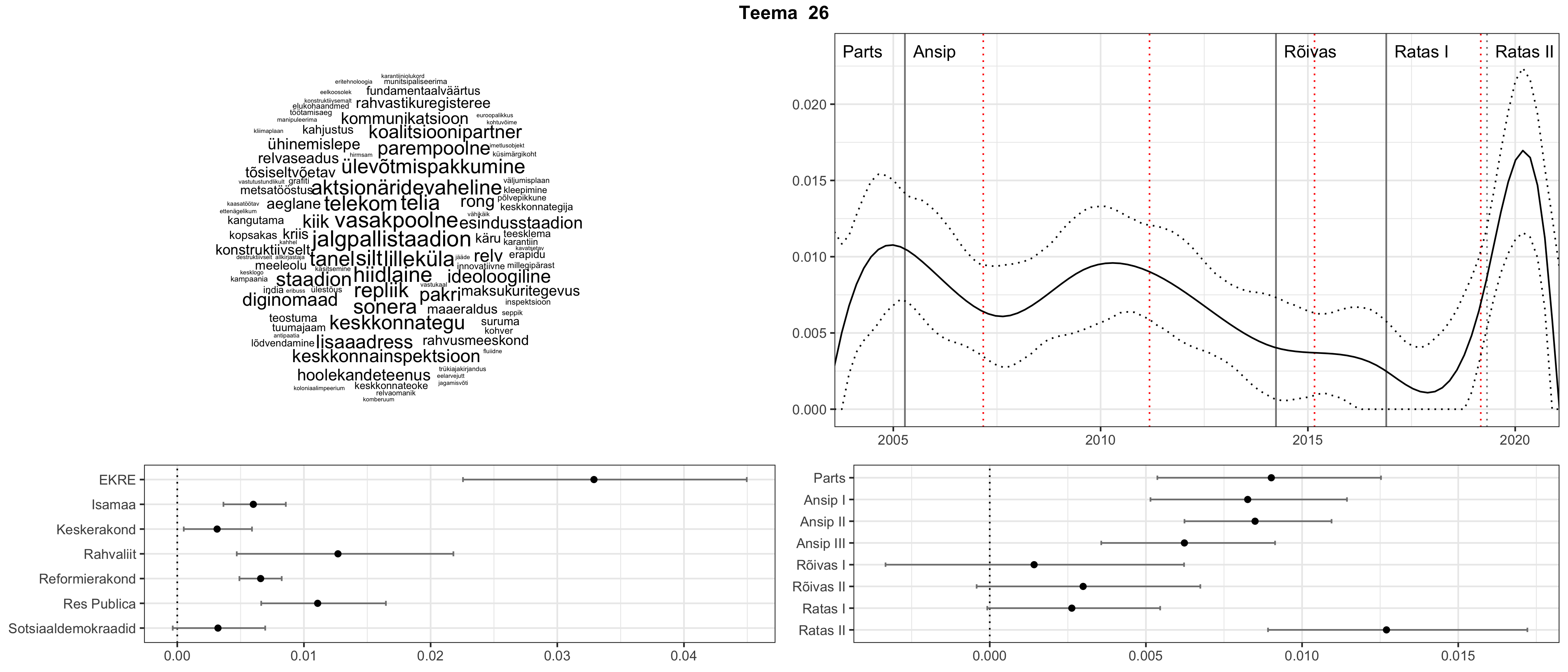
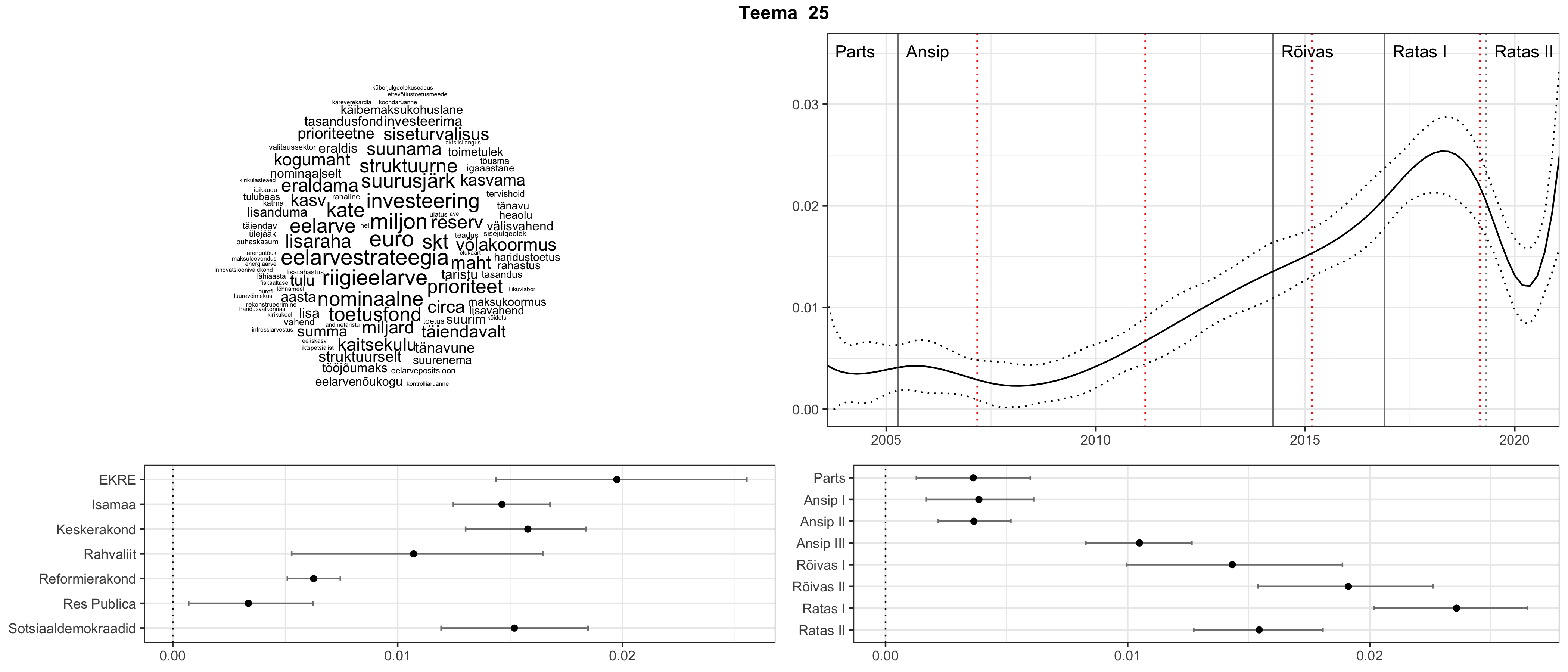
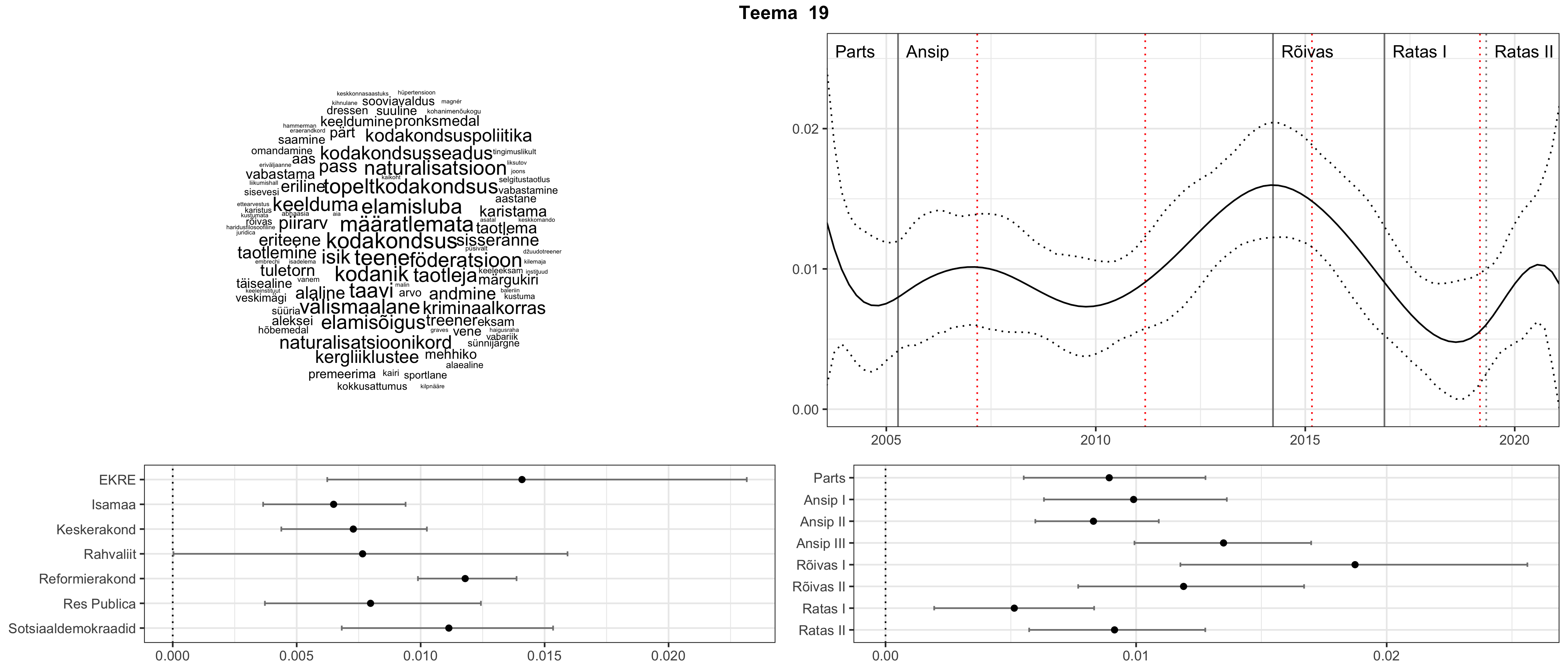
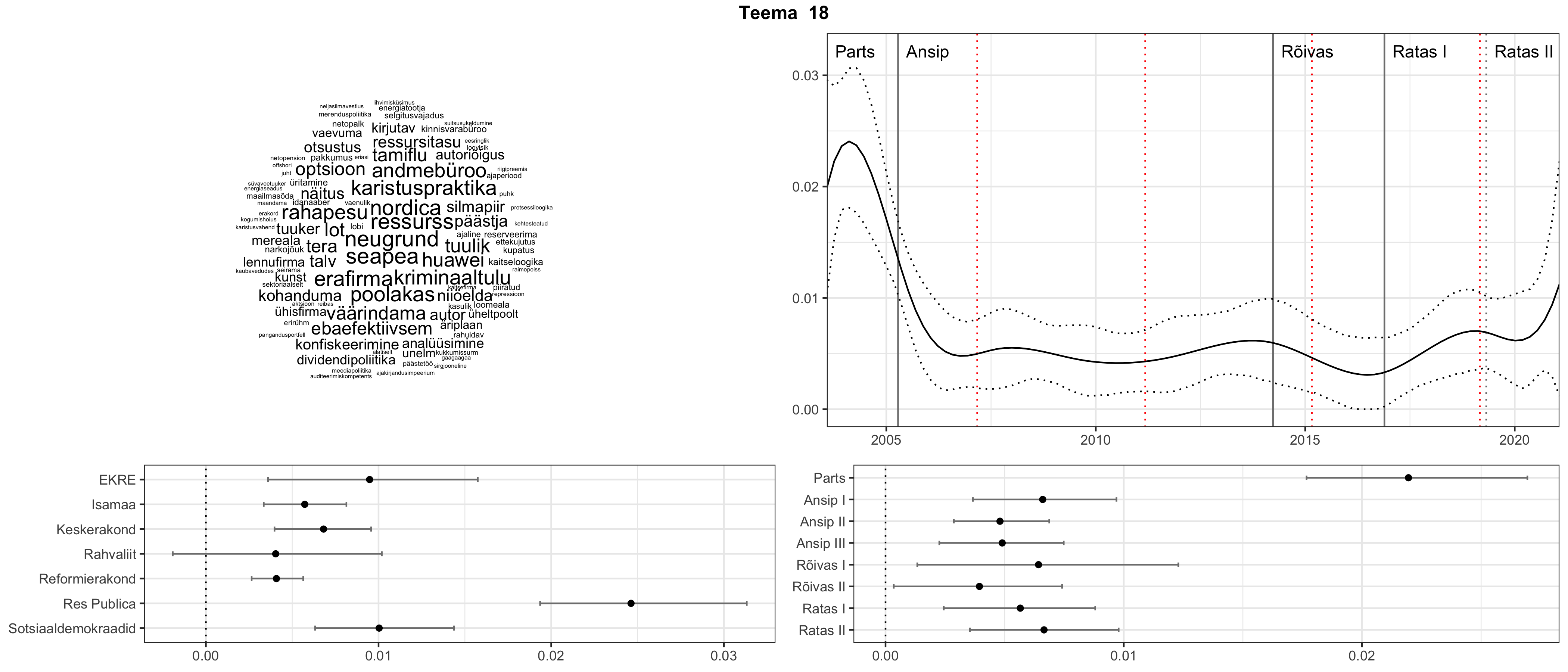
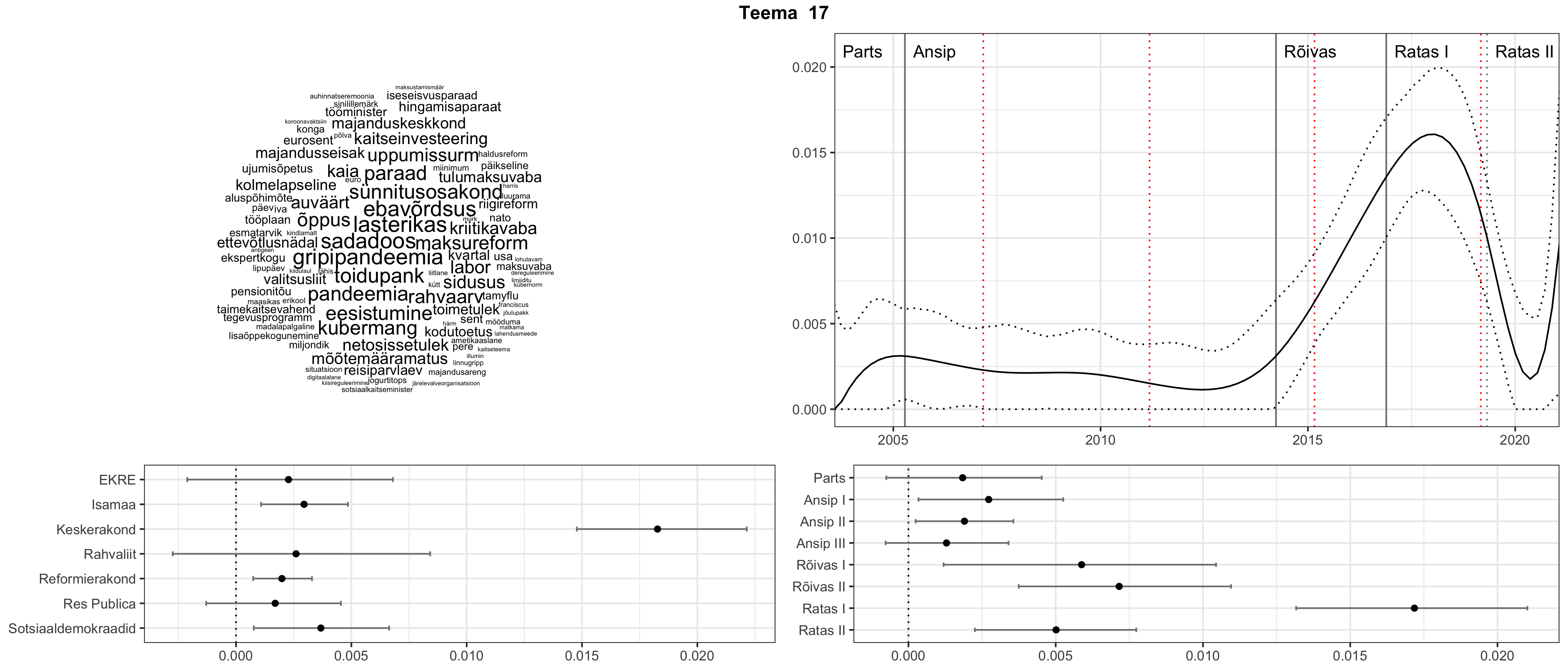
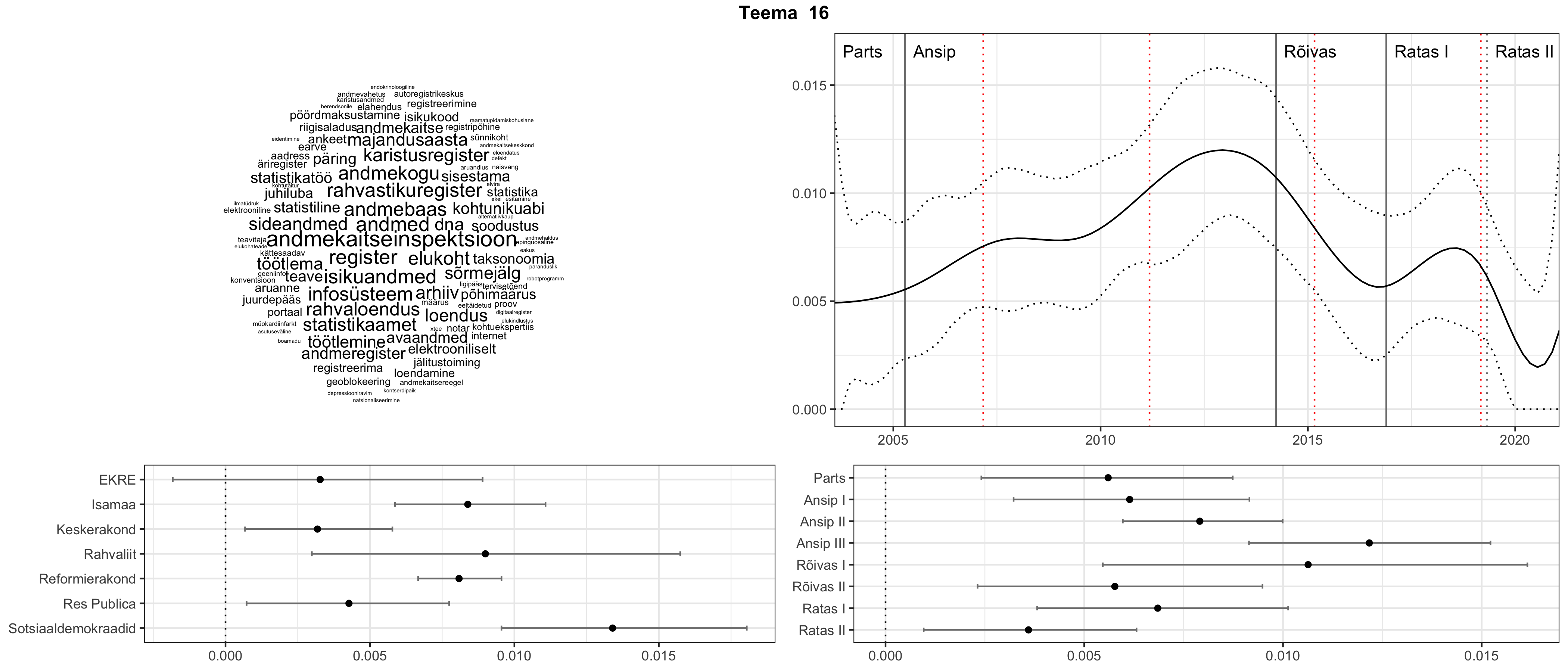
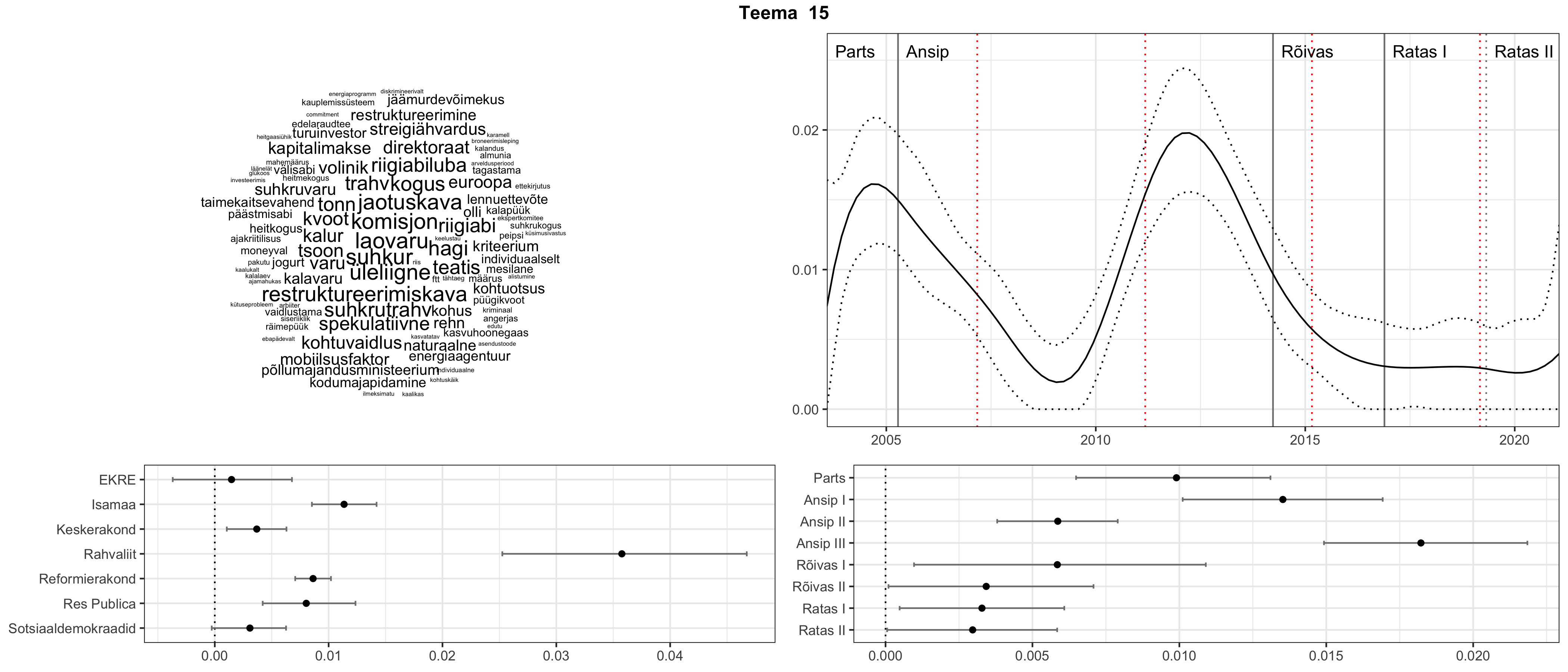
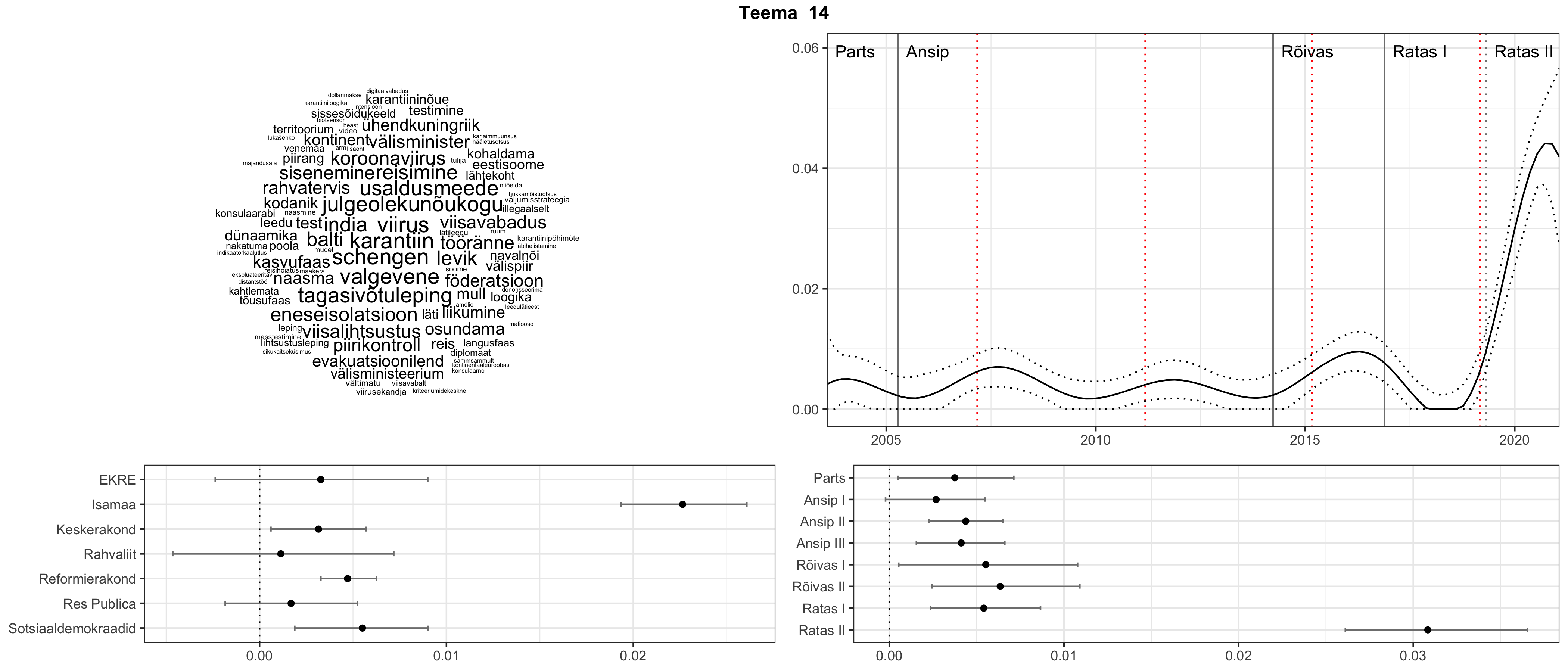
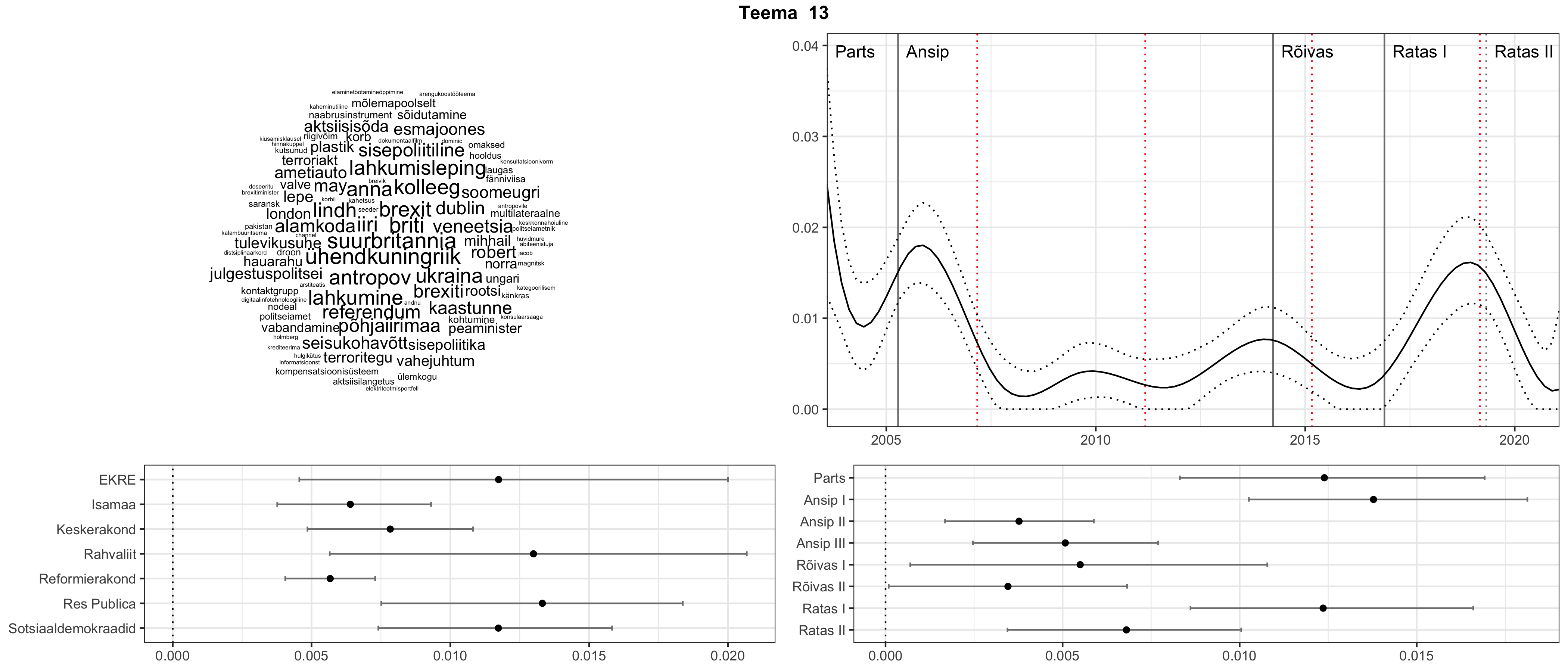
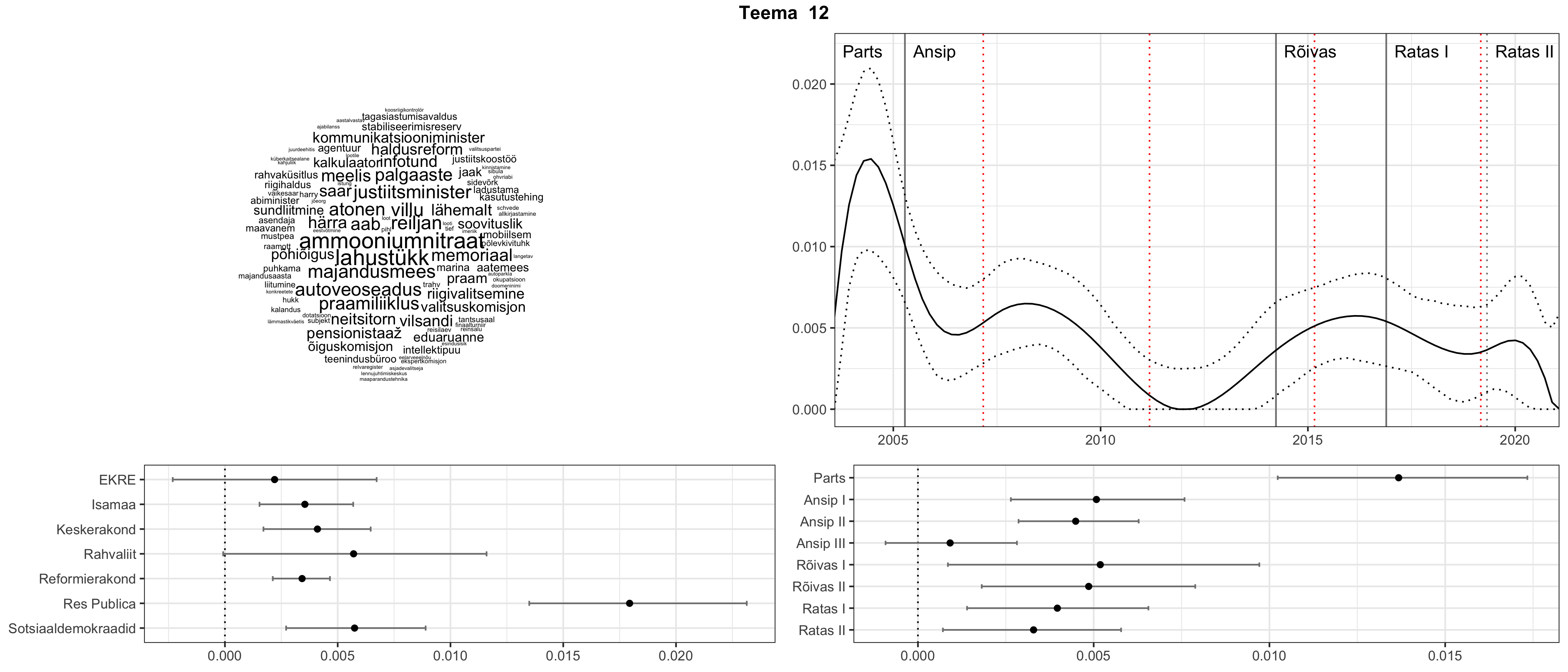
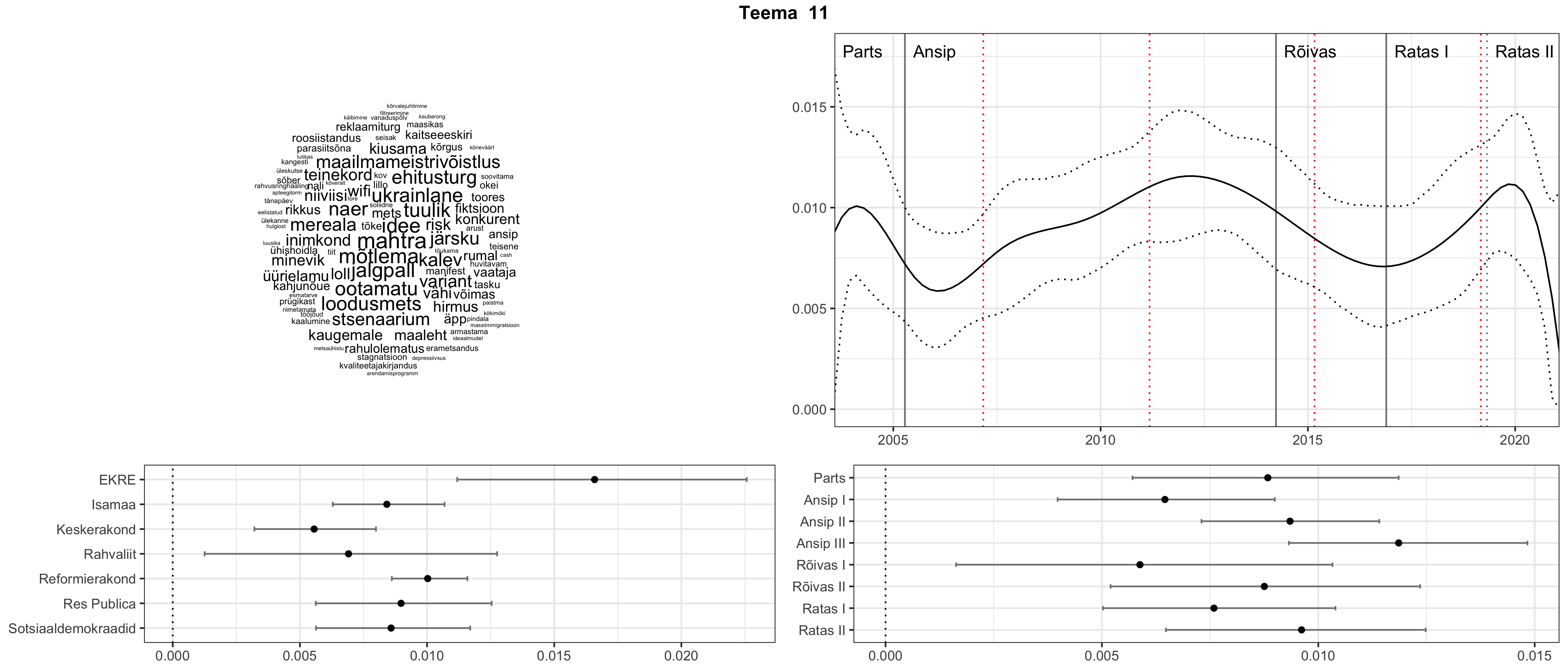
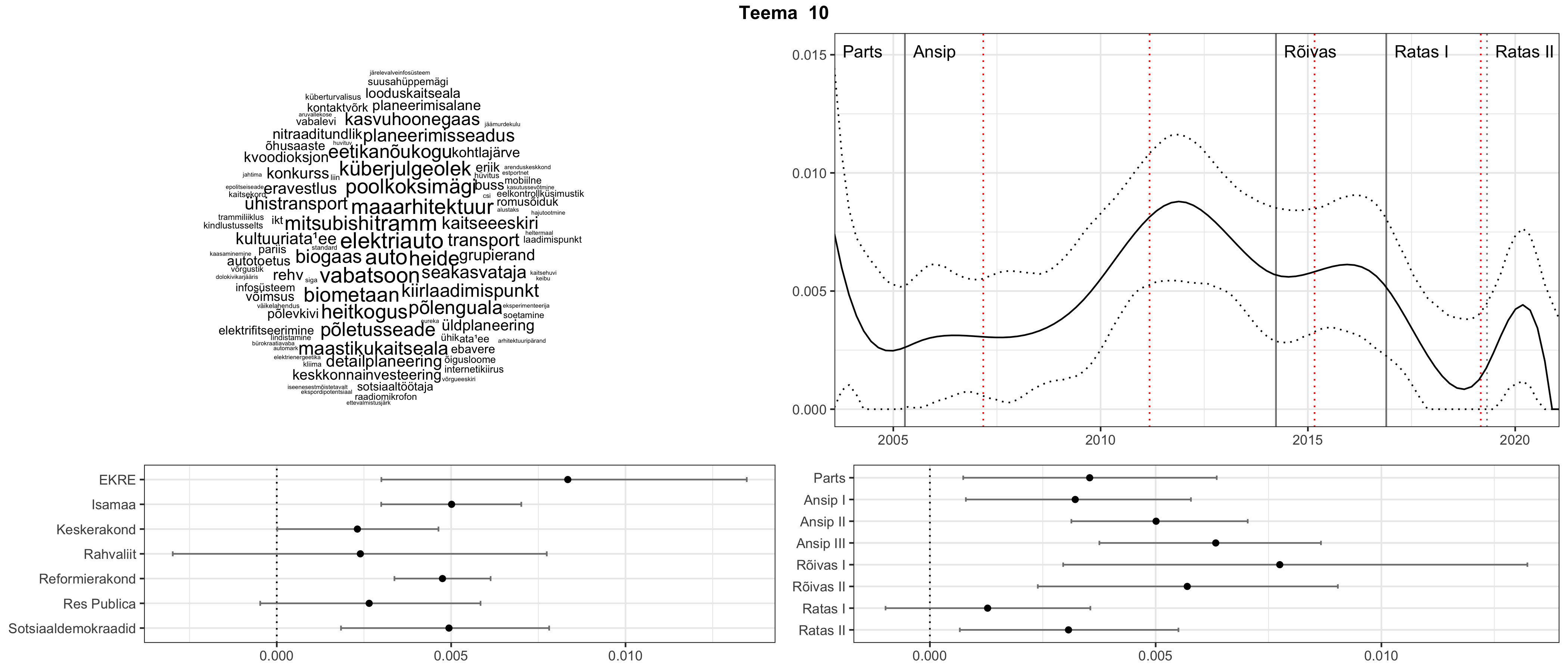
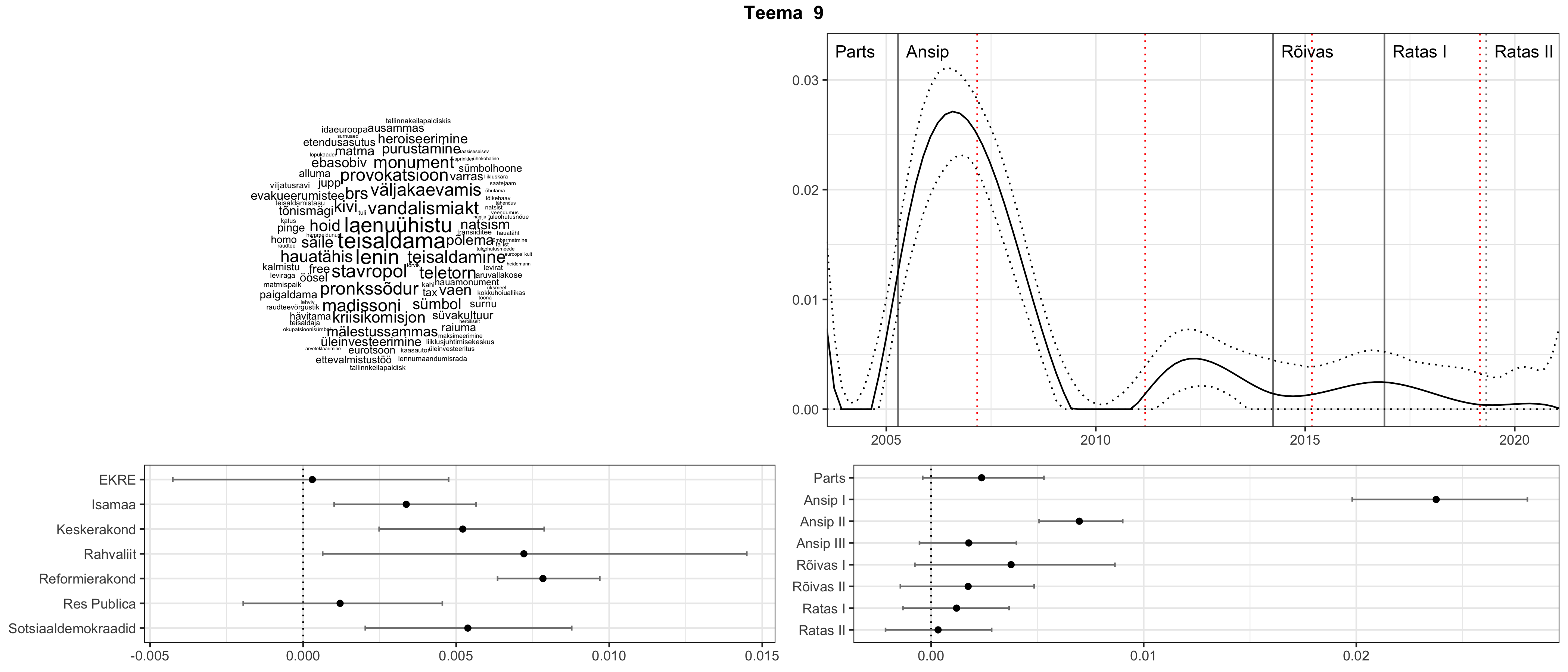
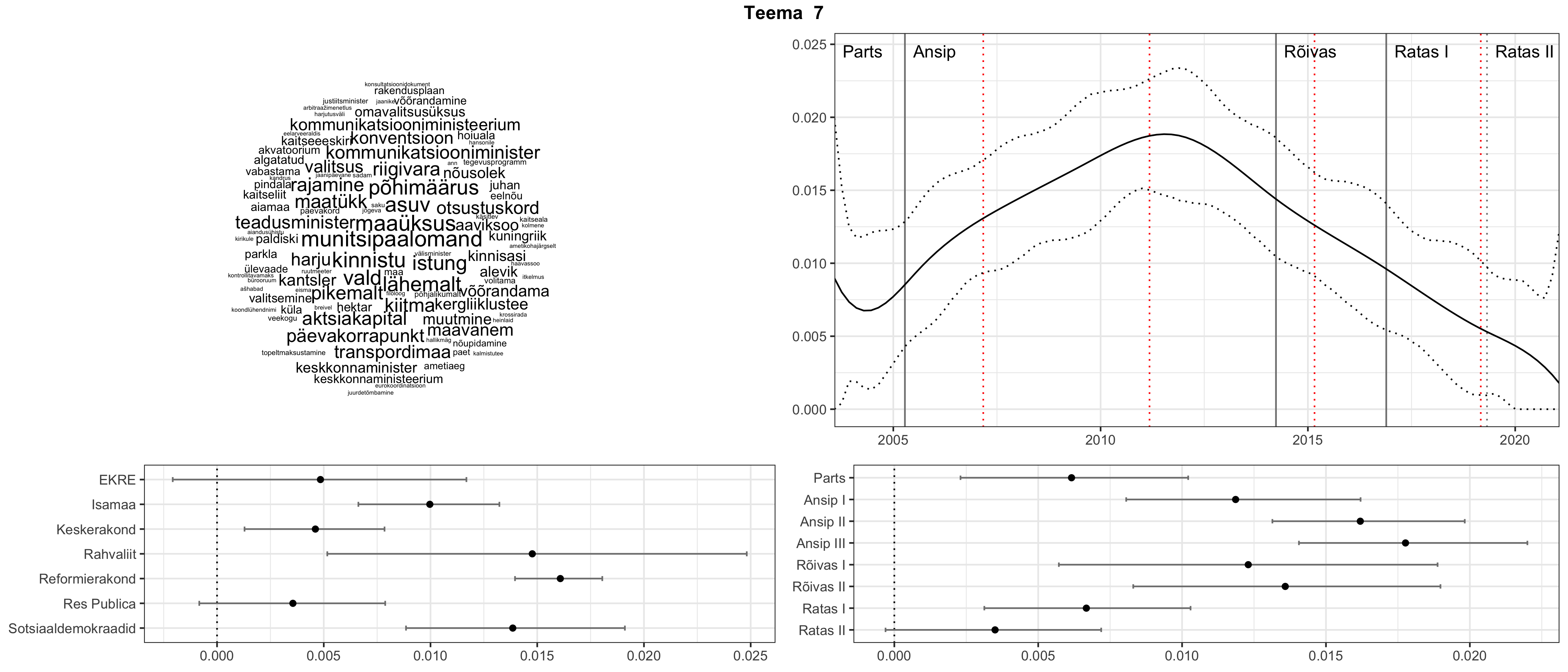
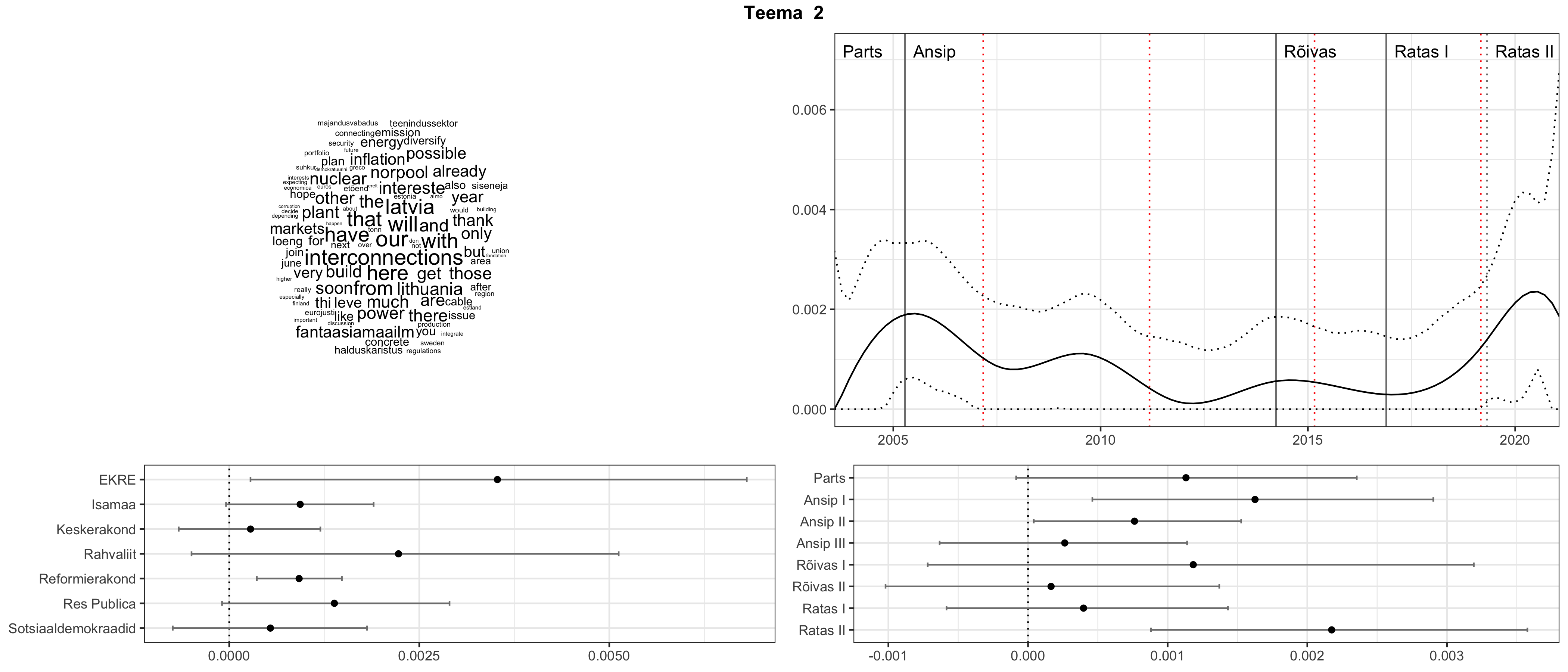
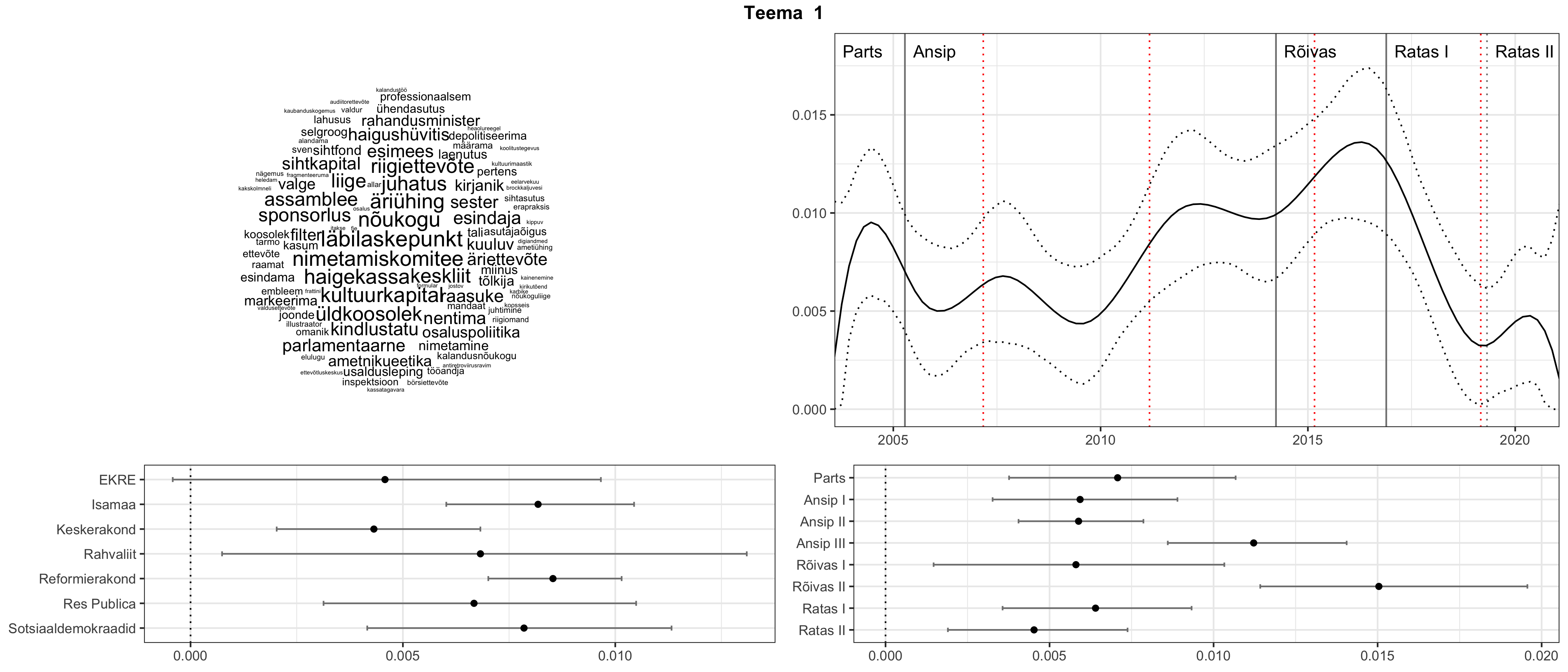
Allpool välja toodud tulemused pärinevad mudelitest, mis tuvastasid 116 teemat (teemade arv on valitud top2vec mudeli järgi, mis tuvastab automaatselt sobiva arvu teemasid).
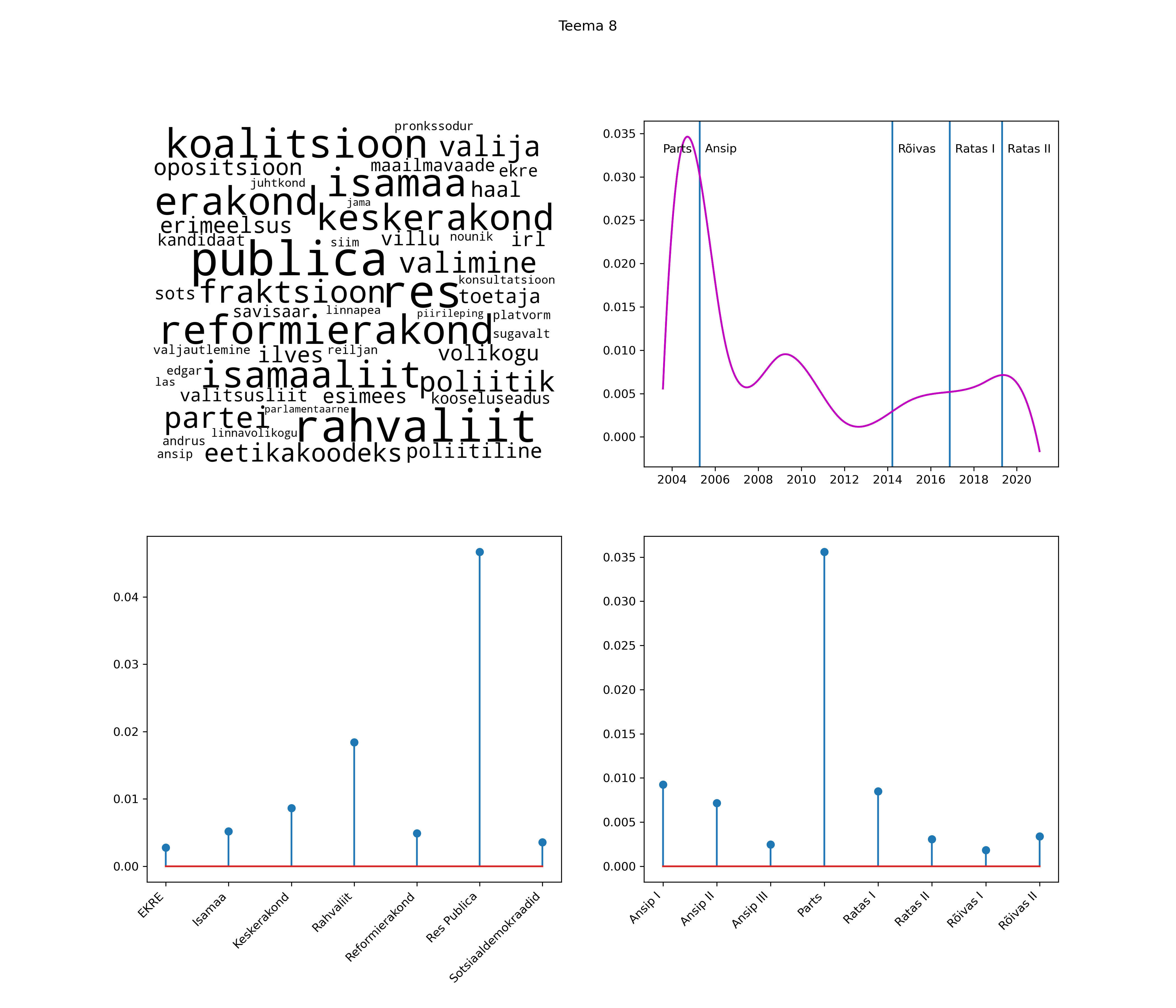
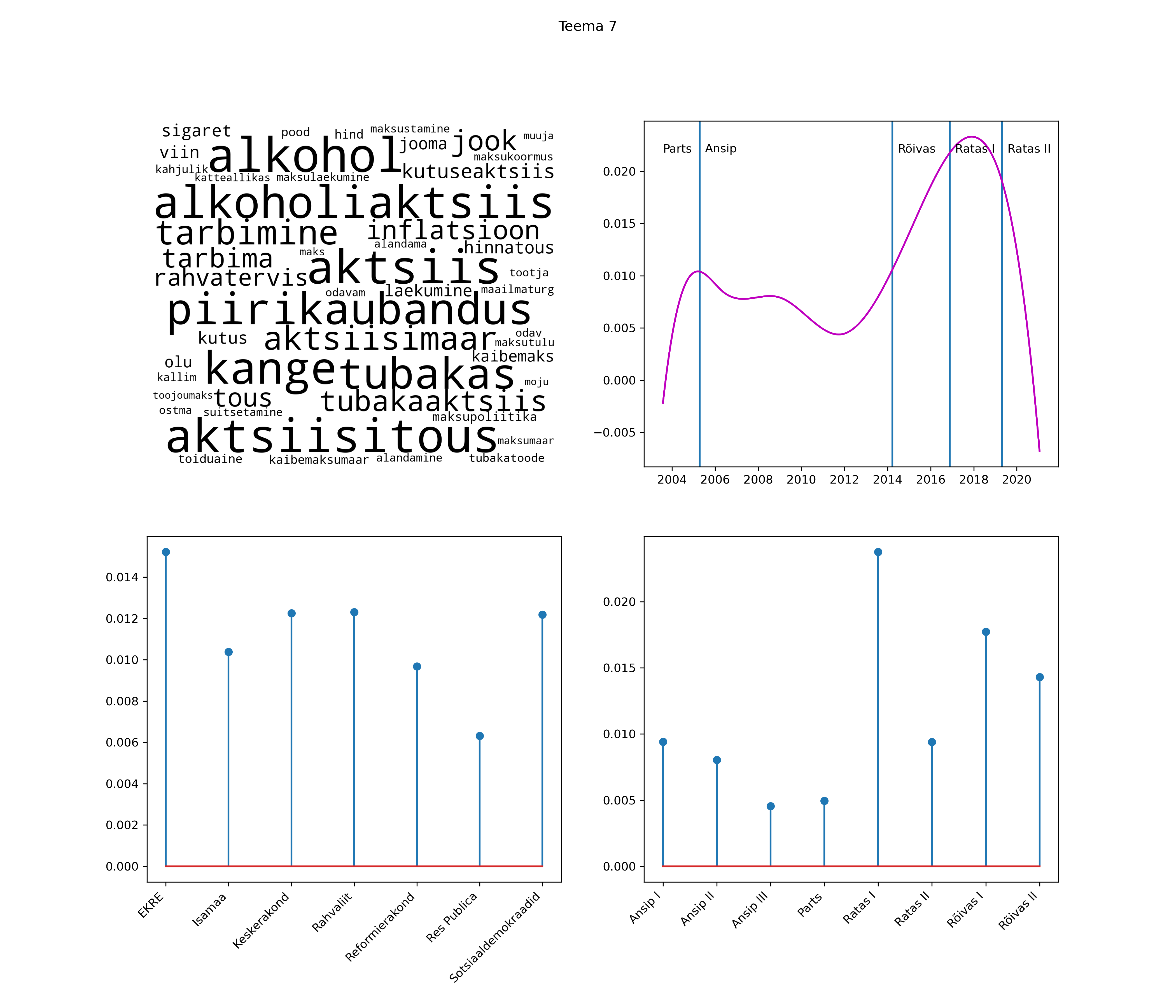
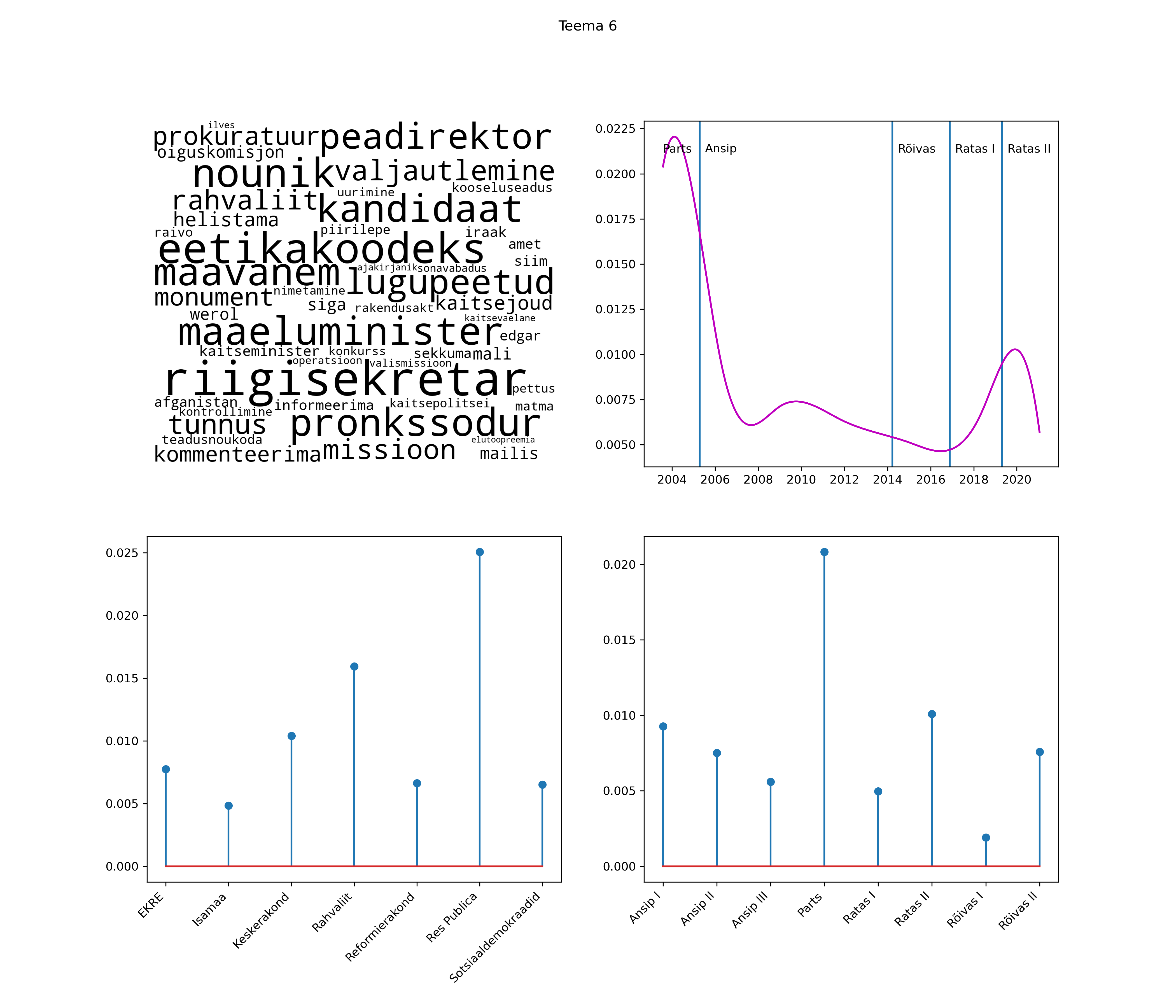
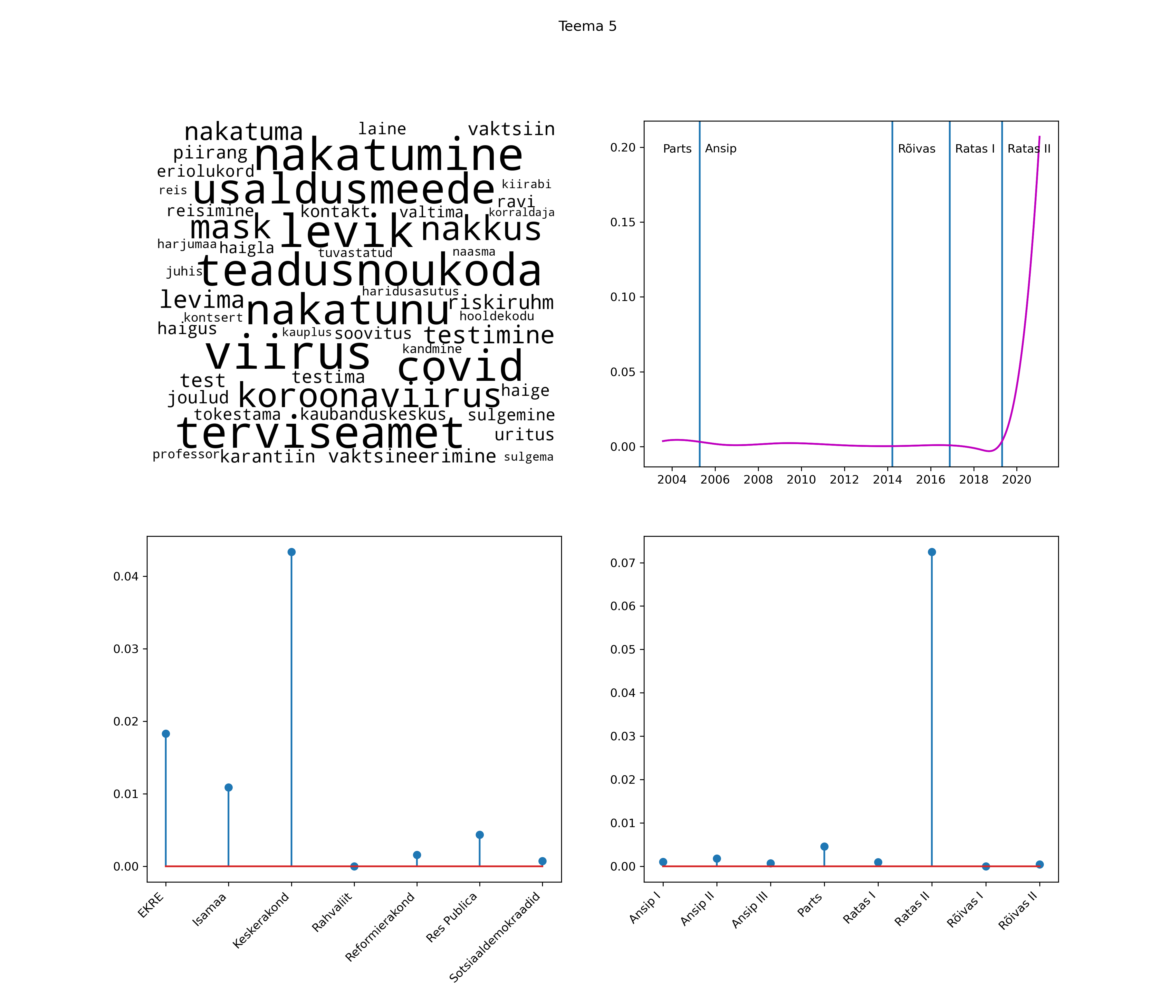
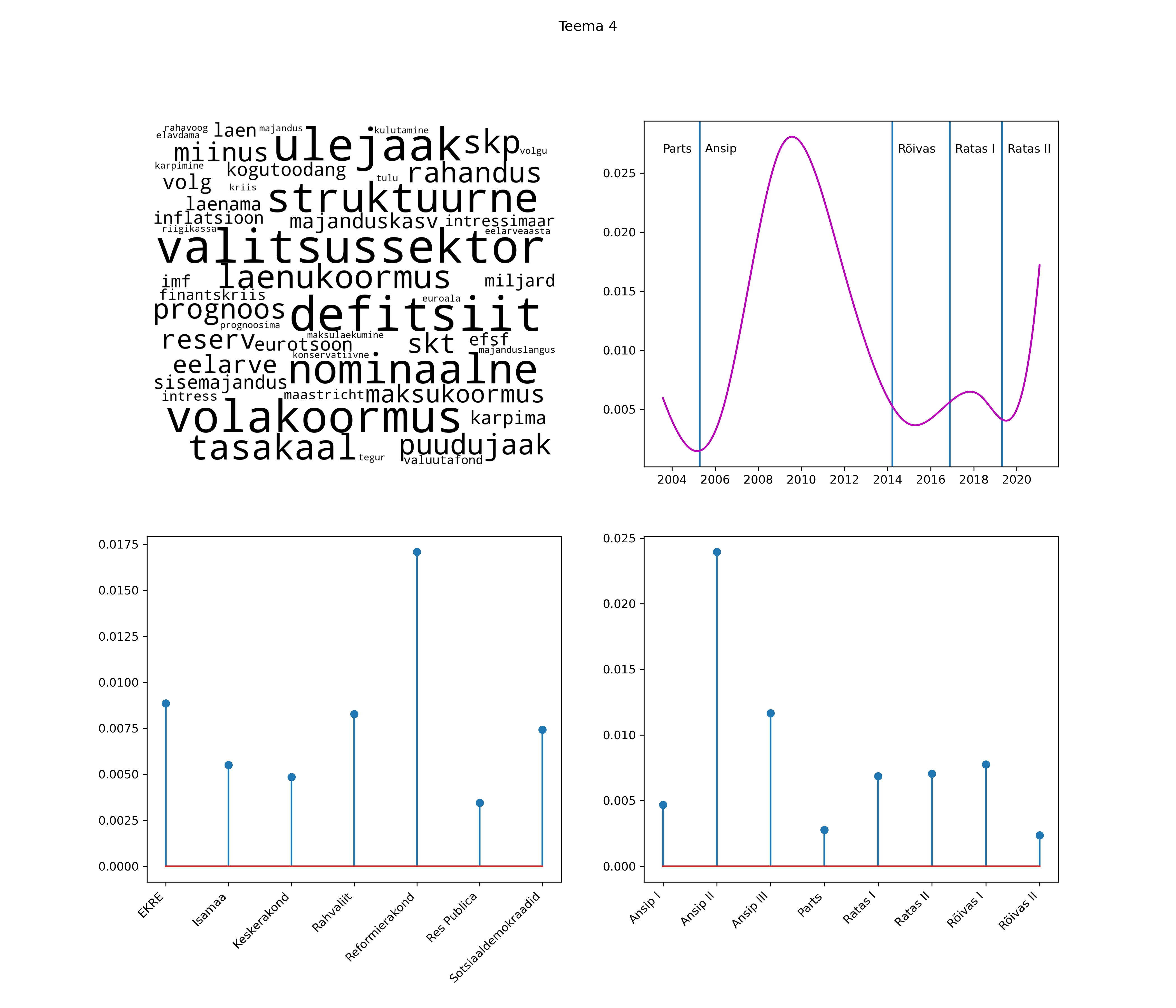
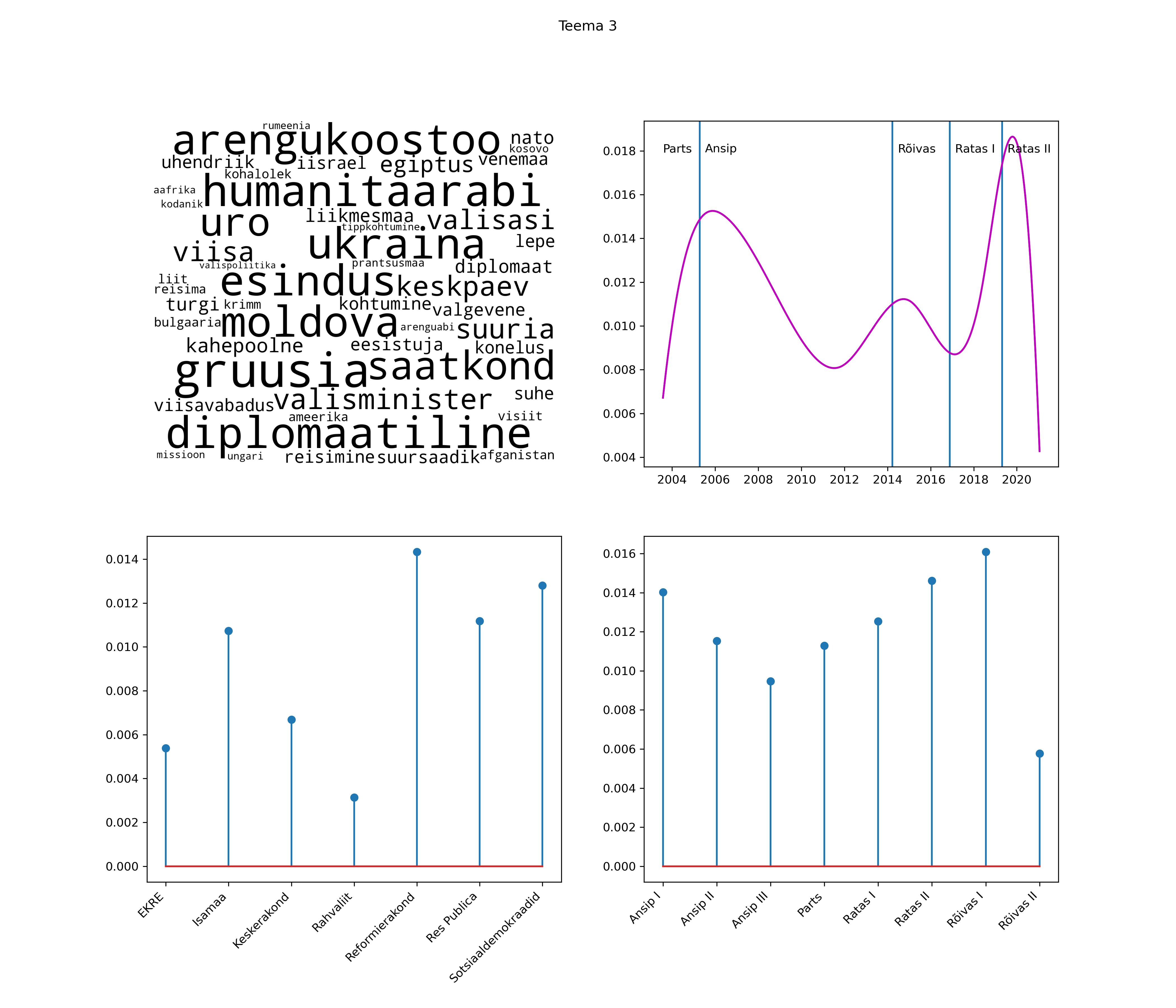
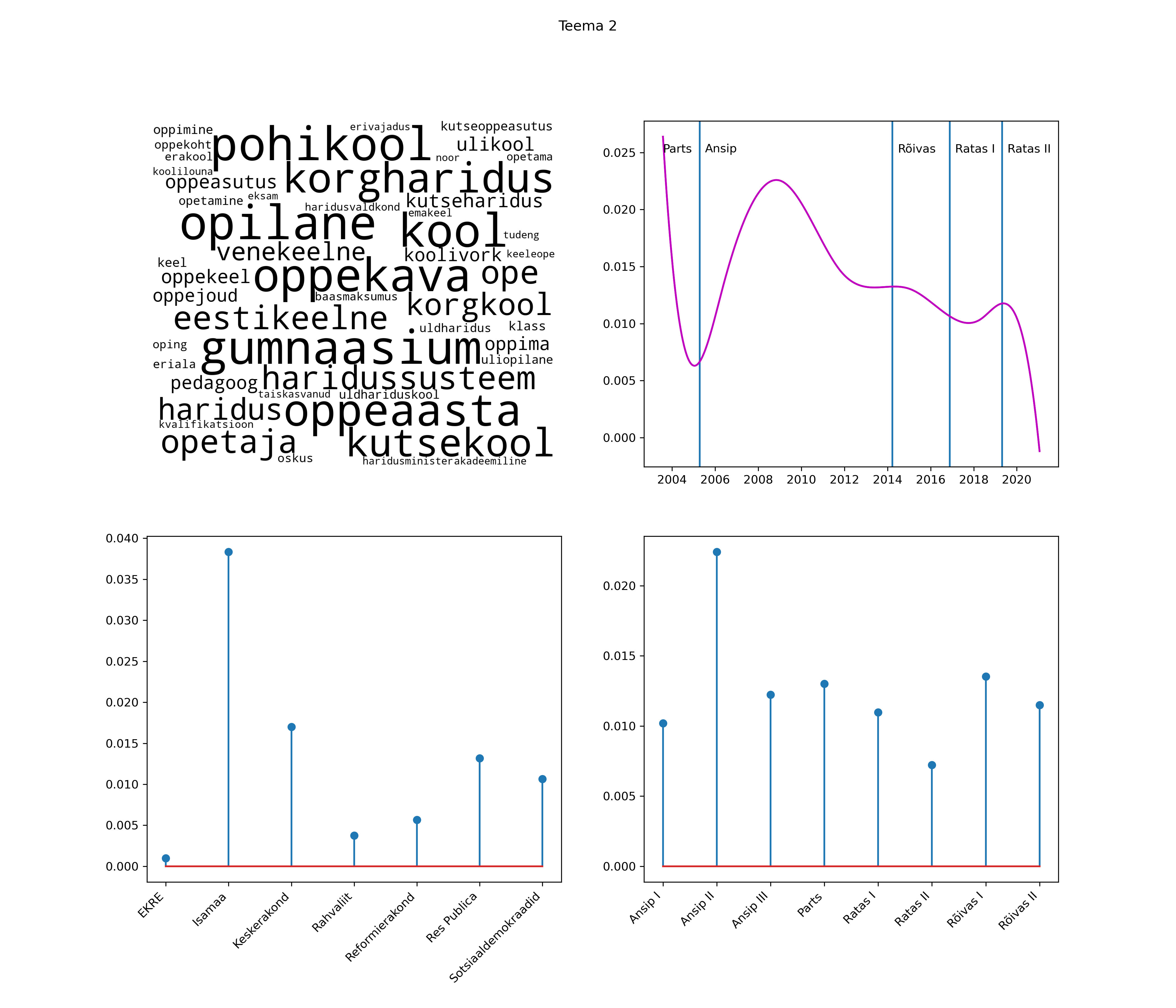
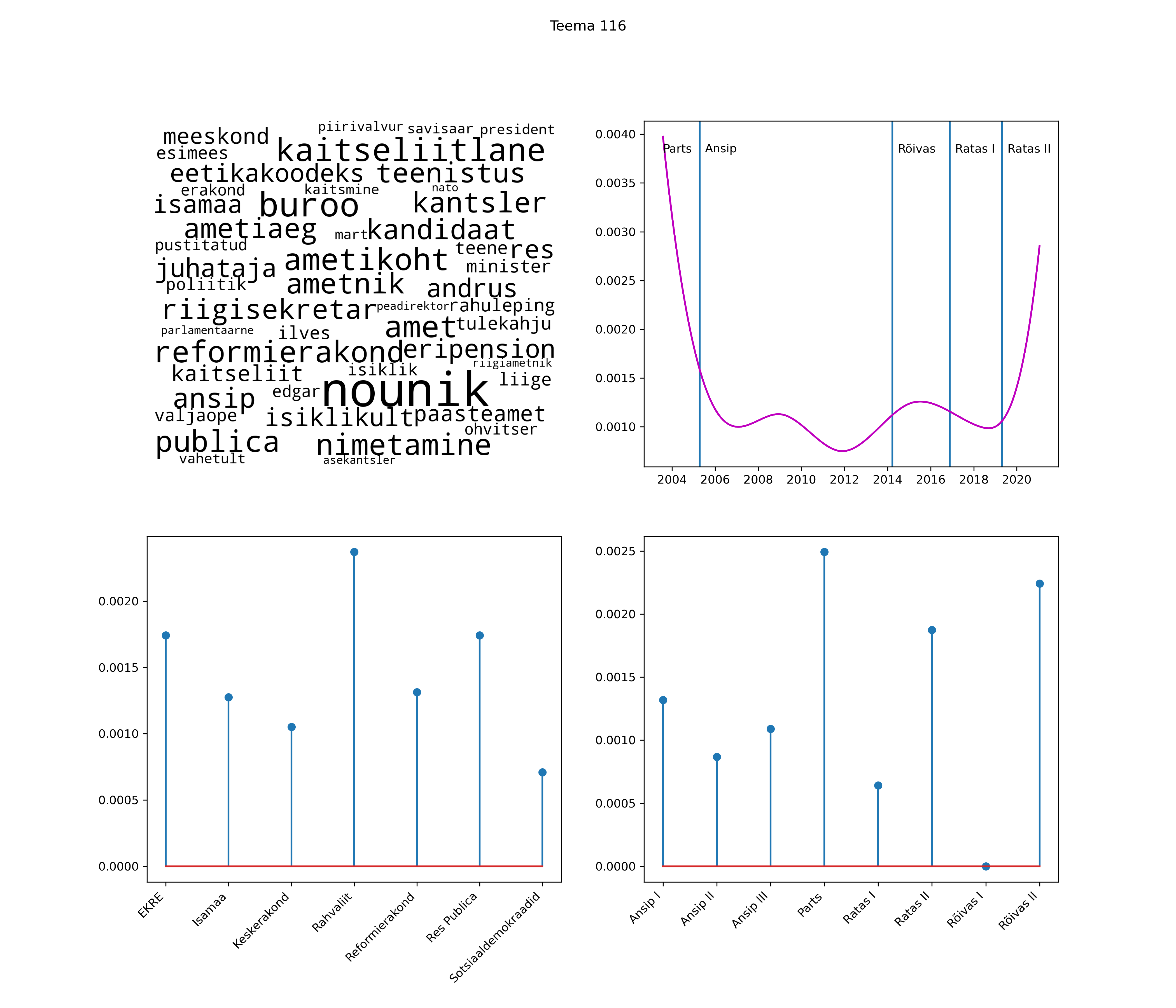
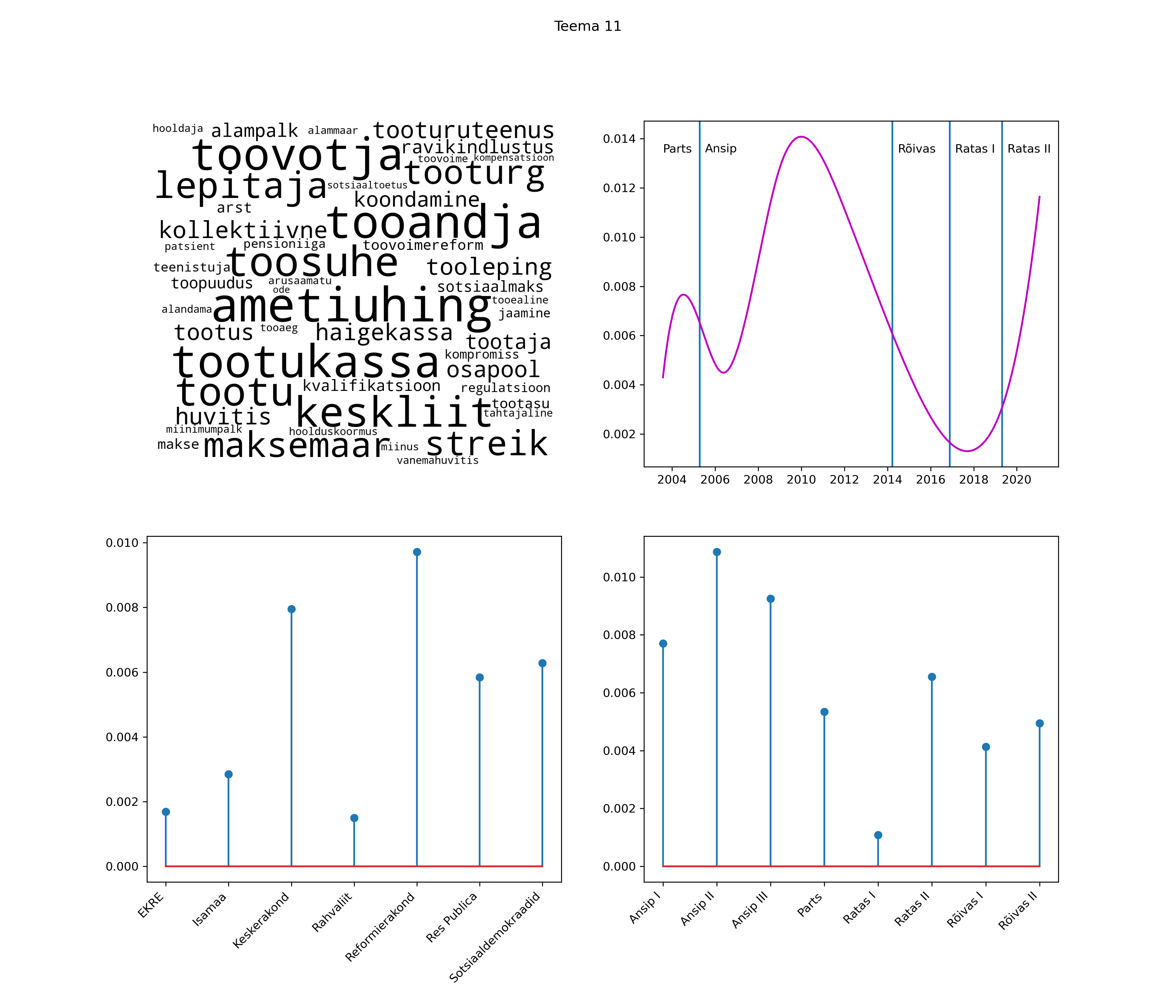
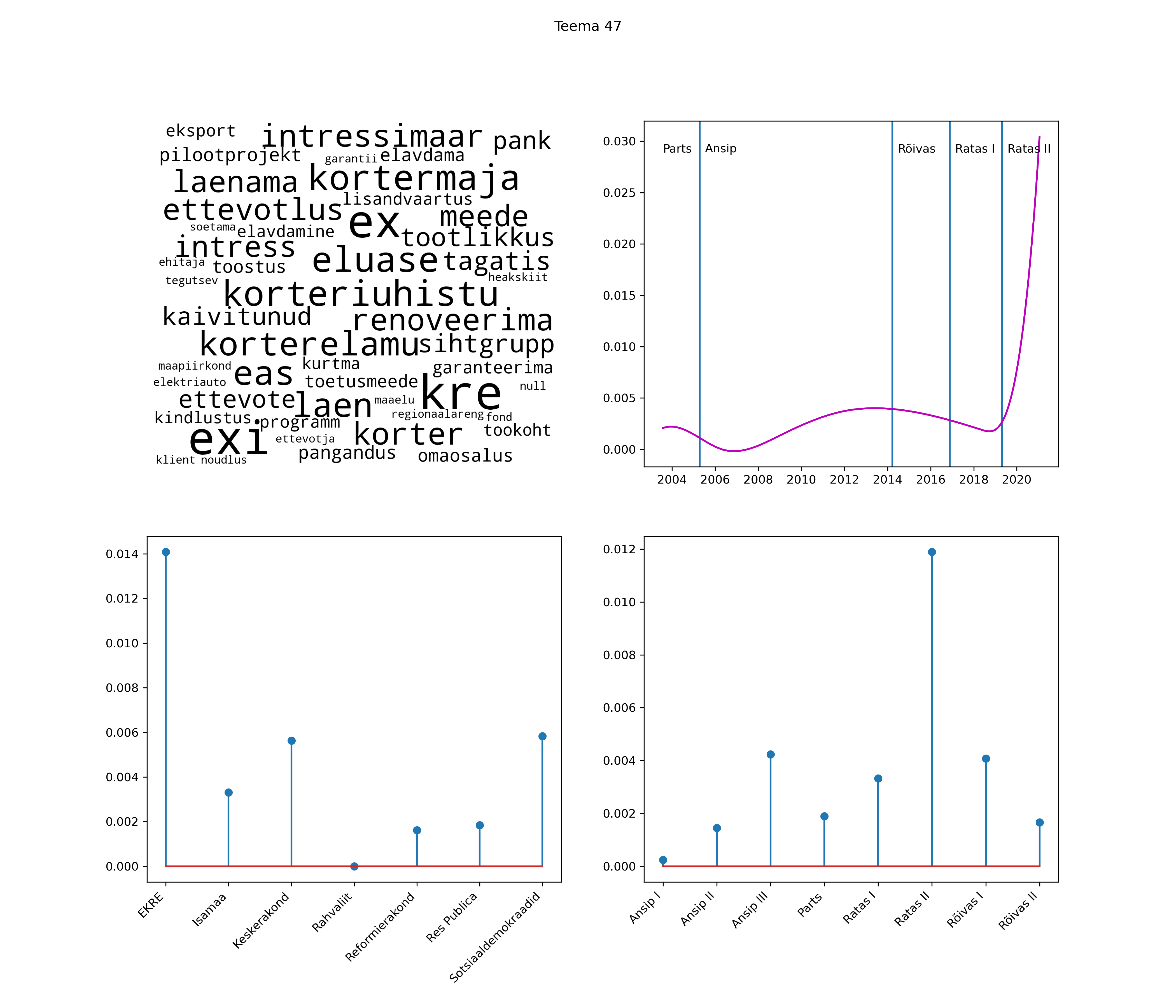
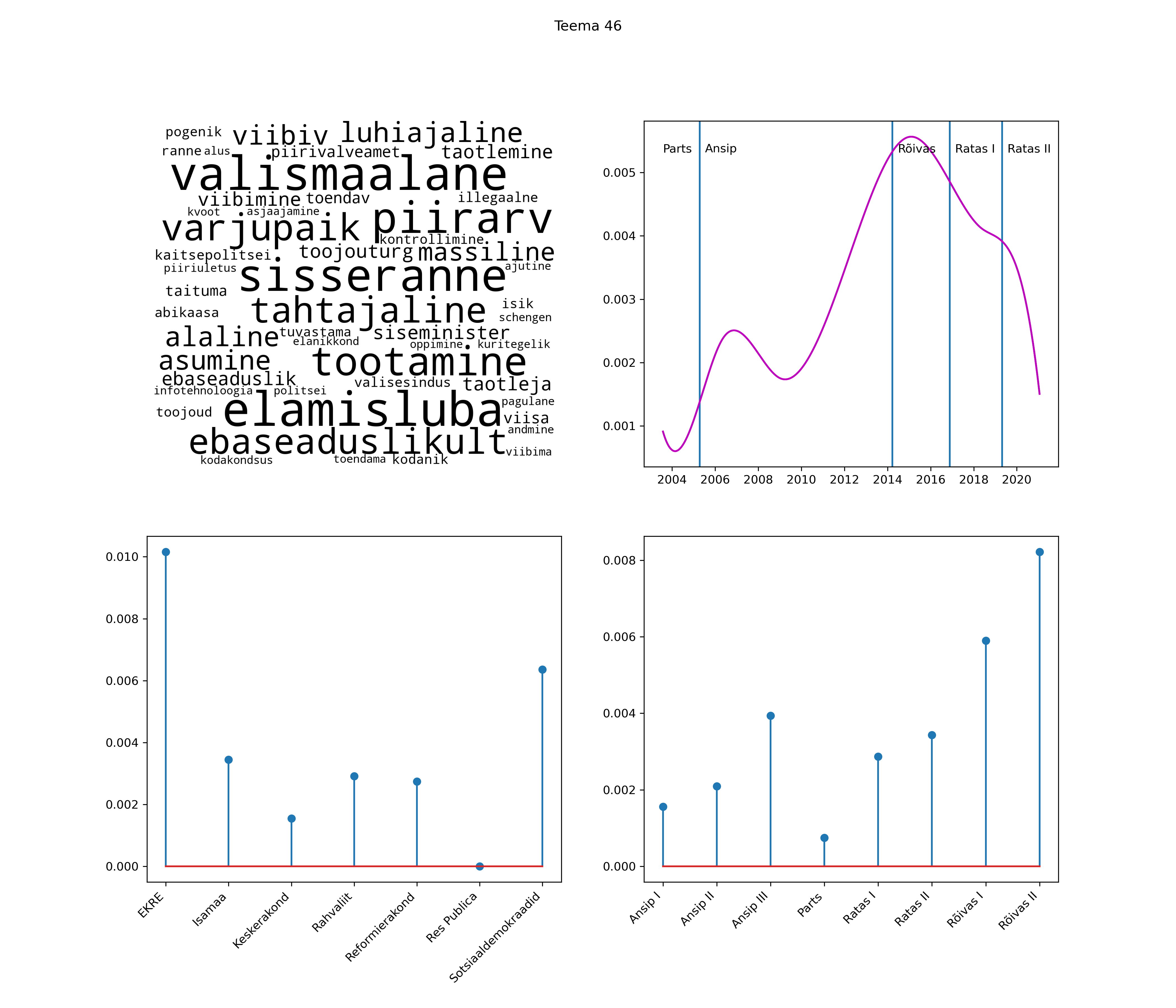
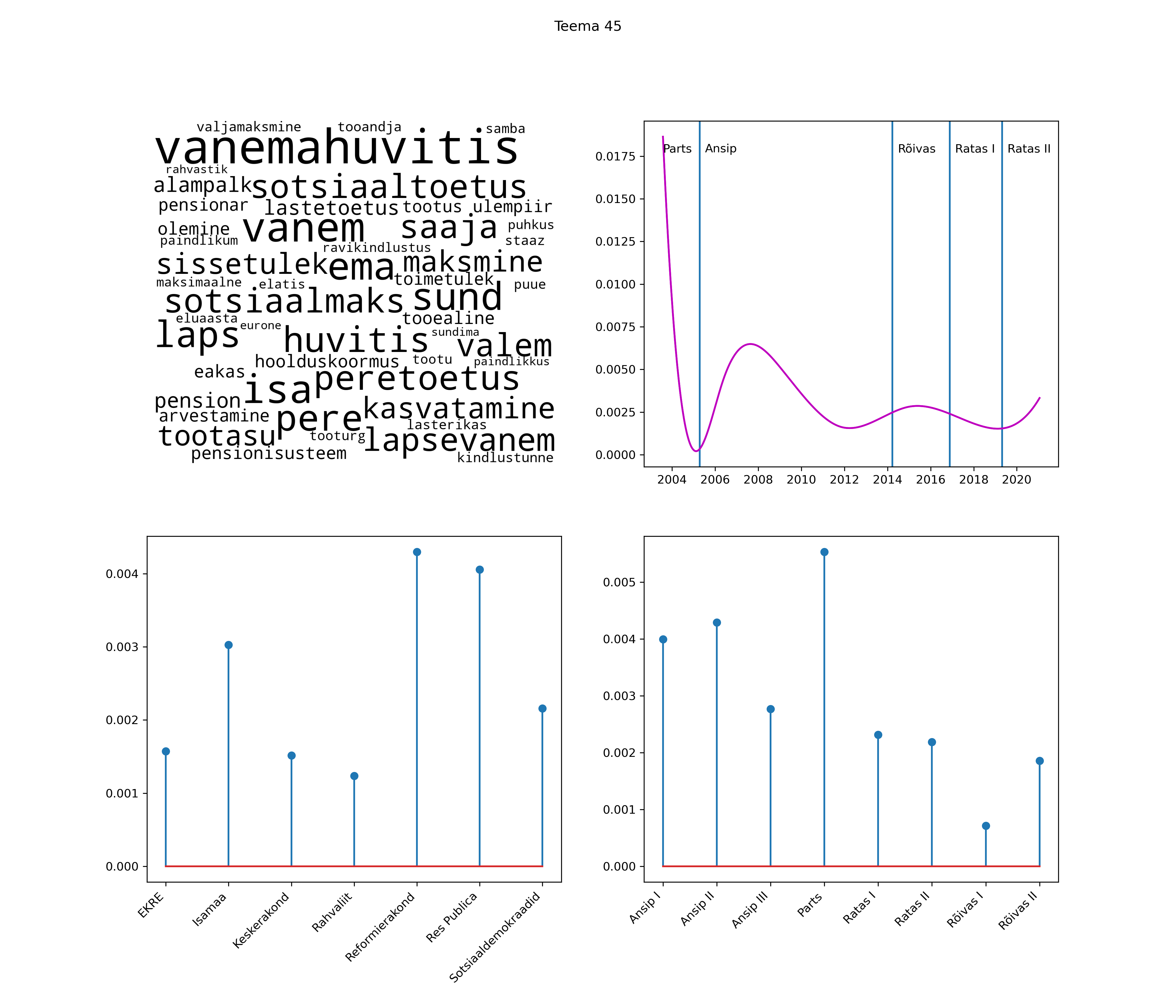
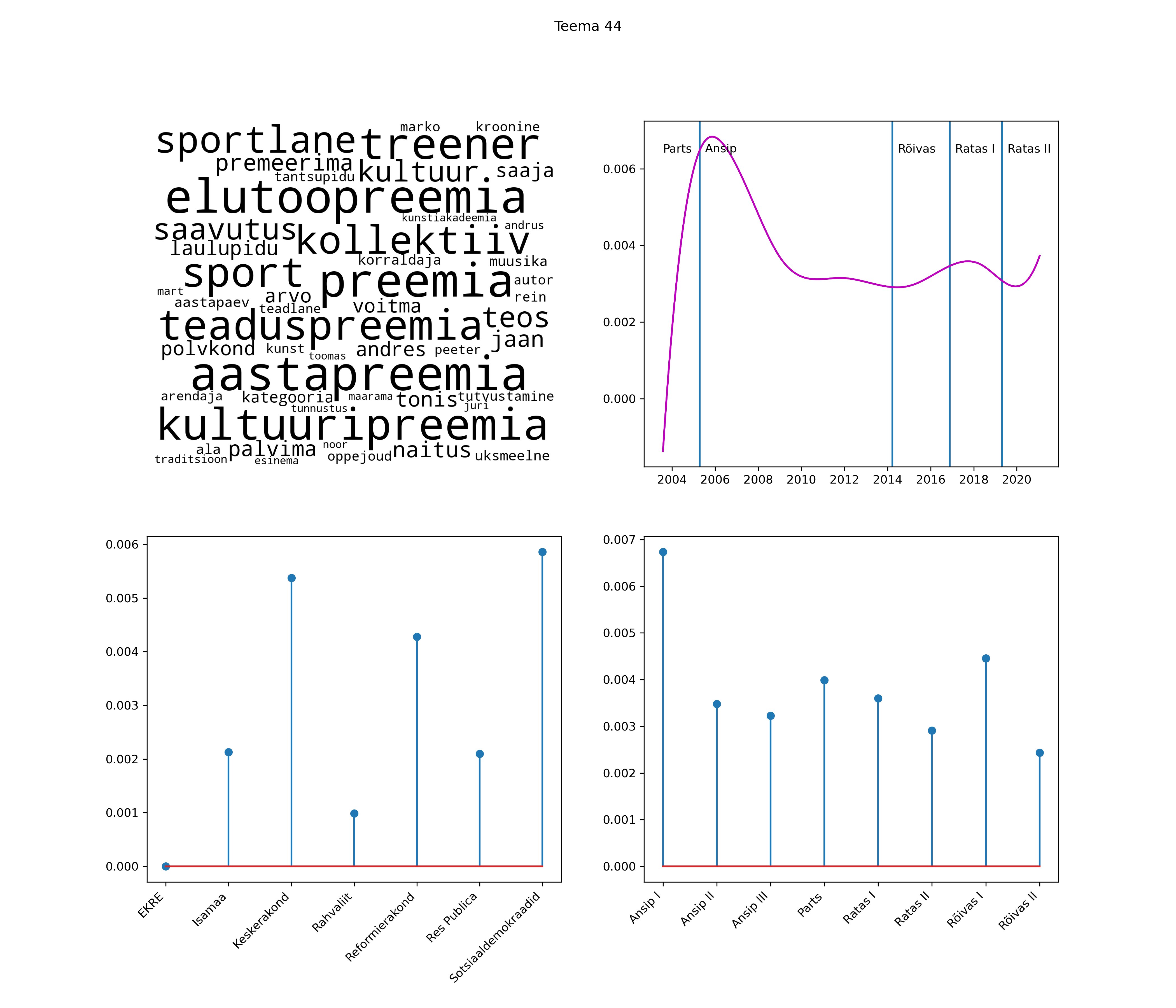
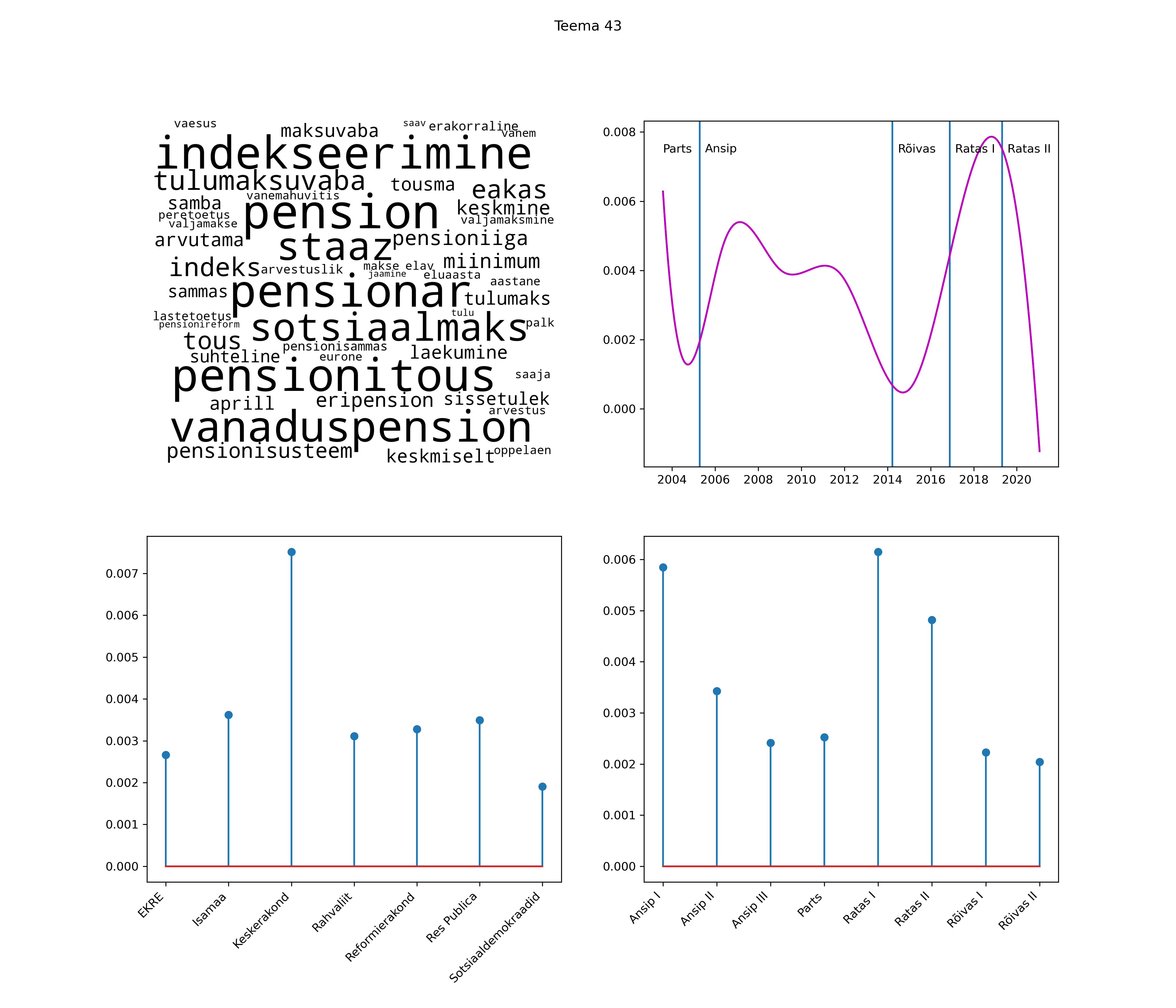
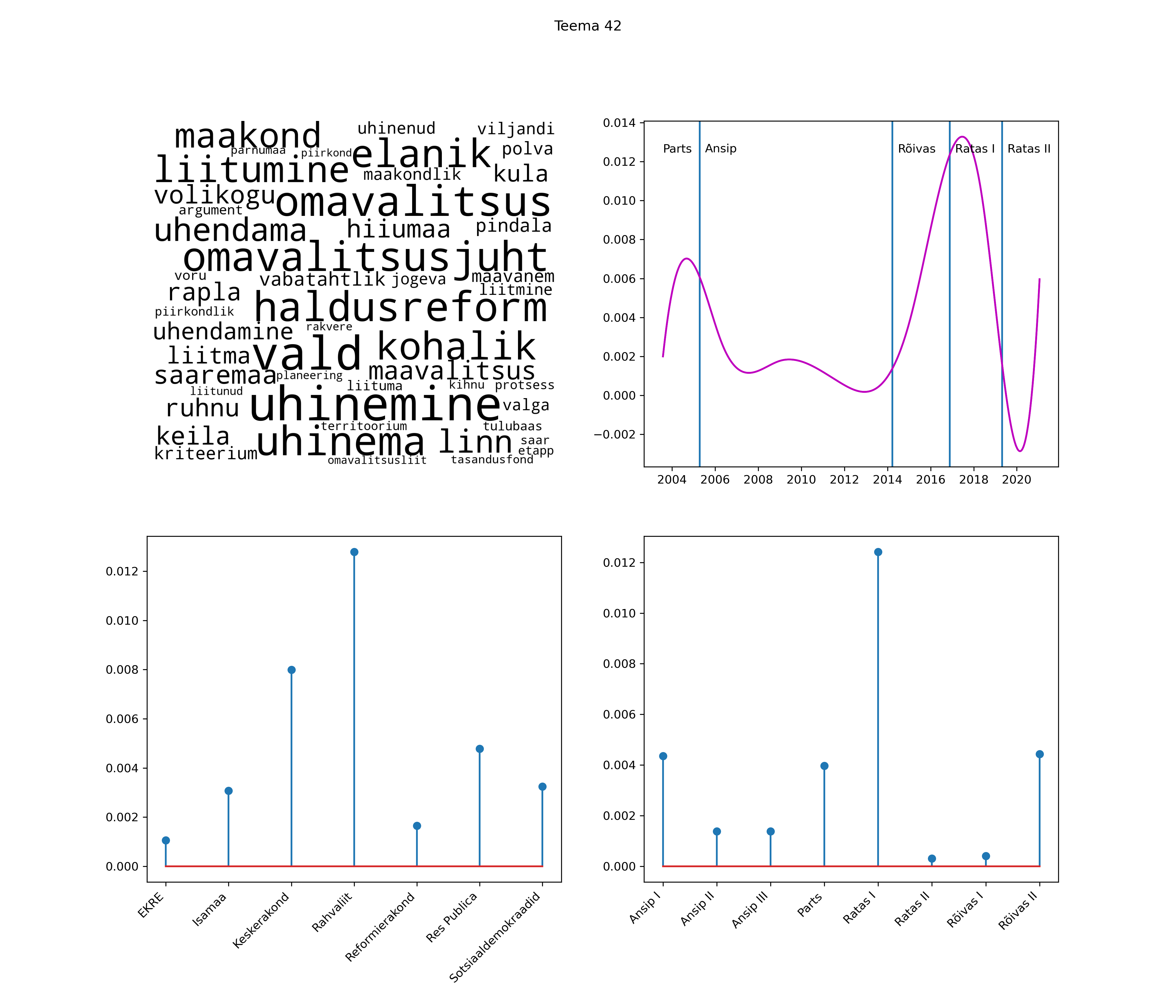
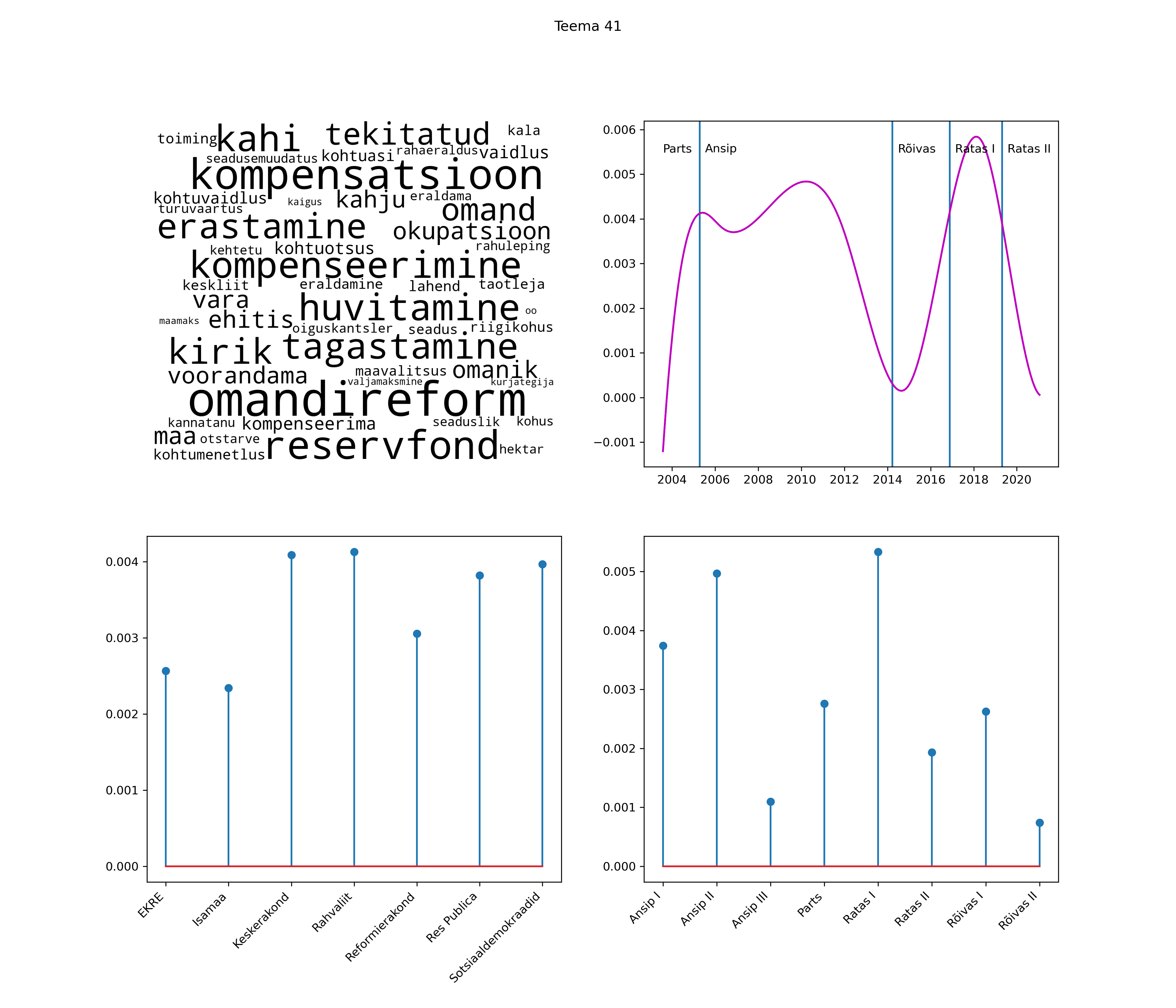
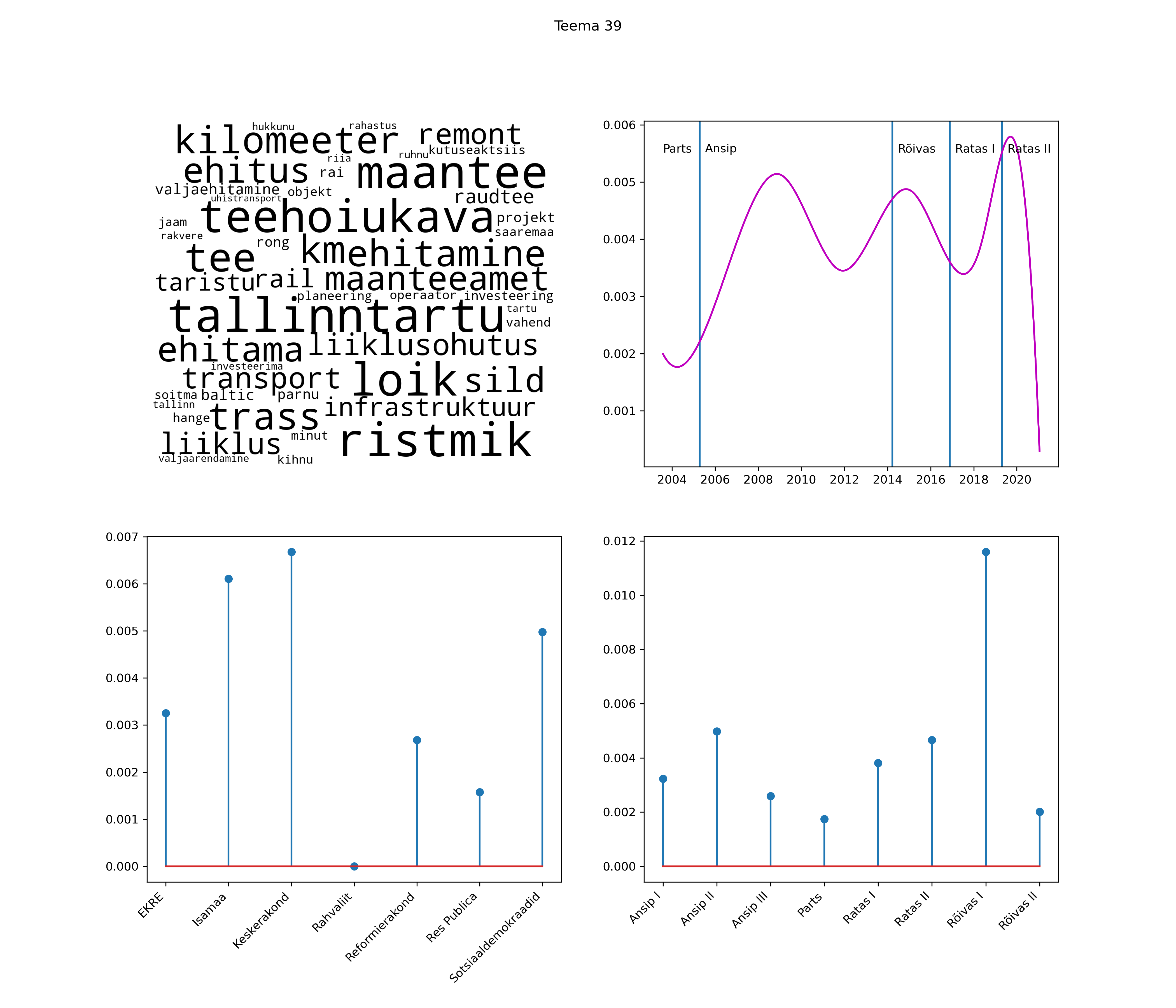
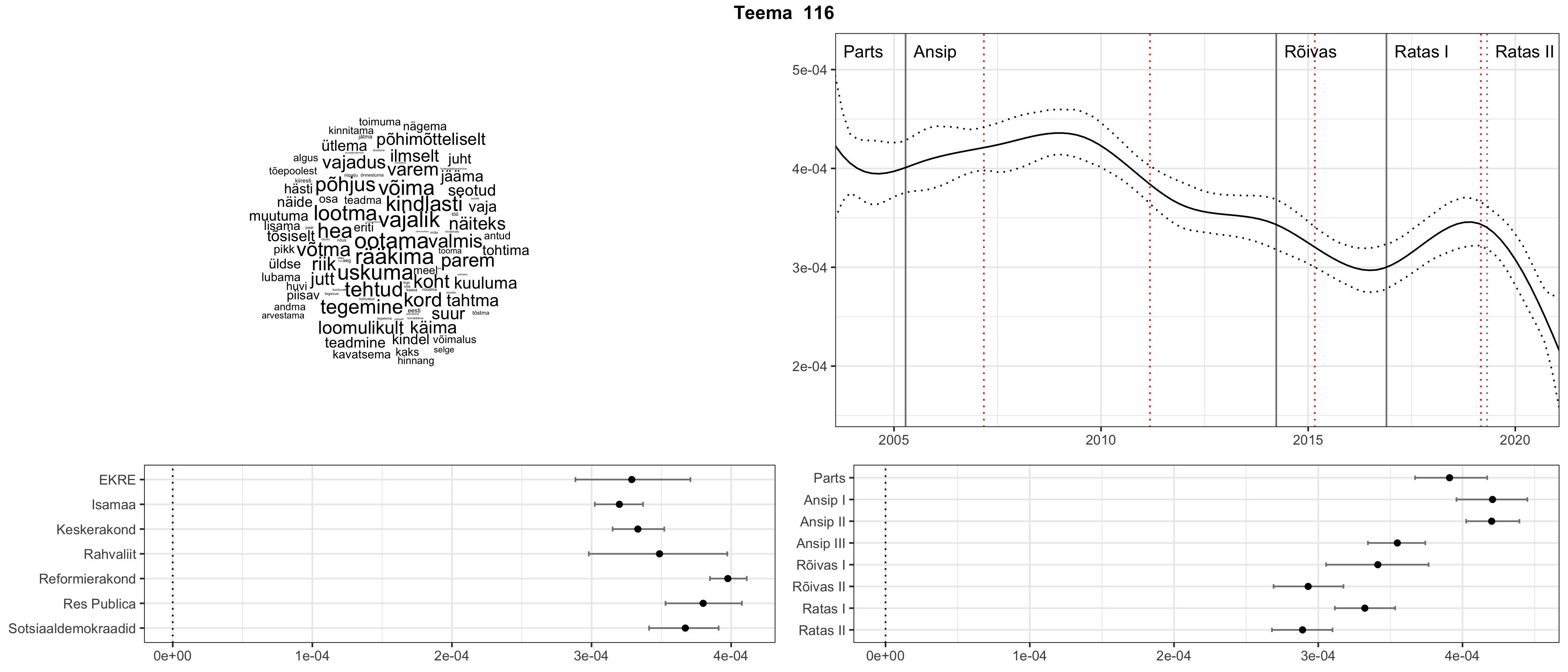
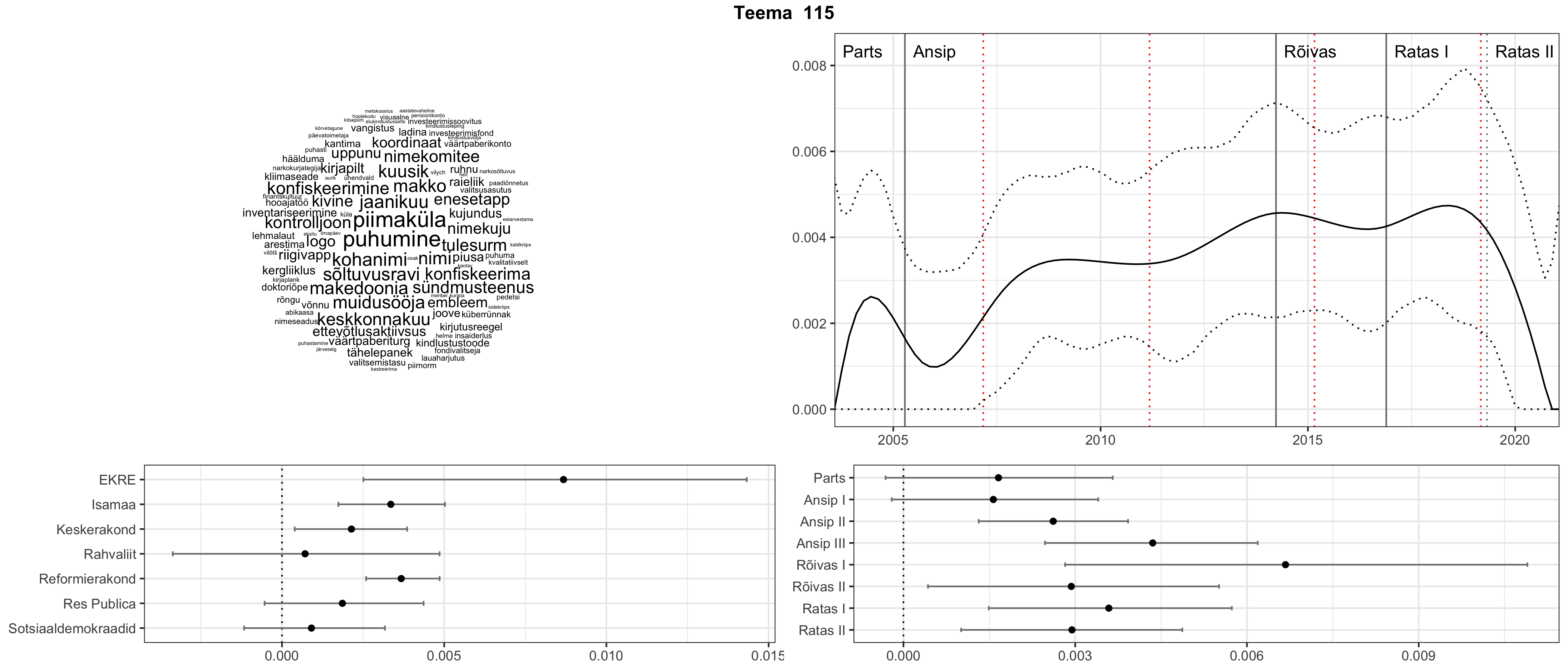
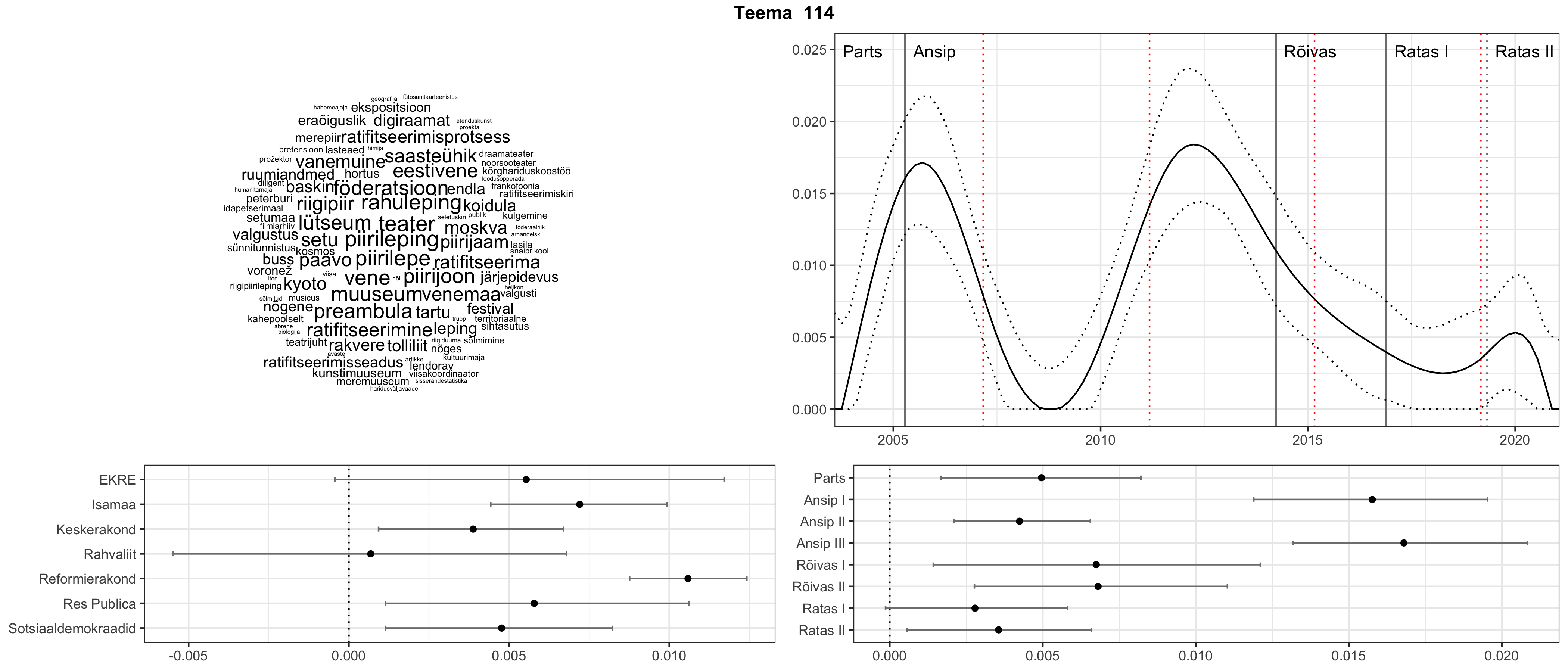
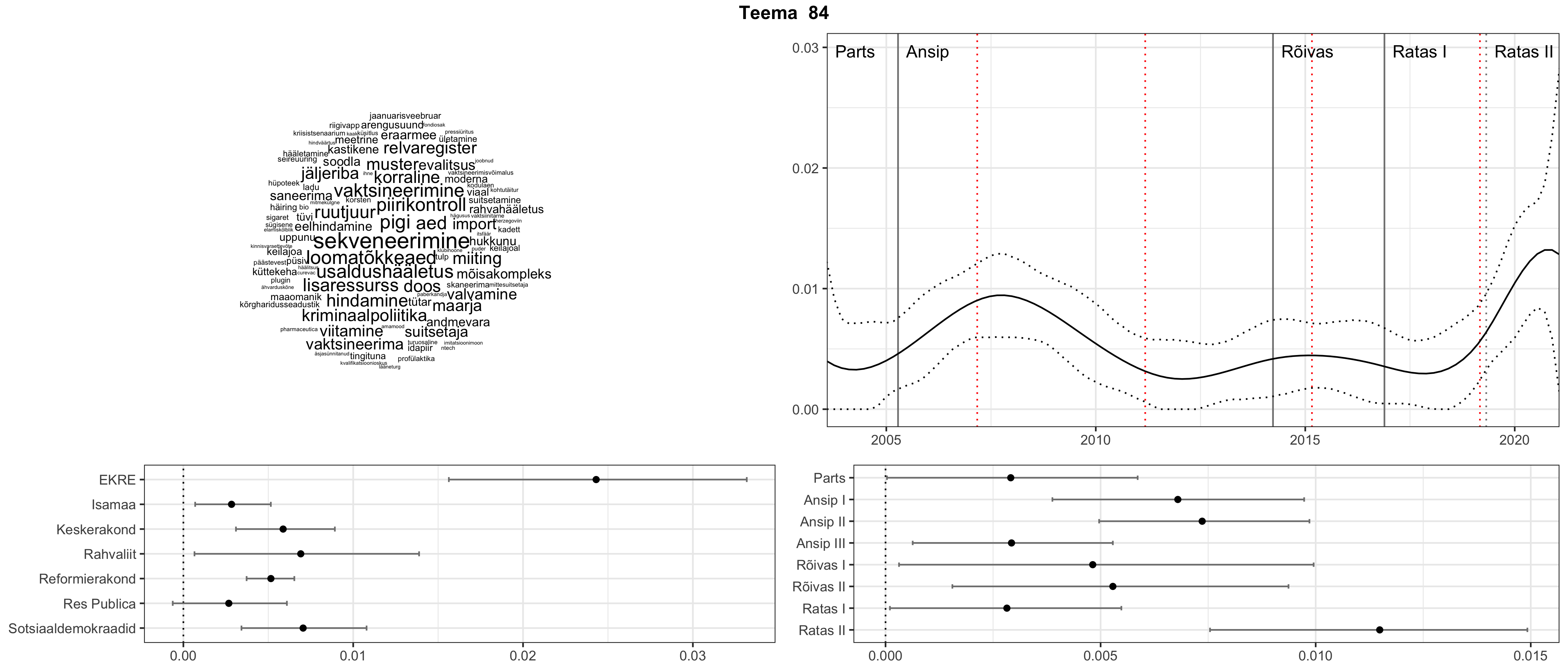
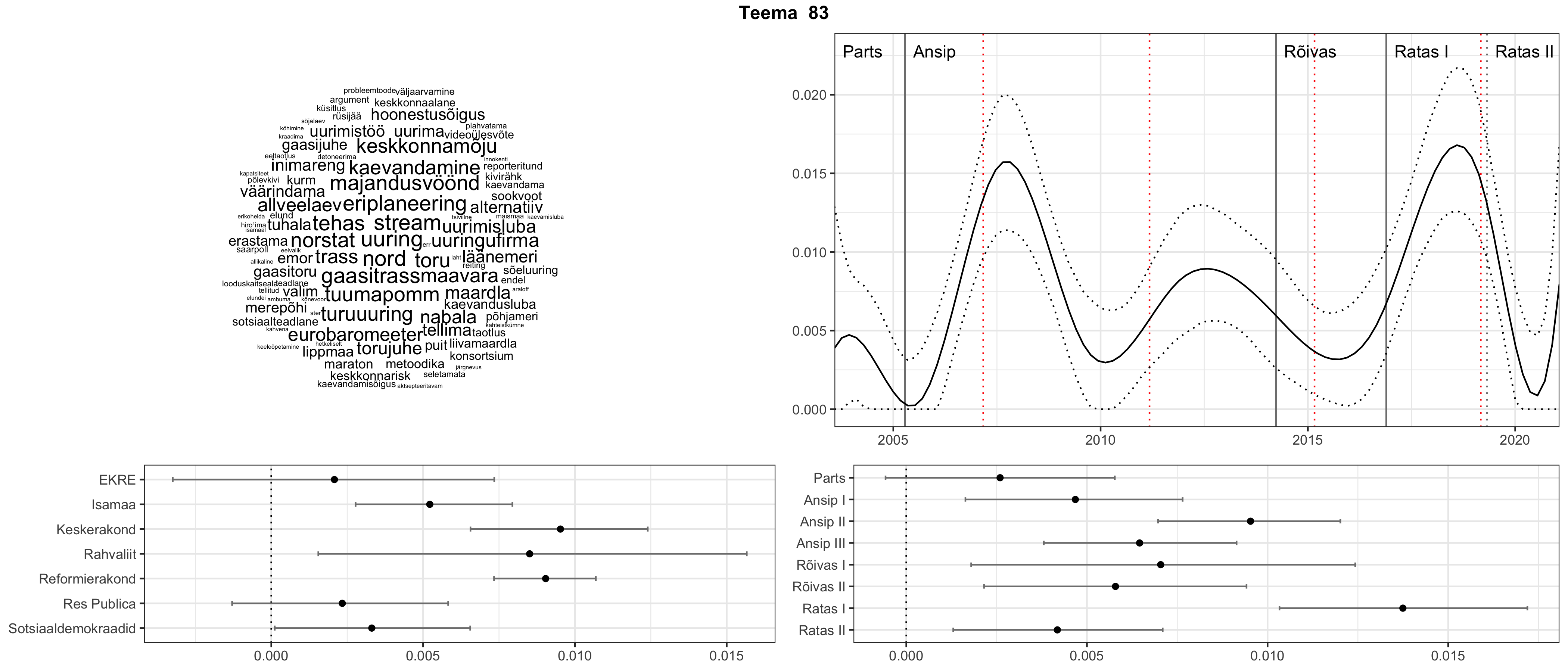
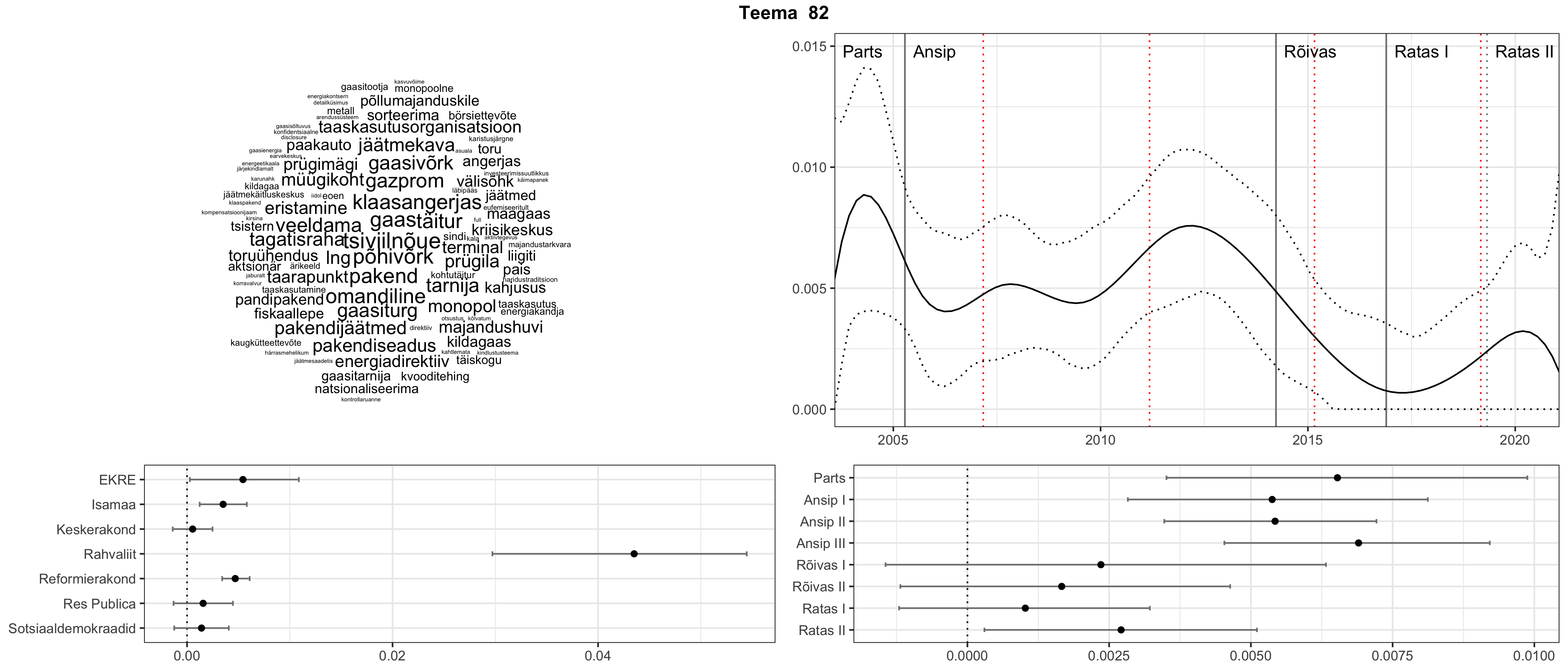
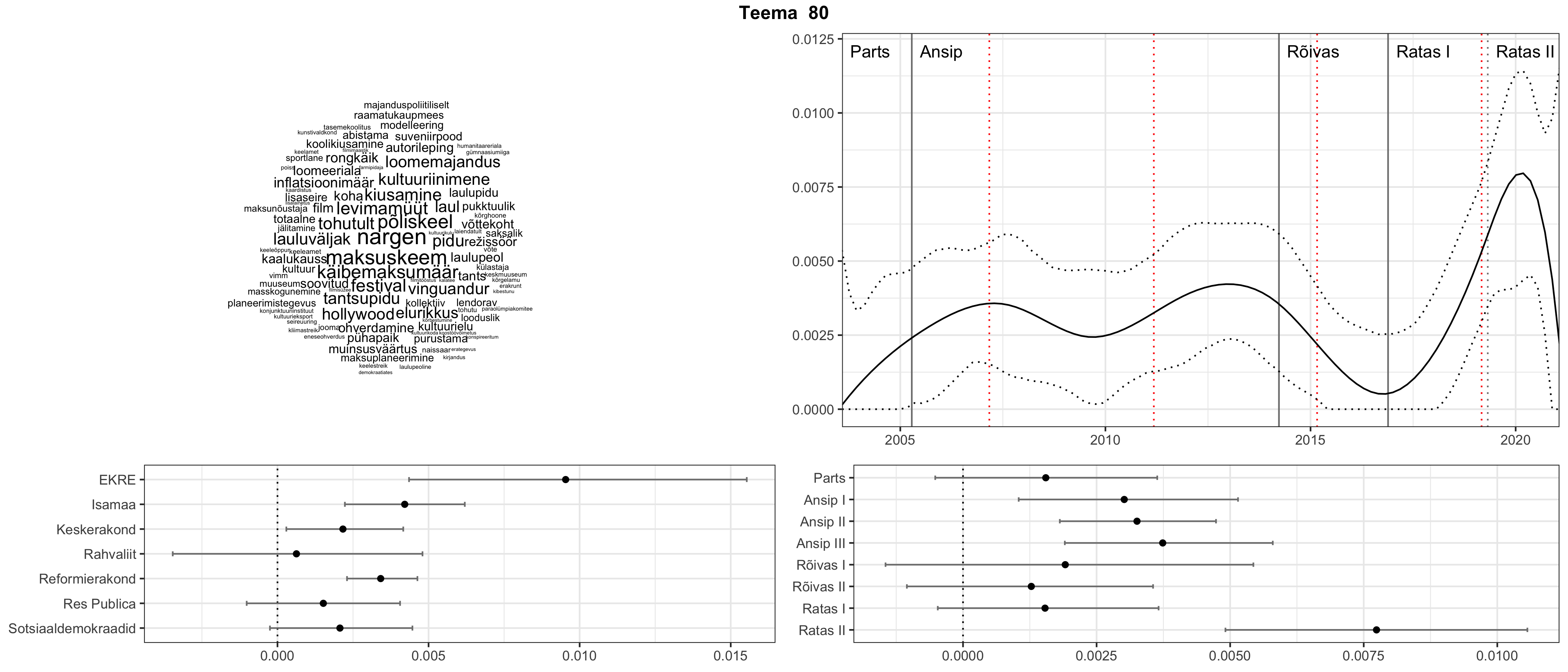
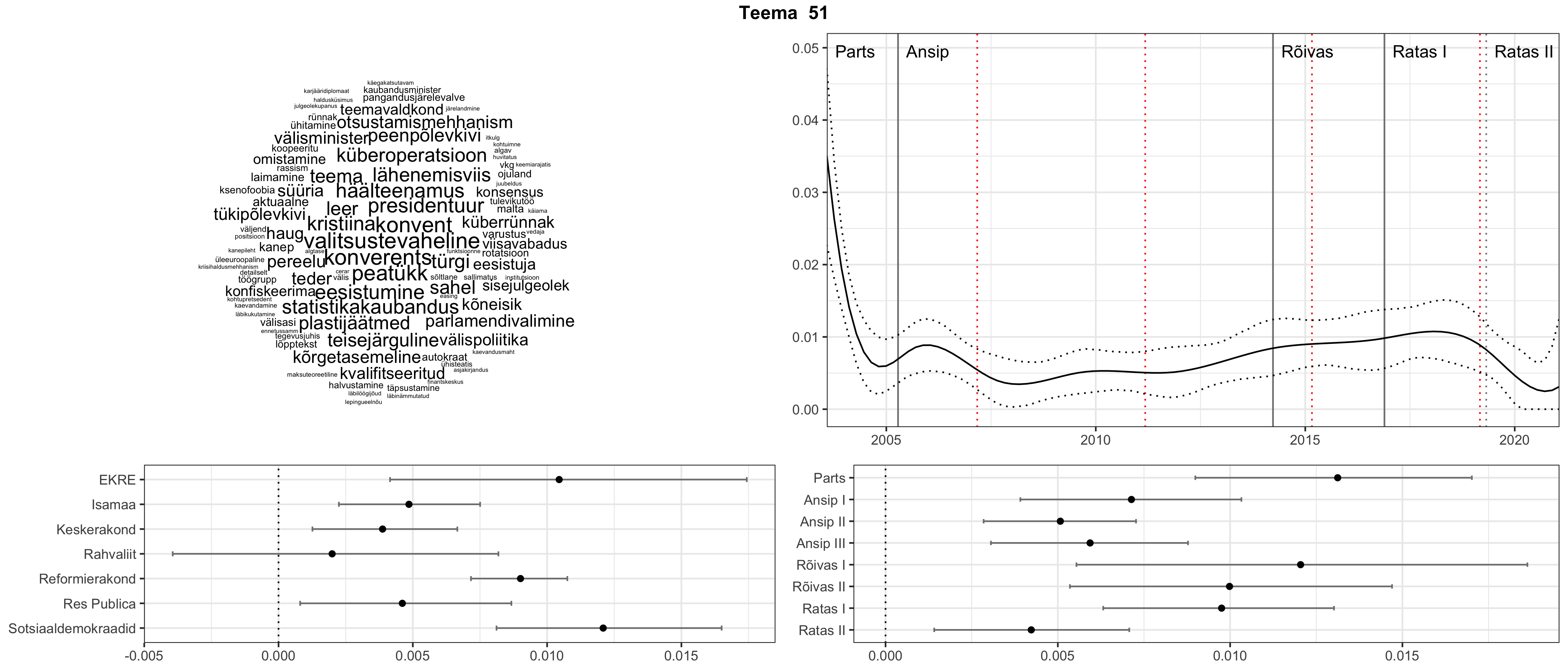
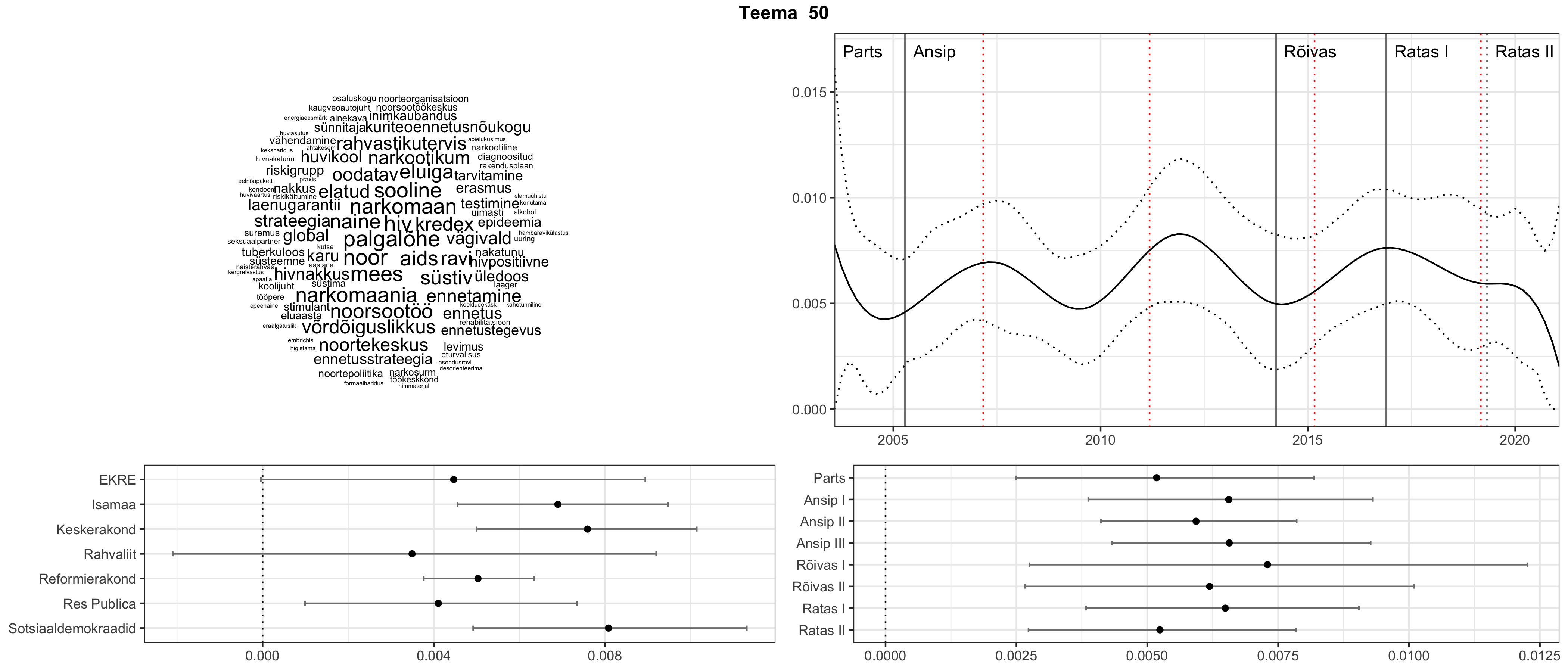
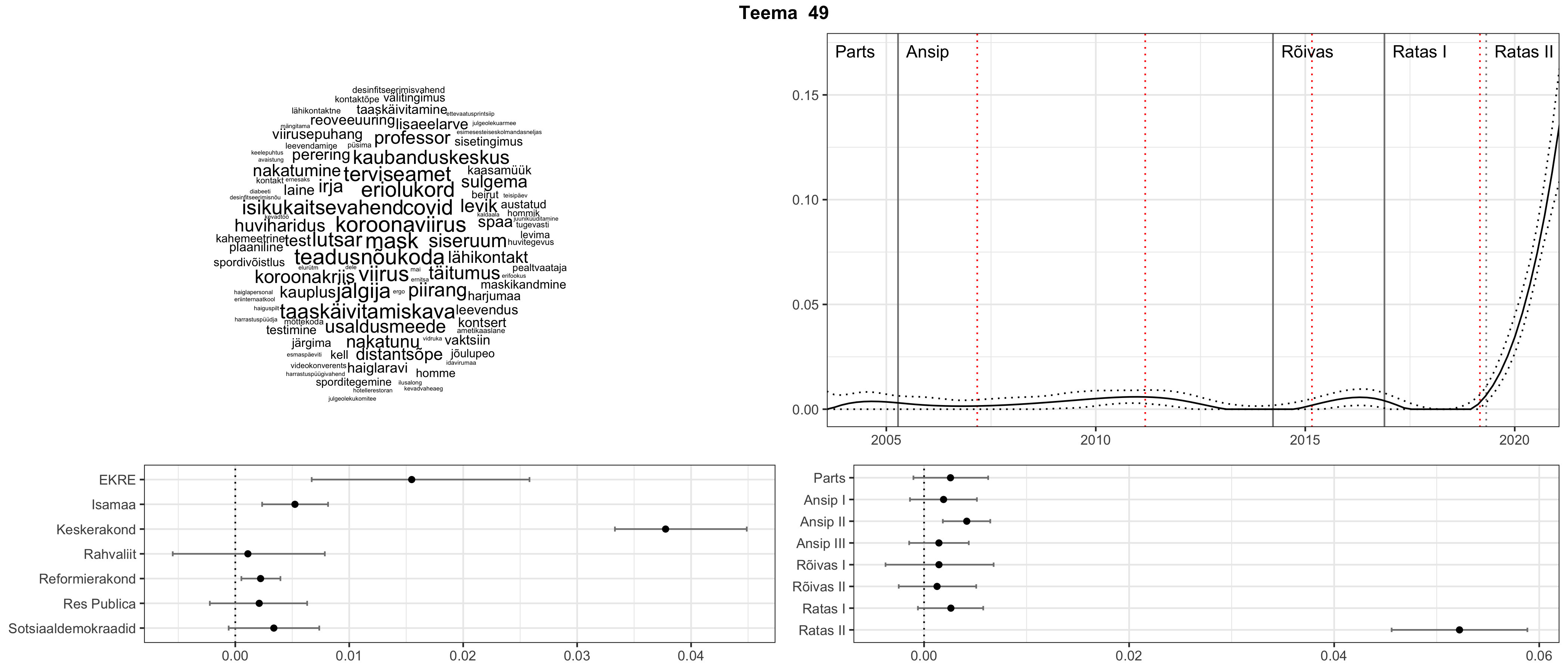
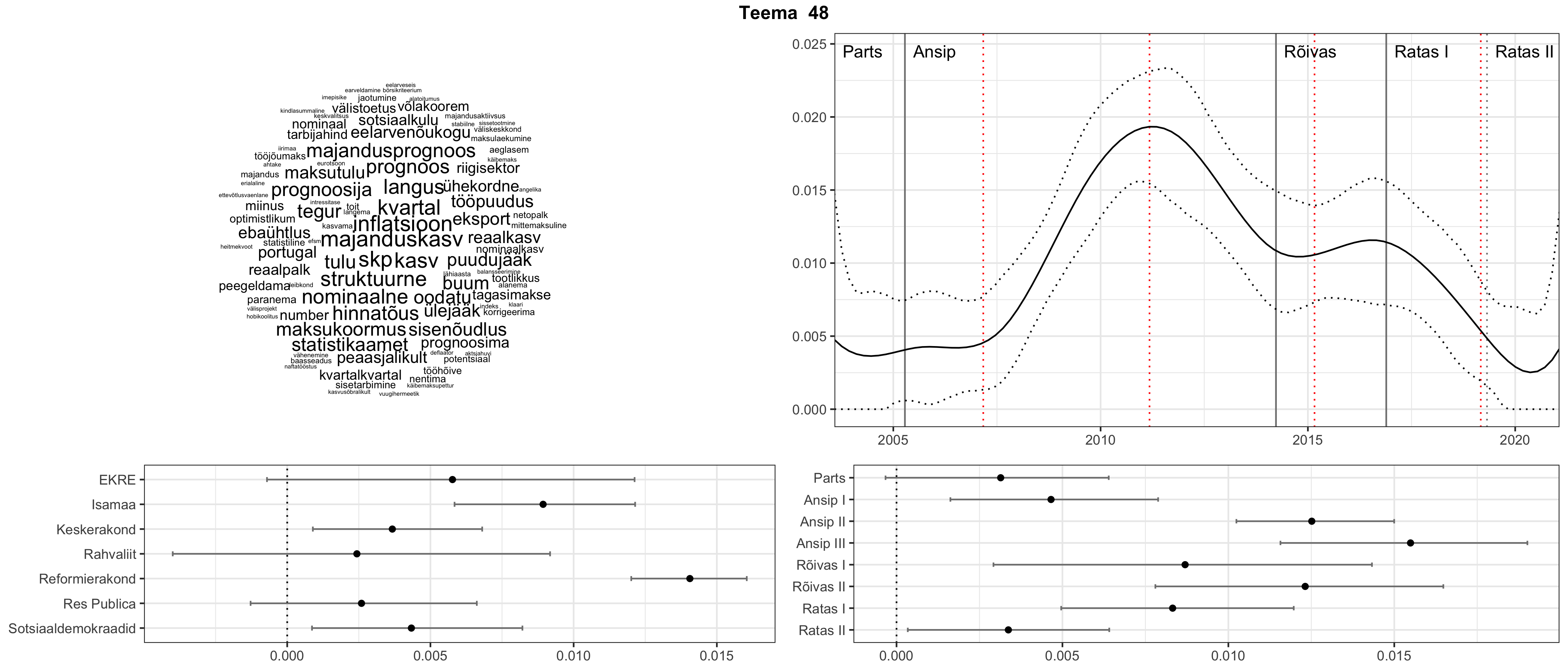
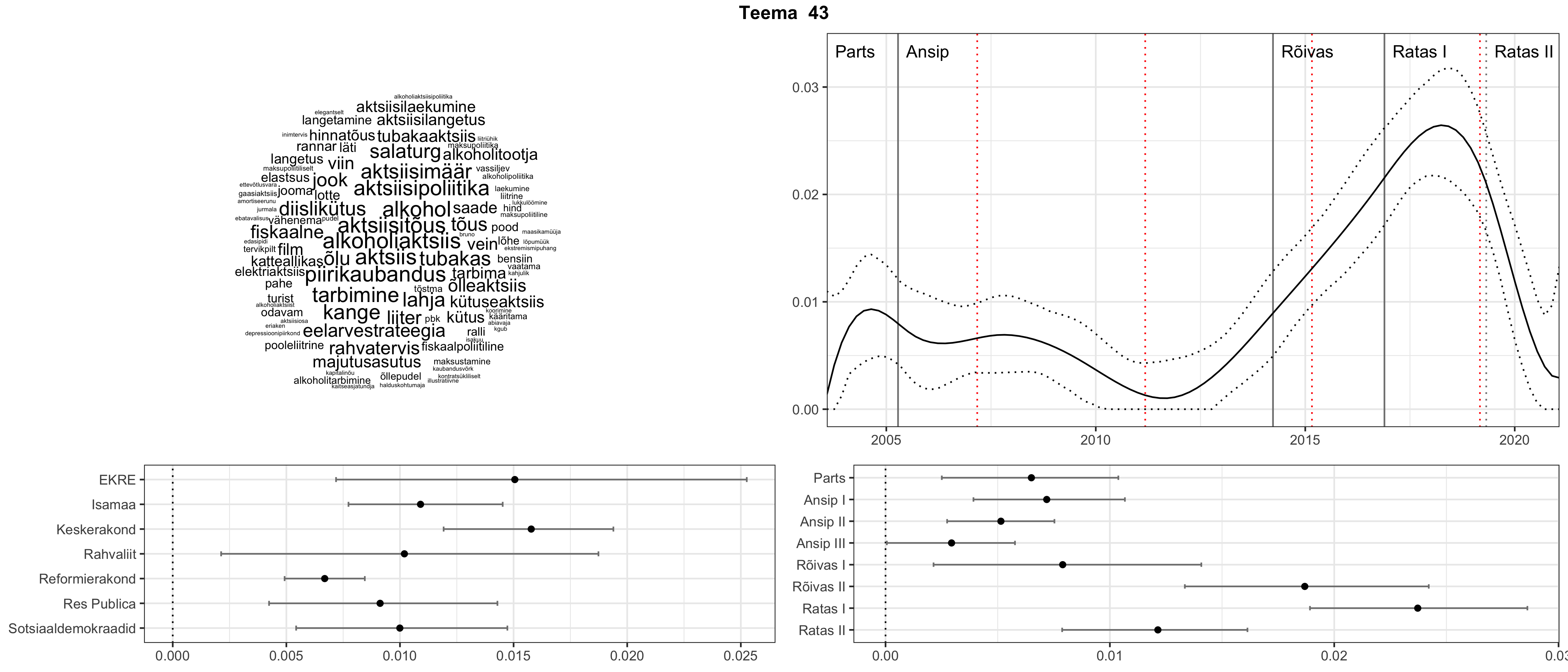
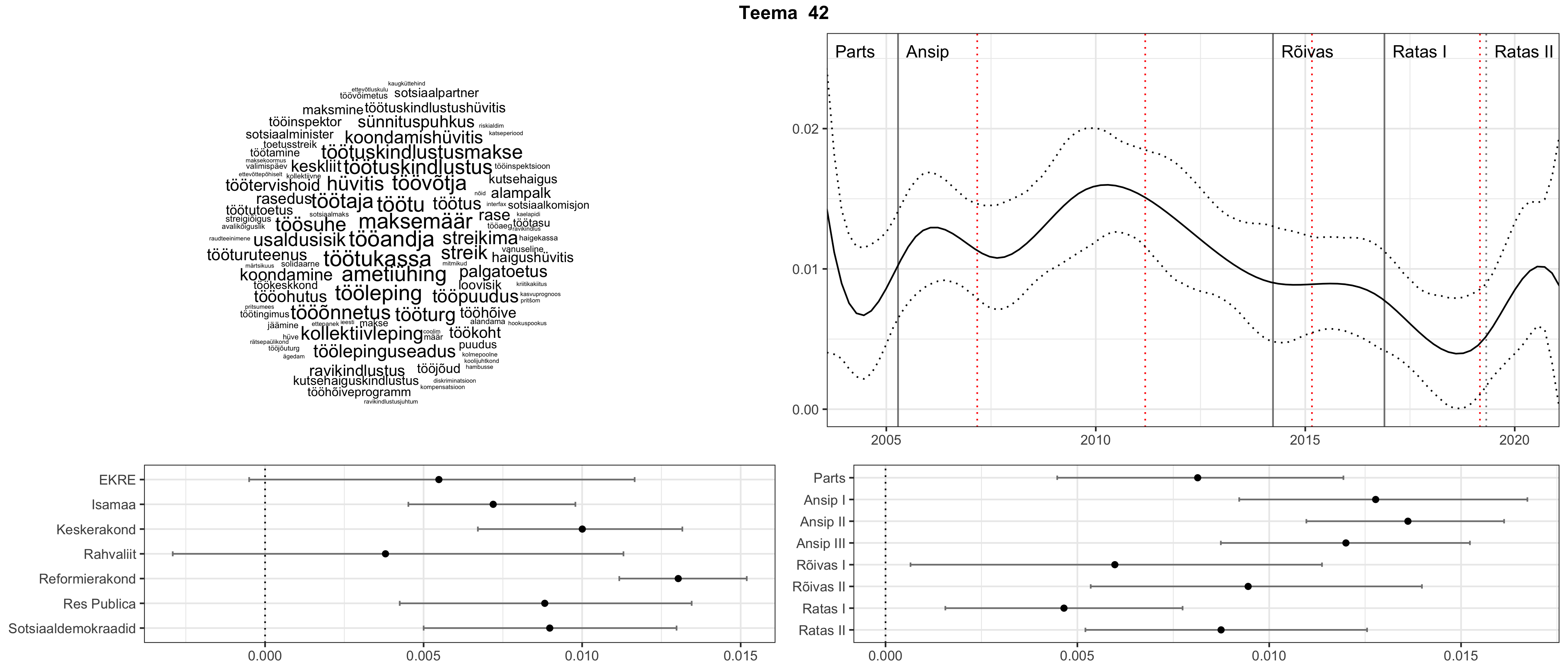
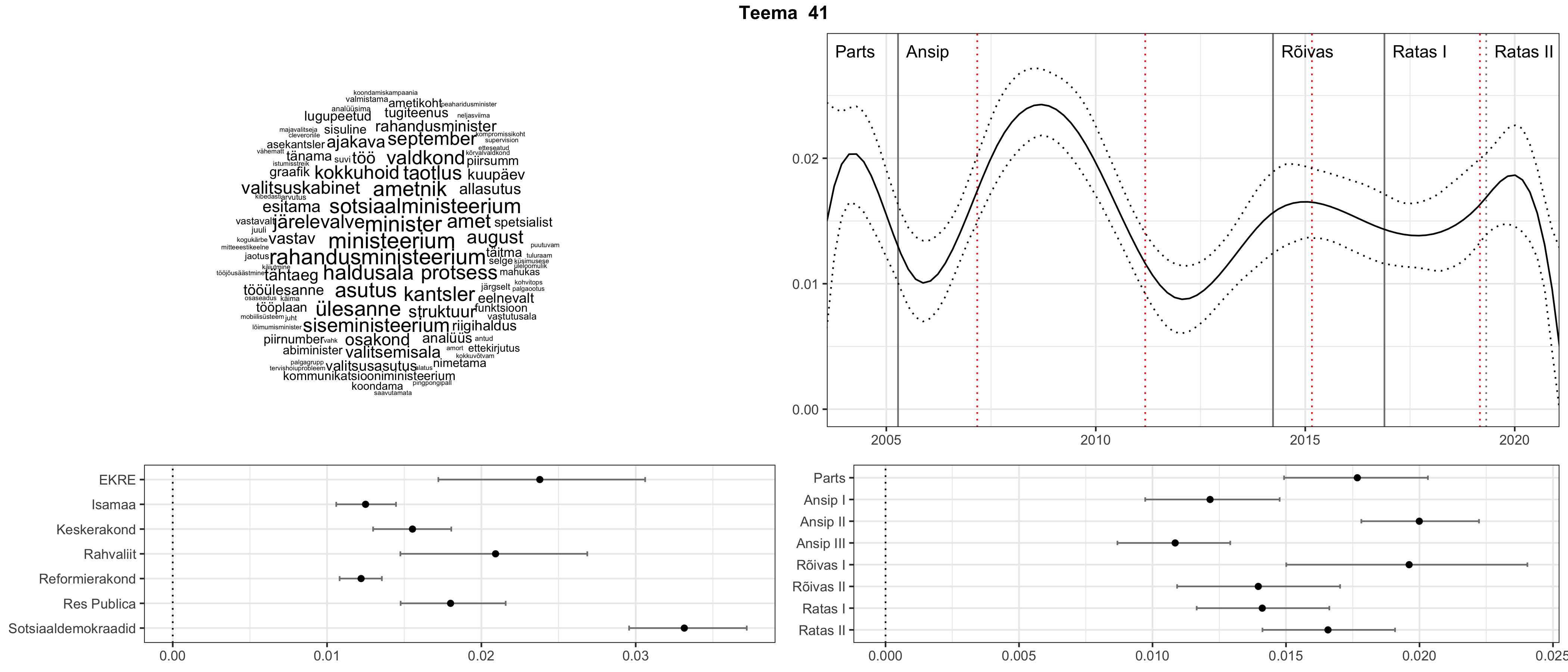
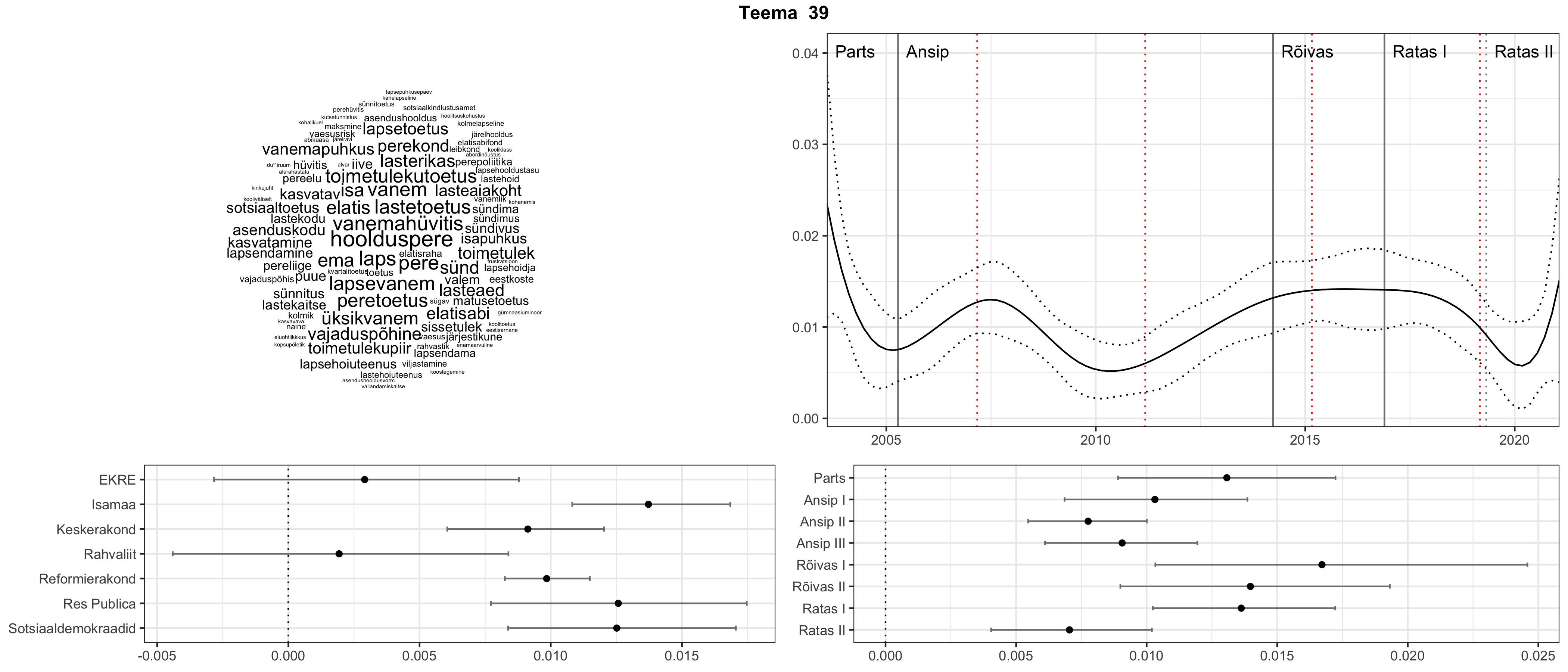
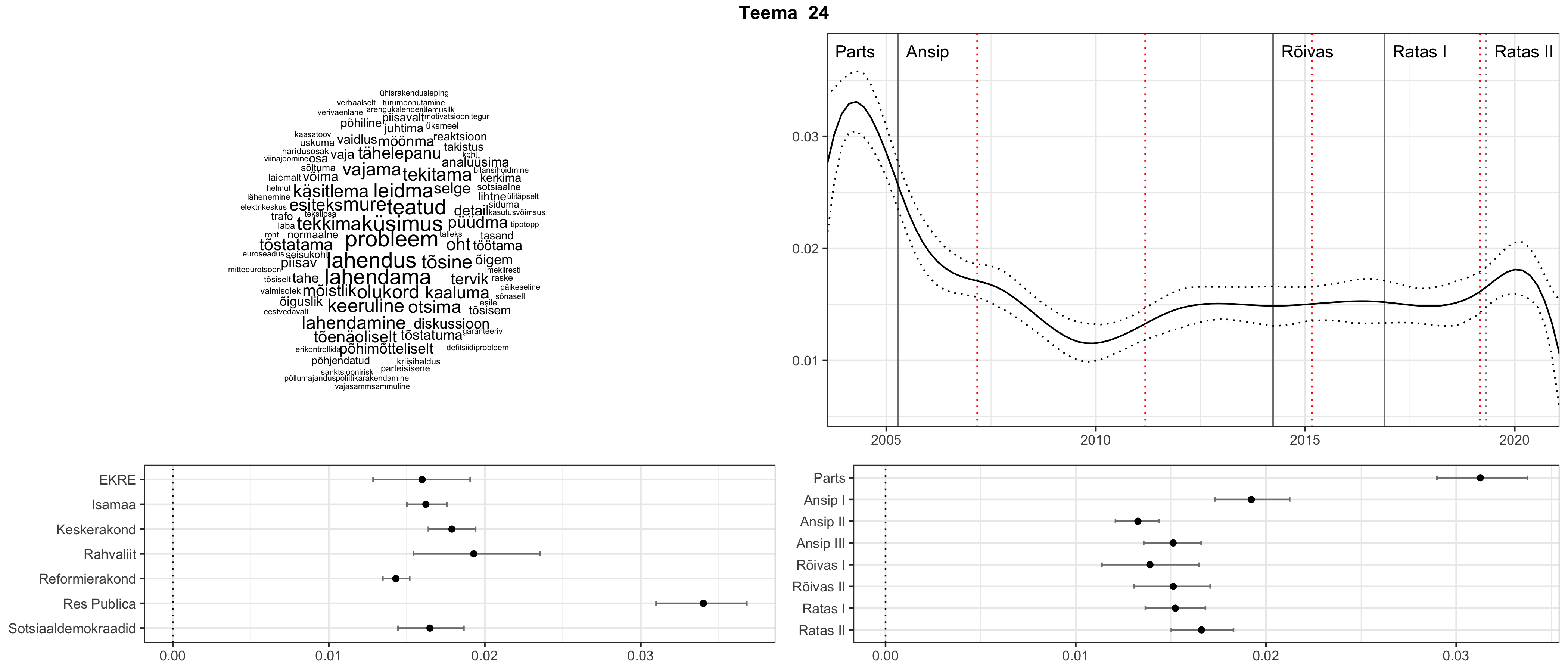
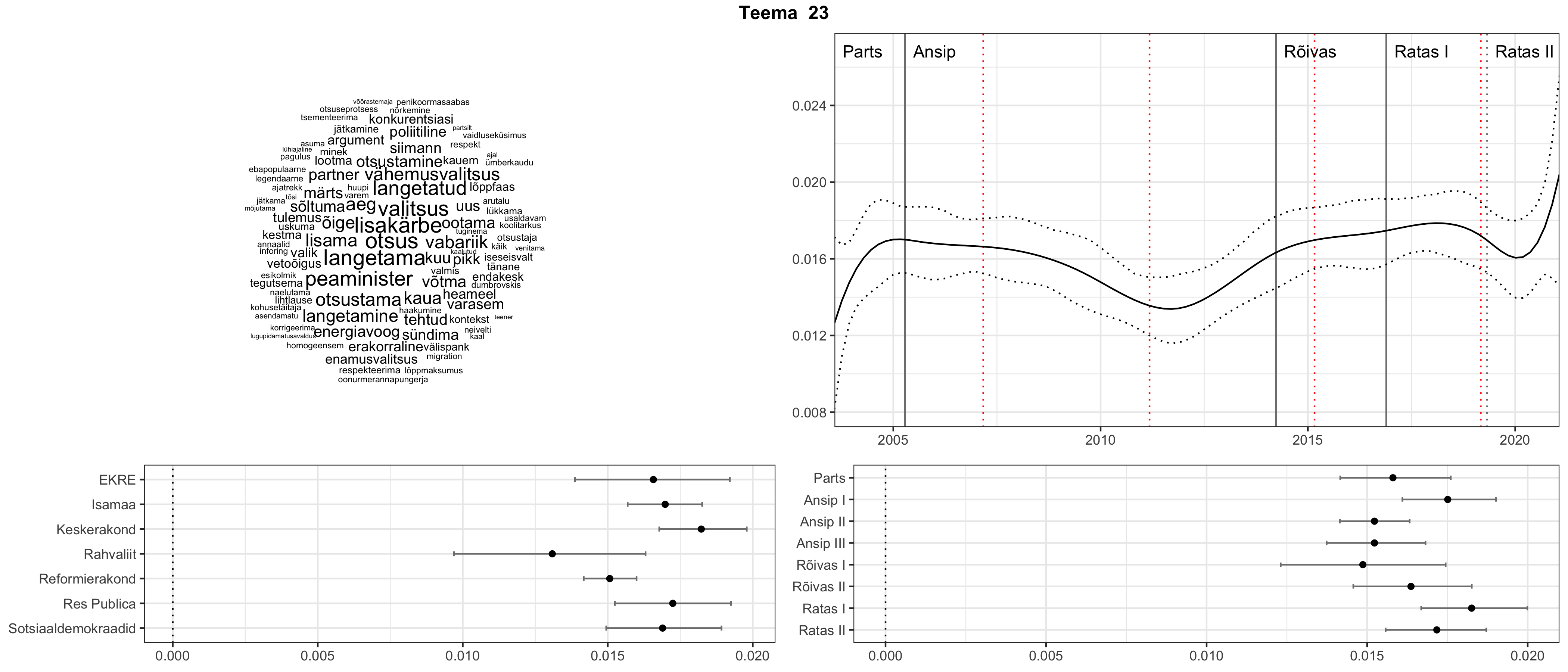
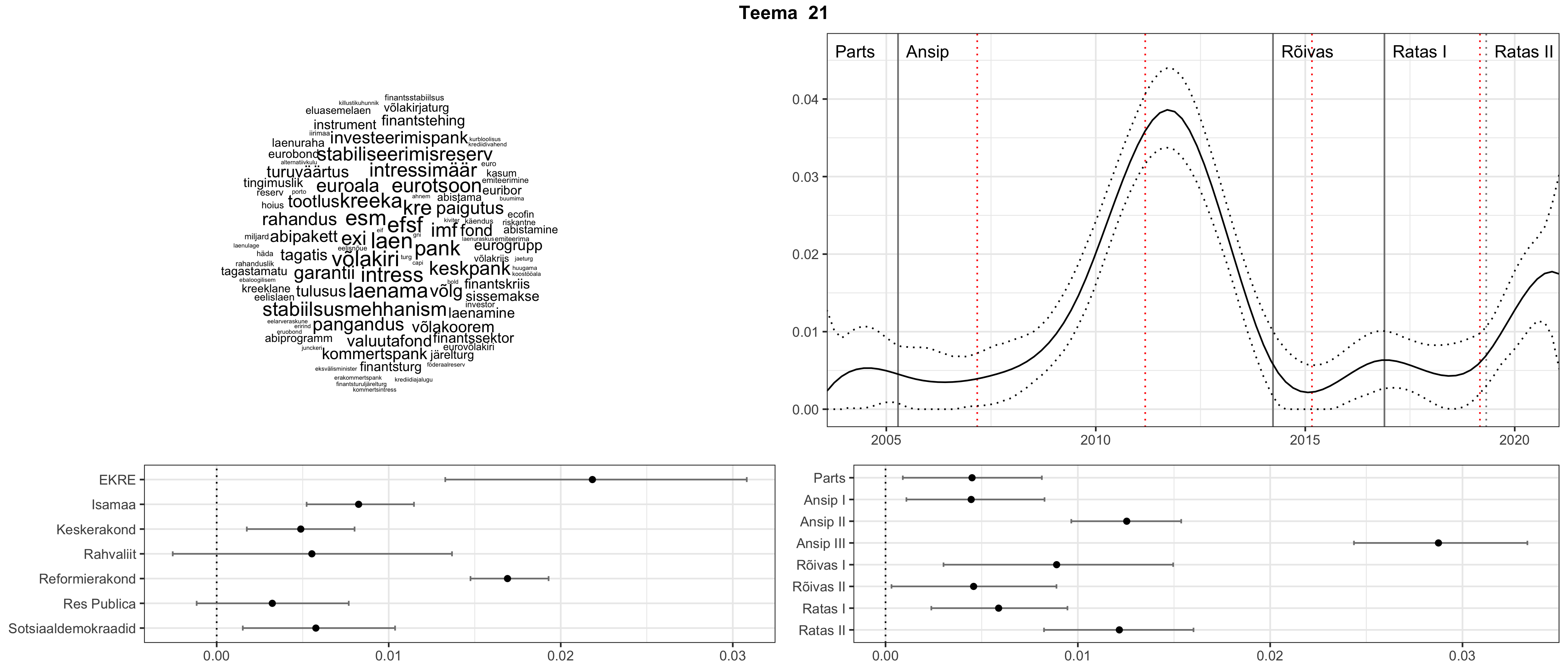
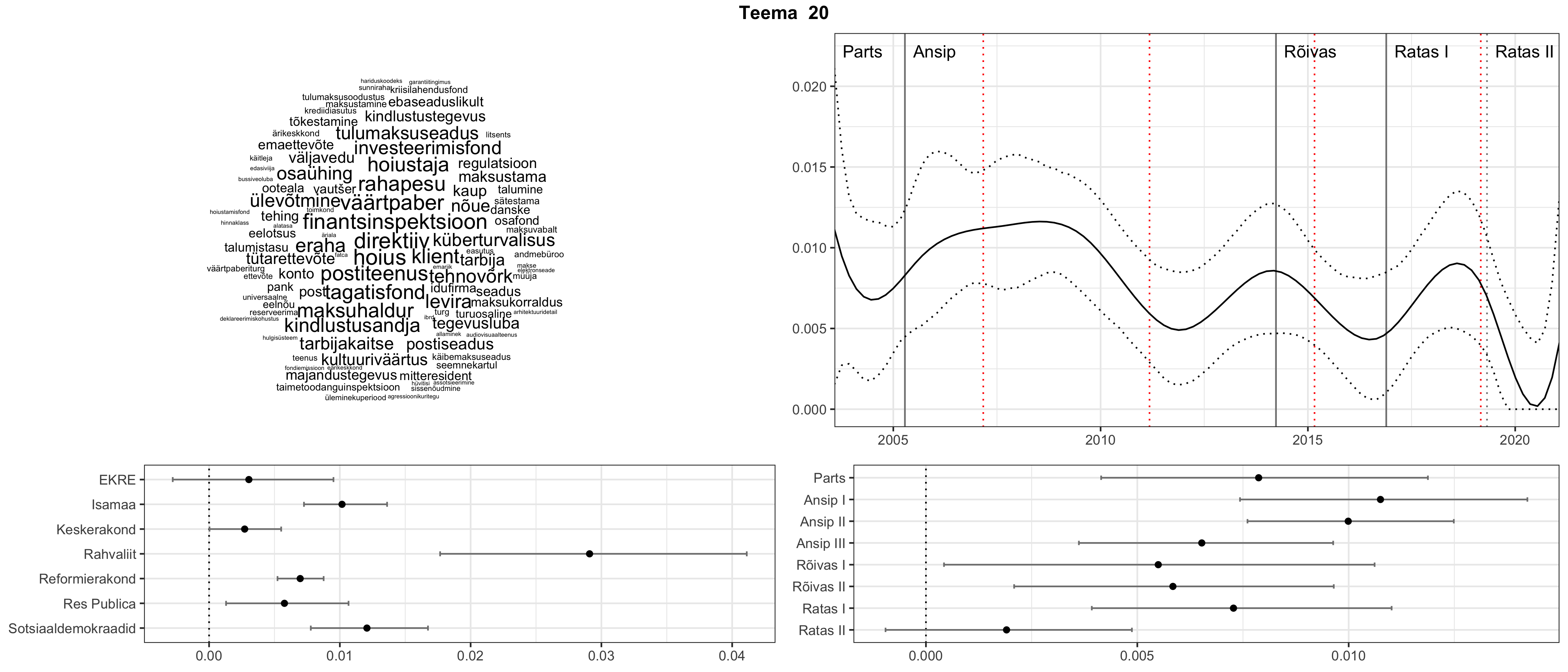
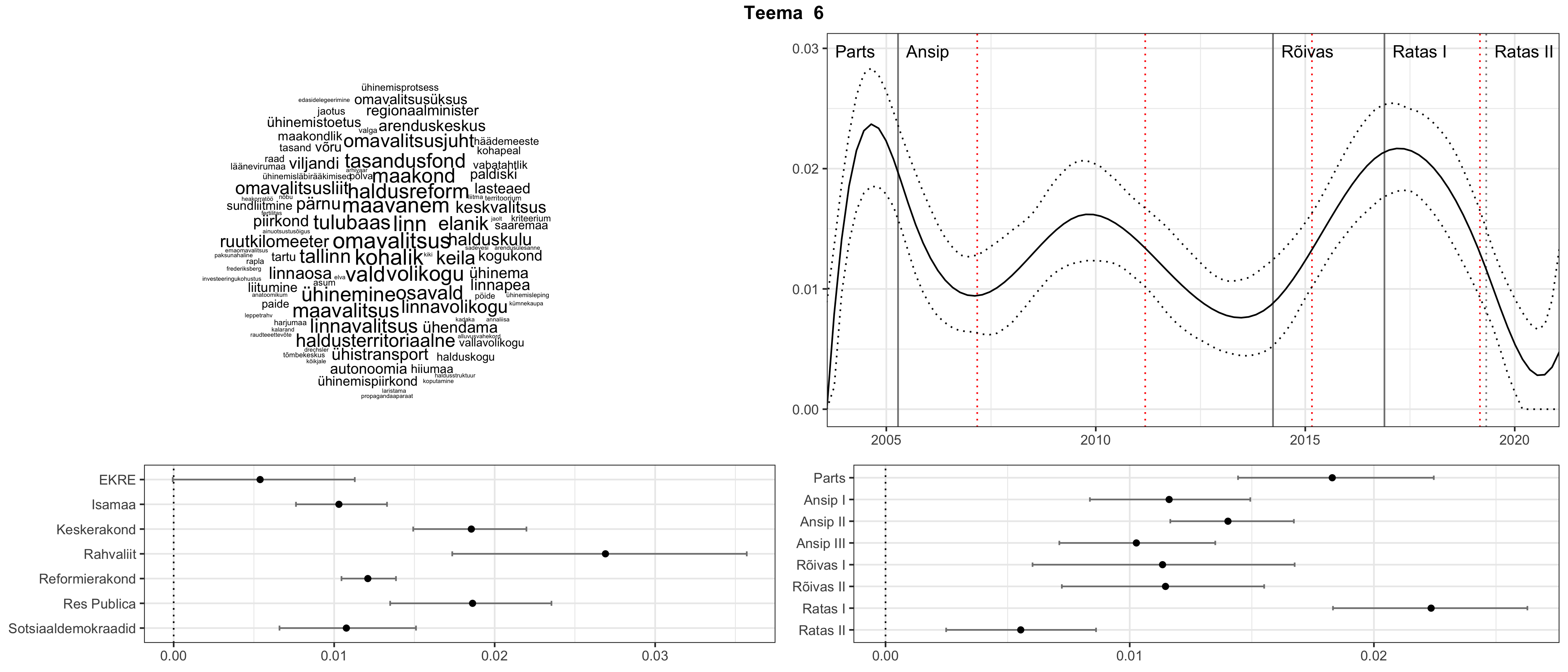
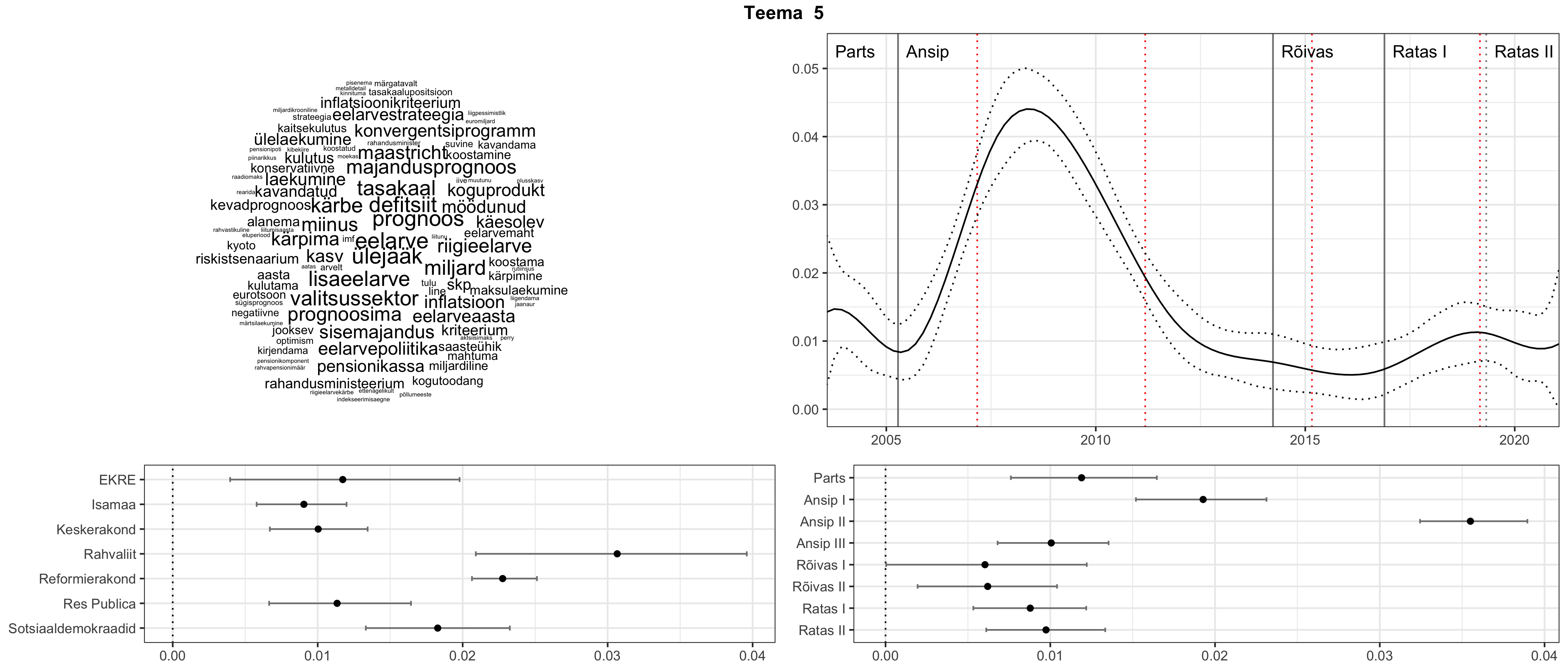
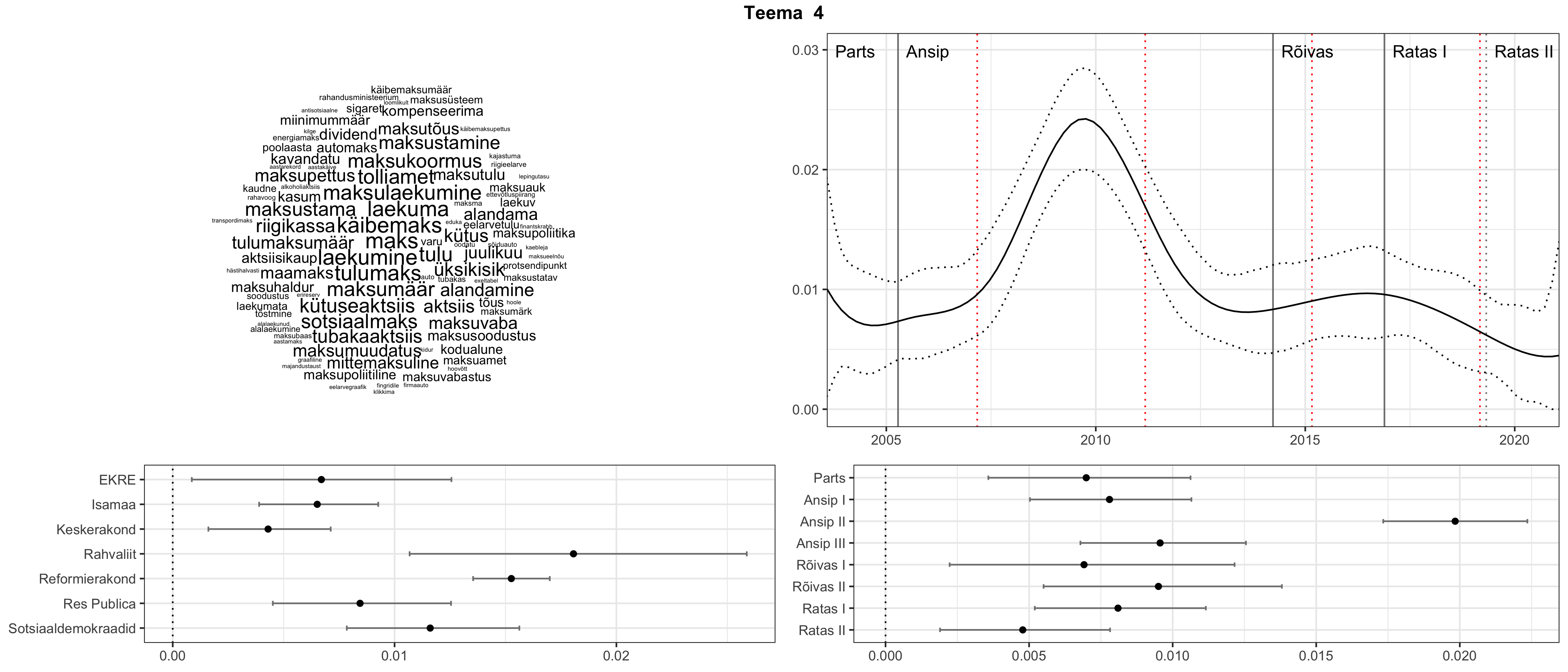
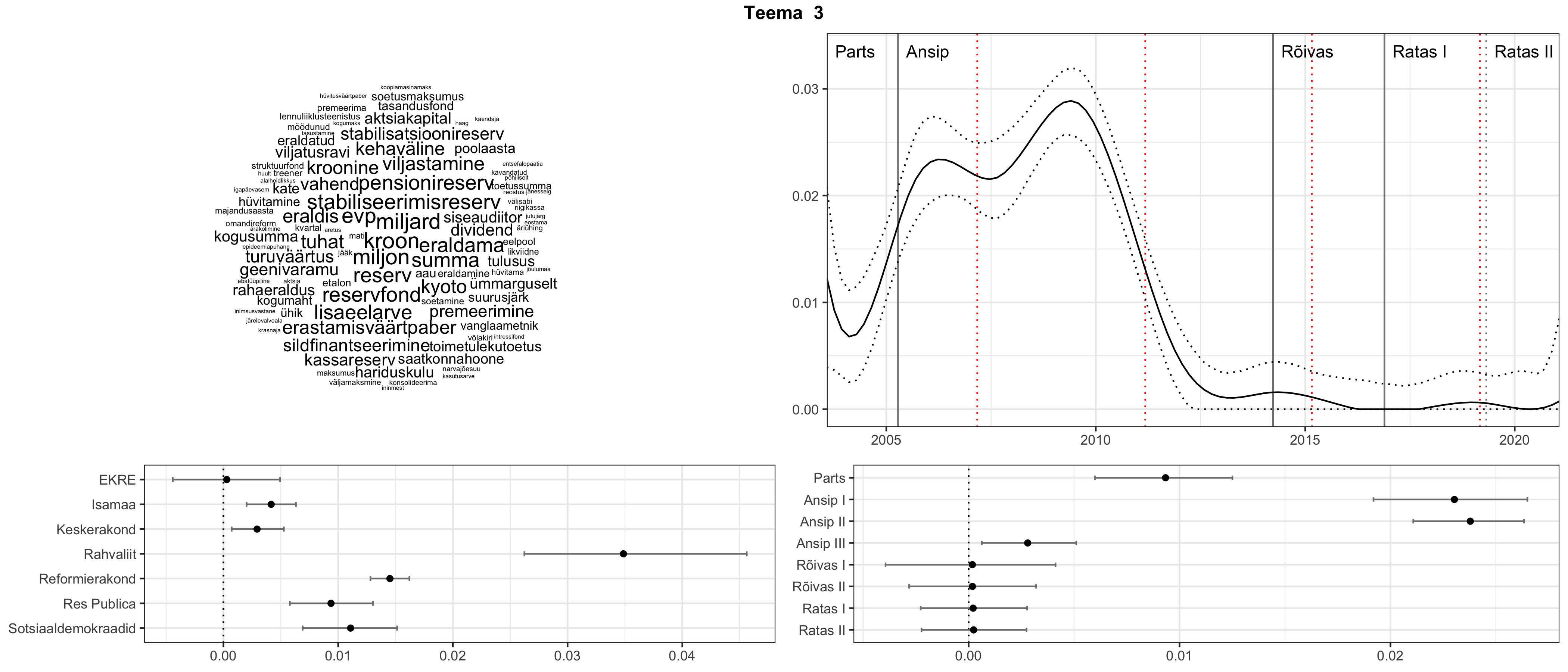
Iga teema on kuvatud joonisel, kus sõnapilv toob välja need sõnad, mis moodustavad teema. Mida suurem on sõna, seda olulisem ta teema jaoks on. Lisaks sellele on näidatud ka selle teema esinemissagedus sujuvalt läbi aja (üldistatud ajaline trend, mis toob mõned detailid ohvriks, et näidata üldist pilti) ning see, kuidas see teema erakondade või valitsuste lõikes esile kerkib.
See siin on kõige üldisem ja kõige vähem süstematiseeritud ülevaade sellest, kuidas tark masin võib kõik need stenogrammid kokku võtta. See on algus, alus konkreetsemate teemade ja nüansside analüüsiks.
Aga las need teemad kõnelevad enda eest ise. Varu nende vaatamiseks natuke aega, neid on oma jagu. Ning kuigi mõlemad mudelid peaksid täitma sama funktsiooni, teevad nad seda siiski märkimisväärselt erineval viisil ning tulemused on mõnevõrra erinevad. Nad ei räägi üksteisele vastu, kuid üks suudab näha asju, mida teine ei märka, ja vastupidi.
Top2vec mudeli poolt tuvastatud teemasid näed siit (klõpsa pildil, et näha suuremalt):




















































































































STM (strucutral topic model) mudeli poolt tuvastatud teemasid näed siit (klõpsa pildil, et näha suuremalt):

























































































































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}